


Betere bedrijfsresultaten door kunstmatige intelligentie op schaal te operationaliseren
Kunstmatige intelligentie (AI) zorgt voor een nieuwe norm voor bedrijven in verschillende sectoren. Retailers kunnen bijvoorbeeld AI gebruiken om inkooporders te voorspellen op basis van historische voorraadgegevens om intelligente beslissingen over herbevoorrading te stimuleren. Klantenondersteuningsteams kunnen AI gebruiken om automatisch te reageren op en om klantenondersteuningstickets met hoge prioriteit naar de juiste teams te sturen. Er is een wereld aan mogelijkheden waar u AI, en met name ML, kunt gebruiken om praktische bedrijfsresultaten te behalen.
Volgens Deloitte Insights zag 83% van de early adopters van enterprise AI een positief rendement op de investering (ROI) van projecten in productie. Deze omvatten voorbeelden zoals de implementatie van bedrijfssoftware van derden met behulp van AI, het gebruik van chatbots en virtuele assistenten en aanbevelingsengines voor e-commerceplatforms. Drieëntachtig procent van de ondervraagde bedrijven was van plan de uitgaven voor AI in 2019 te verhogen. Van de bedrijven die in AI investeerden, had 63% ML geadopteerd.
Het ontwikkelen van een strategie voor het pragmatisch gebruiken van AI en ML om bedrijfsdoelen te bereiken, is voor veel ondernemingen een topprioriteit. Voor velen is de belangrijkste uitdaging om ML succesvol te operationaliseren het begrijpen, plannen en uitvoeren van het beheer van een holistische ML-implementatie in de hele organisatie.
Belangrijkste overwegingen voor het operationaliseren van ML
De ‘juiste’ manier om de data science-levenscyclus aan te pakken, verschilt van organisatie tot organisatie. Er zijn veel pogingen gedaan om procedures voor de levenscyclus van datawetenschap te codificeren en te standaardiseren. Geen enkele benadering houdt echter rekening met de behoeften van elke onderneming.
Het omarmen van een duurzame en onderhoudbare strategie voor data en datawetenschap is een zich voortdurend ontwikkelende oefening die verschilt van elke onderneming. Omdat de behoeften, structuur en mogelijkheden van elk bedrijf uniek zijn, moeten belanghebbenden uit de hele onderneming worden geraadpleegd om een flexibel en schaalbaar ML-model te bouwen en een holistische datawetenschapsstrategie uit te voeren.
