


Best practices voor het debuggen van op Zephyr gebaseerde IoT-applicaties
Het Linux Foundation Zephyr Open Source Project is uitgegroeid tot de ruggengraat van veel IoT-projecten. Zephyr biedt een best-in-class klein, schaalbaar, realtime besturingssysteem (RTOS) dat is geoptimaliseerd voor apparaten met beperkte middelen, over meerdere architecturen. Het project heeft momenteel 1.000 bijdragers en 50.000 commits die geavanceerde ondersteuning bouwen voor meerdere architecturen, waaronder ARC, Arm, Intel, Nios, RISC-V, SPARC en Tensilica, en meer dan 250 boards.
Bij het werken met Zephyr zijn er een paar kritische overwegingen om dingen verbonden te houden en betrouwbaar te laten functioneren. Ontwikkelaars kunnen niet alle soorten problemen aan hun bureau oplossen en sommige worden pas duidelijk wanneer een apparaatvloot groeit. Naarmate netwerken en netwerkstacks evolueren, moet u ervoor zorgen dat upgrades geen onnodige problemen veroorzaken.
Neem bijvoorbeeld een situatie waarin we werden geconfronteerd met GPS-trackers die werden ingezet om boerderijdieren te volgen. Het apparaat was een op sensoren gebaseerde halsband met een lage voetafdruk. Op een willekeurige dag zwierf het dier van mobiel netwerk naar mobiel netwerk; van land tot land; van locatie naar locatie. Een dergelijke beweging bracht snel verkeerde configuraties en onverwacht gedrag aan het licht die zouden kunnen leiden tot vermogensverlies, resulterend in grote economische verliezen. We hoefden niet alleen op de hoogte te zijn van een probleem, we moesten ook weten waarom het is gebeurd en hoe we het kunnen oplossen. Bij het werken met aangesloten apparaten zijn bewaking en foutopsporing op afstand van cruciaal belang om direct inzicht te krijgen in wat er mis is gegaan, de volgende beste stappen om de situatie aan te pakken en uiteindelijk hoe de normale werking tot stand kan worden gebracht en behouden.
We gebruiken een combinatie van Zephyr en het cloudgebaseerd apparaatwaarnemingsplatform Memfault om apparaatbewaking en -update te ondersteunen. In onze ervaring kunt u beide gebruiken om best practices voor bewaking op afstand vast te stellen met behulp van reboots, watchdogs, fout/beweringen en connectiviteitsstatistieken.
Een observatieplatform opzetten
Met Memfault kunnen ontwikkelaars firmware op afstand controleren, debuggen en bijwerken, wat ons in staat stelt om:
- voorkom dat de productie stilvalt ten gunste van een minimaal levensvatbaar product en Day-0-updates
- voortdurend de algehele apparaatstatus bewaken
- push updates en patches voordat de meeste eindgebruikers problemen opmerken
De SDK van Memfault kan eenvoudig worden geïntegreerd om gegevenspakketten te verzamelen voor cloudanalyse en deduplicatie van problemen. Het werkt als een typische Zephyr-module waar je het aan je manifestbestand toevoegt.
# west.yml [ ... ] - naam:memfault-firmware-sdk url:https://github.com/memfault/memfault-firmware-sdk pad:modules/memfault-firmware-sdk revisie:master # prj.conf CONFIG_MEMFAULT=j CONFIG_MEMFAULT_HTTP_ENABLE=j
Eerste aandachtsgebied:opnieuw opstarten
Stel dat u een aanzienlijke stijging van het aantal resets op uw apparaat ziet. Dit is vaak een vroege indicator dat er iets in de topologie is veranderd of dat apparaten problemen beginnen te ervaren als gevolg van hardwaredefecten. Het is het kleinste stukje informatie dat u kunt verzamelen om inzicht te krijgen in de gezondheid van uw apparaat, en het helpt om erover na te denken in twee delen:hardware-resets en software-resets.
Hardware-resets zijn vaak te wijten aan hardware-waakhonden en brownouts. Software-resets kunnen worden veroorzaakt door firmware-updates, beweringen of door de gebruiker geïnitieerd.
Nadat we hebben vastgesteld welke soorten resets plaatsvinden, kunnen we begrijpen of er problemen zijn die van invloed zijn op de hele vloot, of dat ze beperkt zijn tot een klein percentage van de apparaten.