De operationele uitdagingen en veranderingen in infrastructuur en ontwikkelingspraktijken die elke onderneming moet aanpakken, zullen verschillen.
Het is van cruciaal belang dat uw organisatie rekening houdt met uw cultuur, systemen en behoeften bij het definiëren en ontwikkelen van de levenscyclus van datawetenschap. Het hebben van een basisraamwerk om aan alle teams te presenteren helpt bij het ontwikkelen van een gemeenschappelijke basis voor communicatie terwijl u uw operationalisering van ML blijft ontwikkelen en ontwikkelen.
Laten we een standaardraamwerk doornemen dat uw organisatie kan helpen aan de slag te gaan op haar ML-reis.
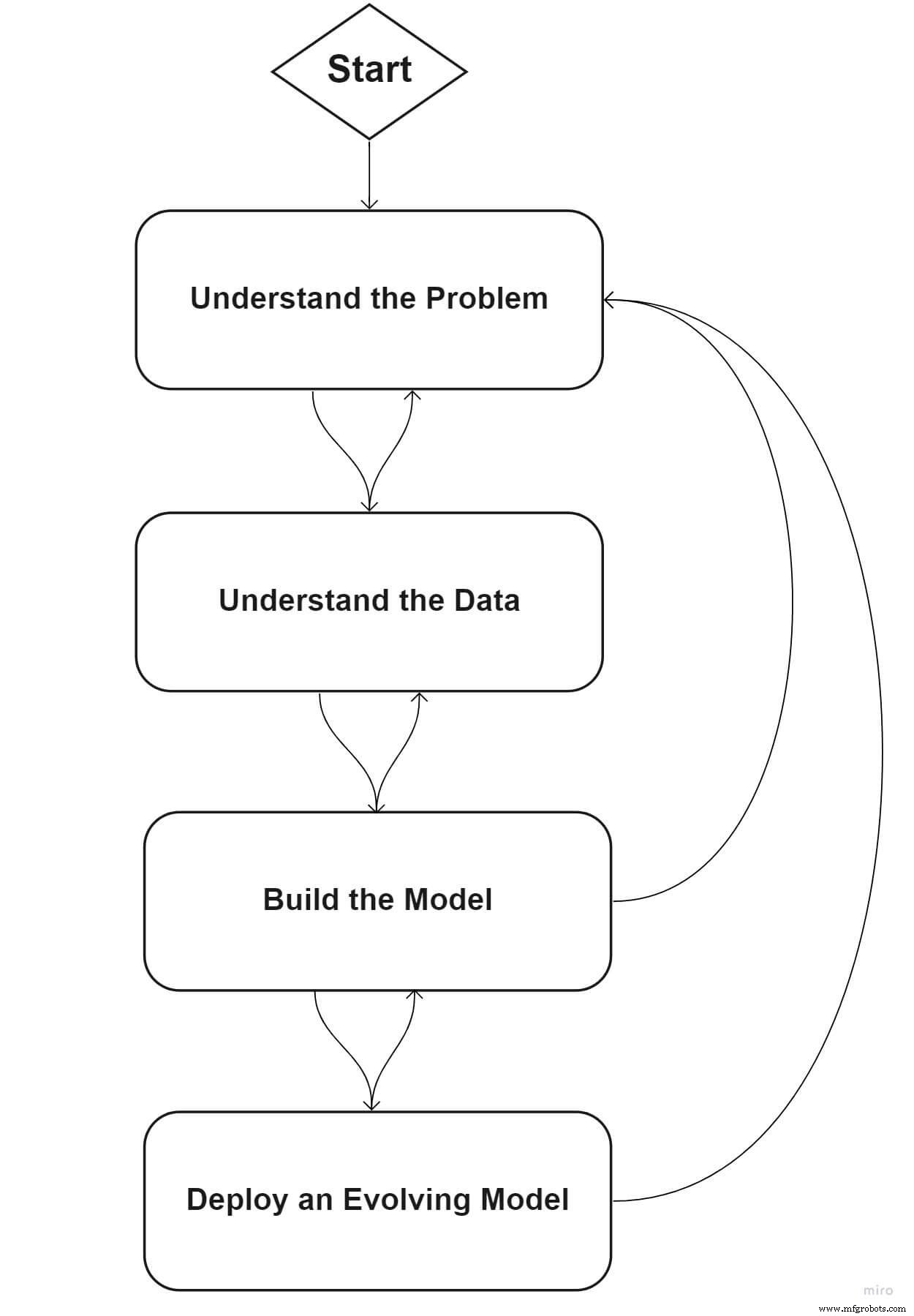
Fase één:definieer uw probleem
De kern van elk ML-initiatief zijn twee vragen:
1. Welk probleem probeer je op te lossen?
2. Waarom denkt u dat ML en een beter begrip van uw gegevens u kunnen helpen het probleem op te lossen?
De antwoorden op deze vragen hangen af van hoe uw bedrijf over strategie denkt en bedrijfsproblemen evalueert.
Tijdens de eerste fase moeten de belangrijkste belanghebbenden samenkomen om de initiële omvang van het probleem en de vereisten ervan te definiëren.
Fase twee:inzicht in uw gegevens
Wat is het verhaal van uw gegevens? Waar komen uw gegevens vandaan en hoeveel gegevensbronnen zijn relevant om u te helpen bij het oplossen van uw specifieke bedrijfsprobleem?
Tijdens deze fase richten ondernemingen zich op:
-
Relevante gegevensbronnen en de omgevingen waarin ze leven in kaart brengen (dergelijke omgevingen kunnen on-premises of in de cloud zijn, opgezet als een datawarehouse, datameer of streaming dataplatforms)
-
Definiëren welke datapijplijnen er momenteel zijn en welke datapijplijnen moeten worden gebouwd voor gegevensvalidatie, opschoning en verkenning
-
Begrijpen hoe vaak gegevens worden bijgewerkt
-
De betrouwbaarheid van de gegevens begrijpen
-
Overwegingen en vereisten voor gegevensprivacy evalueren
-
Gegevensverkenning mogelijk maken via visualisaties, statistische eigenschappen van onbewerkte en getransformeerde gegevens, enz.
Het begrijpen van uw gegevens is geen geringe taak. Het is belangrijk om deze fase iteratief te benaderen. Naarmate u meer over uw gegevens ontdekt, kunt u problemen ontdekken die van invloed zijn op uw vermogen om het probleem op te lossen, waardoor u het probleem mogelijk opnieuw moet definiëren of herschikken vanaf de eerste fase.