Reden voor opnieuw opstarten vastleggen
ongeldig fw_update_finish(void) { // ... memfault_reboot_tracking_mark_reset_imminent(kMfltRebootReason_FirmwareUpdate, ...); sys_reboot(0); } Zephyr heeft een mechanisme voor het registreren van regio's die behouden blijven tijdens een reset waarop Memfault aansluit. Als u op het punt staat het platform opnieuw op te starten, raden we u aan op te slaan vlak voordat u begint. Wanneer u het platform opnieuw opstart, noteert u de reden voor het opnieuw opstarten - in dit geval een firmware-update - en noemt u het een Zephyr sys_reboot.
Apparaatresets vastleggen op Zephyr
Registreer init-handler om opstartinformatie te lezen
statisch int record_reboot_reason() { // 1. Lees het redenenregister voor hardware-reset. (Controleer MCU-gegevensblad voor registernaam) // 2. Reden voor softwarereset vastleggen vanuit noinit RAM // 3. Gegevens naar de server sturen voor aggregatie } SYS_INIT(record_reboot_reason, APPLICATION, CONFIG_KERNEL_INIT_PRIORITY_DEFAULT); U kunt een macro instellen die systeeminformatie vastlegt vóór resets via het MCU-resetredenregister. Wanneer het apparaat opnieuw wordt opgestart, zal Zephyr handlers registreren met behulp van system_int macro. MCU-resetredenregisters hebben allemaal iets andere namen en ze zijn allemaal handig omdat je kunt zien of er hardwareproblemen of defecten zijn.
Voorbeeld:probleem met voeding
Laten we eens kijken naar een voorbeeld van hoe monitoring op afstand essentieel inzicht kan geven in de gezondheid van het wagenpark door te kijken naar reboots en stroomvoorziening. Hier kunnen we zien dat een klein aantal apparaten verantwoordelijk is voor meer dan 12.000 herstarts (Figuur 1).
klik voor afbeelding op volledige grootte

Afbeelding 1:Voorbeeld van een probleem met de voeding, overzicht van herstart gedurende 15 dagen. (Bron:Auteurs)
- 12K-apparaat herstart per dag - veel te veel
- 99% van de herstarts bijgedragen door 10 apparaten
- Slecht mechanisch onderdeel dat bijdraagt aan het constant opnieuw opstarten van het apparaat
In dit geval starten sommige apparaten 1000 keer per dag opnieuw op, waarschijnlijk als gevolg van een mechanisch probleem (slecht onderdeel, slecht batterijcontact of verschillende chronische snelheidsproblemen).
Zodra apparaten in productie zijn, kunt u een aantal van deze problemen oplossen via firmware-updates. Door een update uit te rollen, kunt u hardwaredefecten omzeilen en de noodzaak omzeilen om apparaten te herstellen en te vervangen.
Tweede aandachtsgebied:waakhonden
Bij het werken met verbonden stacks is een waakhond de laatste verdedigingslinie om een systeem weer schoon te krijgen zonder het apparaat handmatig te resetten. Vastlopen kan om vele redenen gebeuren, zoals
- Connectiviteit Stack Blocks op send()
- Oneindige lussen opnieuw proberen
- Deadlocks tussen taken
- Corruptie
Hardware watchdogs zijn een speciaal randapparaat in de MCU dat periodiek moet worden "gevoed" om te voorkomen dat ze het apparaat resetten. Software-waakhonden zijn geïmplementeerd in de firmware en vuren voor de hardware-waakhond om het vastleggen van de systeemstatus mogelijk te maken die leidt tot de hardware-waakhond
Zephyr heeft een hardware watchdog API waar alle MCU's de generieke API kunnen doorlopen om de watchdog in het platform in te stellen en te configureren. (Zie Zephyr API voor meer details:zephyr/include/drivers/watchdog.h)
// ... nietig start_watchdog(void) { // raadpleeg de apparaatstructuur voor beschikbare hardware-waakhond s_wdt =device_get_binding(DT_LABEL(DT_INST(0, nordic_nrf_watchdog))); struct wdt_timeout_cfg wdt_config ={ /* Reset SoC wanneer de watchdog-timer verloopt. */ .flags =WDT_FLAG_RESET_SOC, /* Waakhond verlopen na max. venster */ .window.min =0U, .window.max =WDT_MAX_WINDOW, }; s_wdt_channel_id =wdt_install_timeout(s_wdt, &wdt_config); const uint8_t options =WDT_OPT_PAUSE_HALTED_BY_DBG; wdt_setup(s_wdt, opties); // TODO:Start een softwarewaakhond } nietig feed_watchdog(void) { wdt_feed(s_wdt, s_wdt_channel_id); // TODO:waakhond voor feedsoftware } Laten we een paar stappen doorlopen aan de hand van dit voorbeeld van de Nordic nRF9160.
- Ga naar de apparaatstructuur en stel de map Nordic nRF watchtime in.
- Stel de configuratie-opties voor de waakhond in via de blootgestelde API.
- Installeer de waakhond.
- Voed de waakhond regelmatig wanneer het gedrag naar verwachting verloopt. Soms gebeurt dit vanuit de taken met de laagste prioriteit. Als het systeem vastloopt, wordt het opnieuw opgestart.
Met Memfault op Zephyr kunt u gebruik maken van kerneltimers, aangedreven door een timer-randapparaat. U kunt de time-out van de software-waakhond zo instellen dat deze voorloopt op uw hardware-waakhond (stel bijvoorbeeld uw hardware-waakhond in op 60 seconden en uw software-waakhond op 50 seconden). Als de callback ooit wordt aangeroepen, wordt een bevestiging geactiveerd, die u door de Zephyr-foutafhandelaar leidt en informatie krijgt over wat er gebeurde op dat moment dat het systeem vastliep.
Voorbeeld:SPI-stuurprogramma zit vast
Laten we nog eens kijken naar een voorbeeld van een probleem dat niet in ontwikkeling is gevangen, maar zich in het veld voordoet. In figuur 2 kun je timing, de feiten en de degradatie in SPI-stuurprogrammachips zien.
klik voor afbeelding op volledige grootte
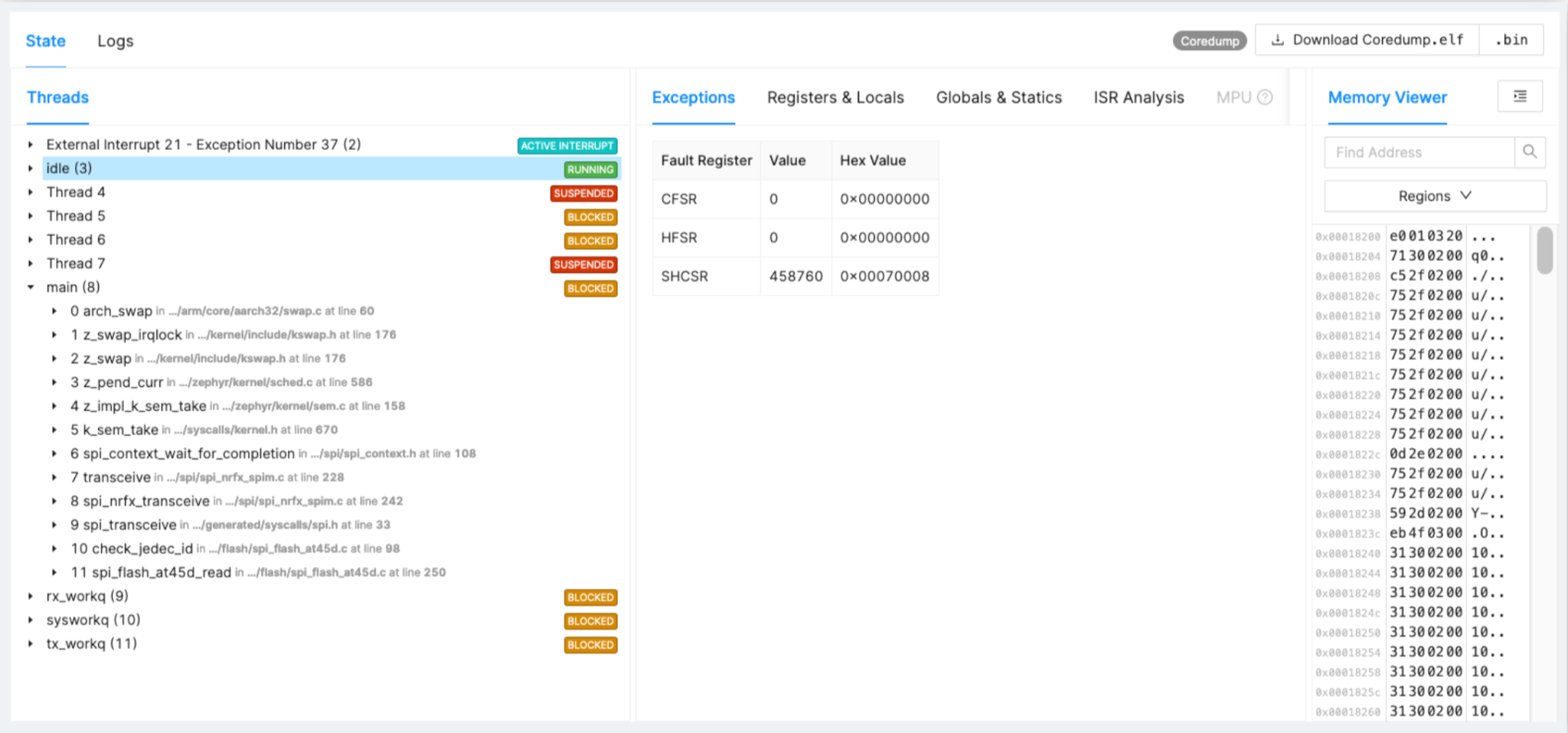
Figuur 2:Voorbeeld SPI-stuurprogramma vastgelopen. (Bron:Auteurs)