Fase drie:bouw het ML-model
Zodra u de gegevens gereed heeft, is het tijd voor uw gegevenswetenschappers om een ML-model te bouwen. Veelvoorkomende stappen om een robuust ML-model te bouwen zijn:
-
Extraheer- en engineeringfuncties (inclusief binning, data whitening en toepassen van statistische transformaties)
-
Functies selecteren
-
Het model trainen (inclusief het opsplitsen van de gegevens in een willekeurig aantal trainings-, kruisvalidatie- en validatiegegevenssets)
-
Hyperparameters afstemmen
-
Het model evalueren
-
Statistische significantie valideren
Het ontwikkelen van een model vereist voortdurende feedback van zakelijke belanghebbenden. Zo kan het bedrijfsprobleem vragen om affiniteit met sensitiviteit ten opzichte van specificiteit. Op dezelfde manier kunt u lichte voorspellende prestaties (bijv. F1-score) inruilen voor operationele modelprestaties (bijv. snellere voorspellingen) of de verklaarbaarheid van het model.
Het doel van de datawetenschapper is om een model te bouwen dat data gebruikt om een duidelijk verhaal te vertellen over het bedrijfsprobleem. Naarmate het probleem evolueert en de vereisten veranderen, moet de benadering van modellering ook evolueren om de huidige context te dienen.
Fase vier:een evoluerend model implementeren
Het bouwen van het eerste model is nog maar het begin van de ML-reis. Het implementeren van een evoluerend model is een cruciale stap naar waardecreatie op de lange termijn voor de organisatie.
Het implementeren van een evoluerend model vereist:
-
Het model bedienen (het model zeer beschikbaar en horizontaal schaalbaar maken)
-
Modelversies beheren (inclusief rollbacks en canary/challenger-implementaties)
-
Het model opnieuw trainen (aanpassen of bouwen van een nieuw model als er nieuwe gegevens in het systeem komen)
-
Monitoring van het model (volgen van zowel operationele als gebruikerservaringsstatistieken op serveer- en trainingstijden)
Het bewaken van gegevens en modelafwijkingen, waarvoor specialisatie van een model voor gerichte gebruikssituaties binnen organisaties nodig is, en het onderhouden van gegevenspijplijnen (naast andere onderhoudsitems) zijn van cruciaal belang voor het aanhoudende succes van een model.
Bedrijfsbrede en branchebrede vereisten kunnen snel evolueren en van invloed zijn op gegevensbronnen en inputs. Governance en compliance op grote schaal zijn bijvoorbeeld overwegingen die de volledige levenscyclus van datawetenschap overspannen.
Naleving van regelgeving, zoals de Algemene Verordening Gegevensbescherming (AVG) van de Europese Unie (EU) - vereist een dieper niveau van traceerbaarheid bij de gegevensversiebeheer, modelversiebeheer en modelinvoerlagen. Door een strategie te ontwikkelen om te reageren op deze veranderingen en vereisten in de sector door middel van gegevens, kunnen bedrijven ML blijven gebruiken om betere bedrijfsresultaten te behalen, zoals omzetgroei, kostenverlaging en verminderd risico.
Wat nu?
Om ML op een flexibele, onderhoudbare en schaalbare manier te operationaliseren, zijn veel stappen en overwegingen nodig die verder gaan dan het algemene bereik van wat we in deze blog hebben geschetst. De duivel zit in de details.
In onze volgende blog gaan we dieper in op technische overwegingen, uitdagingen die kunnen voortvloeien uit een ad-hocimplementatie van een grootschalig ML-systeem en hoe UiPath helpt bij het aanpakken van veelvoorkomende uitdagingen voor zakelijke klanten.
Automatisering Besturingssysteem
- Bosch voegt kunstmatige intelligentie toe aan industrie 4.0
- Is kunstmatige intelligentie fictie of rage?
- Zal kunstmatige intelligentie vroeg of laat een impact hebben op IoT?
- Waarom het internet der dingen kunstmatige intelligentie nodig heeft
- Hoe creëer je een succesvolle business intelligence-strategie
- Evolutie van testautomatisering met kunstmatige intelligentie
- Wat is bedrijfsintelligentie? En waarom moet ik dat weten?
- Industrial AIoT:combinatie van kunstmatige intelligentie en IoT voor industrie 4.0
- Kunstmatige Intelligentie Robots
- Voor- en nadelen van kunstmatige intelligentie
- Big data versus kunstmatige intelligentie