- SPI-flitser verslechtert na verloop van tijd, onjuiste timing van communicatie
- Dit op 1% van de apparaten getraceerd na 16 maanden inzet in het veld
- Driver fix en uitrol met volgende release
Voor Flash kun je na een jaar in het veld zien dat er een plotselinge start is van fouten als gevolg van vastlopen in SPI-transacties of verschillende stukjes en beetjes code. Als je het hele spoor hebt, kun je de oorzaak vinden en een oplossing ontwikkelen.
De waakhond hieronder (Figuur 3) schopt de Zephyr-foutafhandelaar uit.
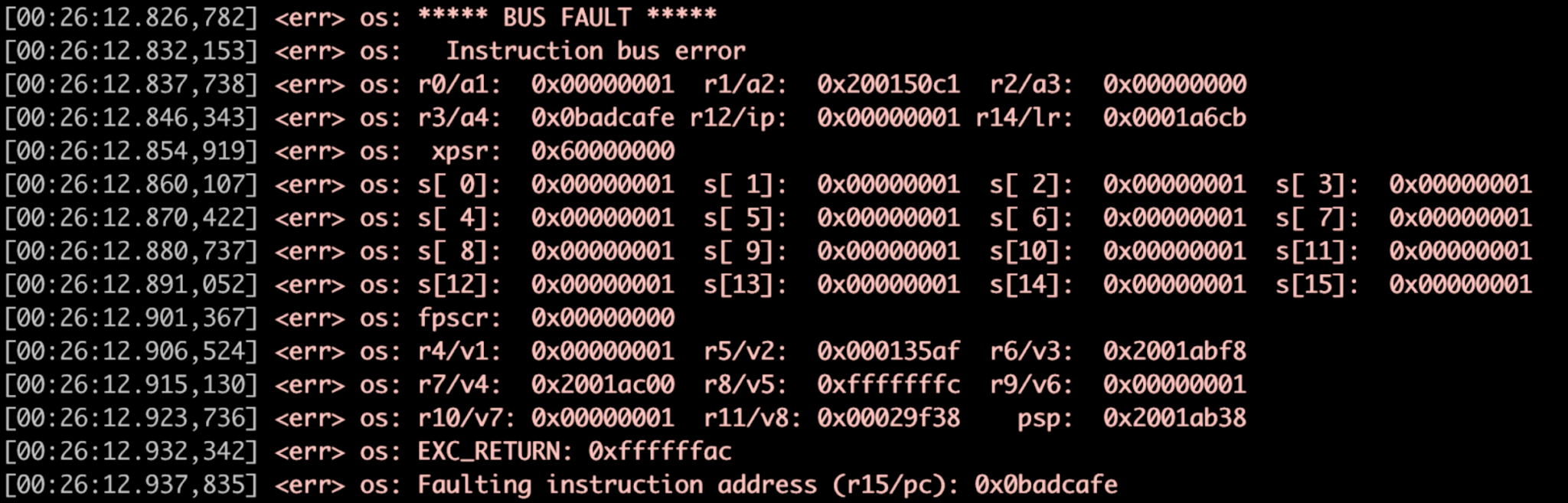
Figuur 3:Voorbeeld storingsafhandelaar, dump registreren. (Bron:Auteurs)
Derde aandachtsgebied:fouten/beweringen:
Het derde onderdeel dat moet worden gevolgd, zijn fouten en beweringen. Als je ooit een lokale debug hebt gedaan of zelf een aantal functies hebt gebouwd, heb je waarschijnlijk een soortgelijk scherm gezien over de registerstatus wanneer er een fout is opgetreden op het platform. Deze kunnen te wijten zijn aan:
- beweert, of
- toegang tot slecht geheugen
- delen door nul
- een randapparaat op de verkeerde manier gebruiken
Hier is een voorbeeld van een foutafhandelingsstroom die is uitgevoerd op Cortex M-microcontrollers op Zephyr.
ongeldig network_send(void) { const size_t packet_size =1500; void *buffer =z_malloc(packet_size); // ontbrekende NULL-controle! memcpy(buffer, 0x0, pakketgrootte); // ... } ↓nietig network_send(void) { const size_t packet_size =1500; void *buffer =z_malloc(packet_size); // ontbrekende NULL-controle! memcpy(buffer, 0x0, pakketgrootte); // ... } ↓boe memfault_coredump_save(const sMemfaultCoredumpSaveInfo *save_info) { // Registerstatus opslaan // Bewaar _kernel en taakcontexten // Bewaar geselecteerde .bss &.data regio's } ↓nietig sys_arch_reboot(int type) { // ... } Wanneer een assert of een fout begint, wordt een interrupt geactiveerd en wordt een foutafhandelaar in Zephyr aangeroepen die de registerstatus op het moment van de crash levert.
De Memfault SDK wordt automatisch geïntegreerd in de foutafhandelingsstroom en slaat kritieke informatie op in de cloud, inclusief de registerstatus, de status van de kernel en een deel van alle taken die op het systeem werden uitgevoerd op het moment van de crash.
Er zijn drie dingen waar u op moet letten wanneer u lokaal of op afstand debugt:
- Het Cortex M-foutstatusregister vertelt u waarom het platform beweerde of een fout maakte.
- Memfault herstelt de exacte regel code die het systeem gebruikte voor de crash, en de status van alle andere taken.
- Verzamel de _kernel structuur in de Zephyr RTOS om de planner te zien, en als het een verbonden applicatie is, de status van de Bluetooth- of LTE-parameters.
Vierde aandachtsgebied:trackingstatistieken voor apparaatwaarneming
Door statistieken bij te houden, kunt u beginnen met het opbouwen van een patroon van wat er op uw systeem gebeurt en kunt u vergelijkingen maken tussen uw apparaten en uw vloot om te begrijpen welke veranderingen een impact hebben.
Een paar statistieken die handig zijn om bij te houden zijn:
- CPU-gebruik
- verbindingsparameters
- warmteverbruik
Met de Memfault SDK kunt u met twee regels code metrische gegevens toevoegen aan en beginnen met het definiëren van Zephyr:
- Metriek definiëren
MEMFAULT_METRICS_KEY_DEFINE( LteDisconnect, kMemfaultMetricType_Unsigned)
- Statistiek in code bijwerken
ongeldig lte_disconnect(void) { memfault_metrics_heartbeat_add( MEMFAULT_METRICS_KEY(LteDisconnect), 1); //... } Memfault SDK + Cloud
- Serialiseert en comprimeert statistieken voor transport
- Indexstatistieken per apparaat en firmwareversie
- Maakt webinterface zichtbaar voor browsestatistieken per apparaat en in alle vloot
Er kunnen tientallen statistieken worden verzameld en geïndexeerd per apparaat en firmwareversie. Een paar voorbeelden:
- NB-IoT/LTE-M basisconnectiviteit: Bekijk hoe een modem de levensduur van de batterij beïnvloedt, hetzij door verbonden te zijn, hetzij door verbinding te maken.
- Basisstations en PSM volgen in NB-IoT/LTE-M: De kwaliteit van het mobiele signaal kan pijnlijk zijn en de levensduur van de batterij verkorten als deze niet wordt beheerd. Maak statistieken voor netwerkstatus, gebeurtenissen, informatie over zendmasten, instellingen, timers en meer. Controleer op wijzigingen en gebruik waarschuwingen.
- Grote vloten testen: Onverwacht grote hoeveelheden data kunnen de verbindingskosten van apparaten verhogen en uitbijters helpen identificeren.
Voorbeeld:NB-IoT/LTE-M gegevensgrootte
klik voor afbeelding op volledige grootte
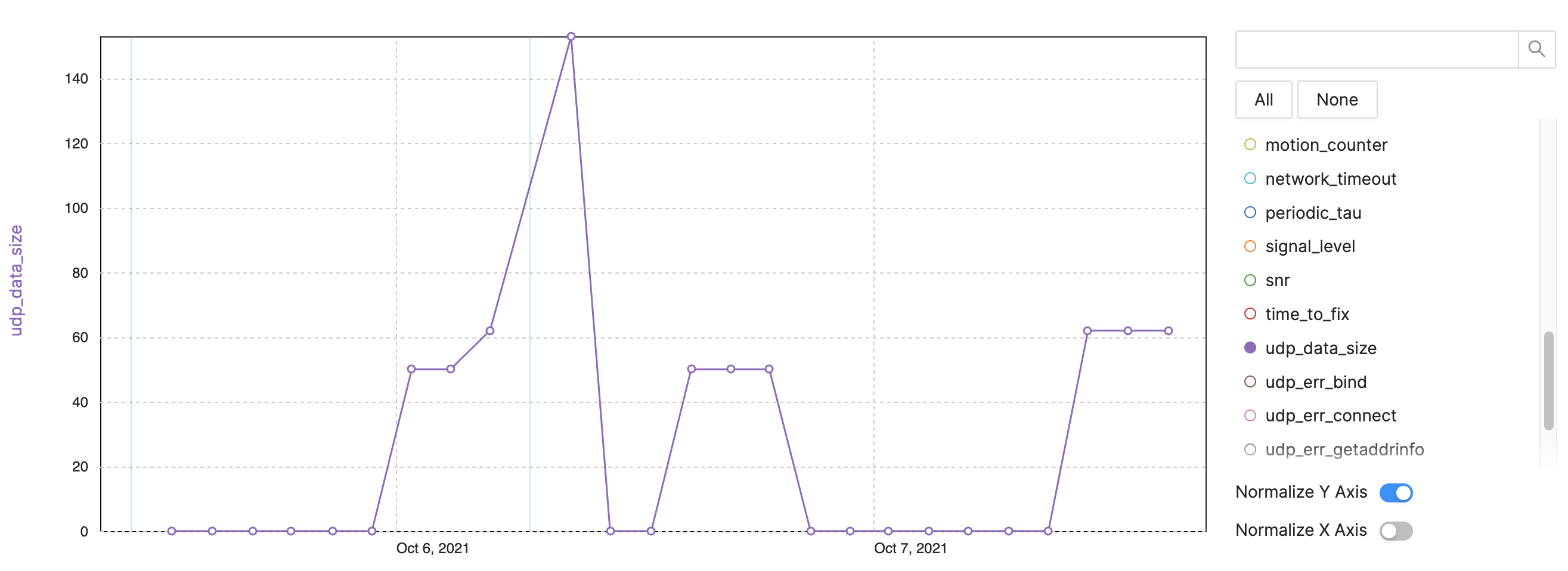
Figuur 4:Trackingstatistieken voor apparaatwaarneming - NB-IoT-voorbeeld, LTE-M-gegevensgrootte. (Bron:Auteurs)
- UDP-gegevensgrootte:Track bytes per verzendinterval (Figuur 4)
- Na opnieuw opstarten worden meer gegevens verzonden
- Sommige pakketten zijn groter vanwege meer info of sporen
- Volg het probleem van het dataverbruik
Conclusie
Door gebruik te maken van Zephyr en Memfault kunnen ontwikkelaars bewaking op afstand implementeren om de functionaliteit van verbonden apparaten beter te observeren. Door te focussen op reboots, watchdogs, fout/beweringen en connectiviteitsstatistieken, kunnen ontwikkelaars de kosten en prestaties van IoT-systemen optimaliseren.
Leer meer door een opgenomen presentatie van de Zephyr Developer Summit 2021 te bekijken.
Internet of Things-technologie
- Best practices voor synthetische monitoring
- Beste beveiligingspraktijken voor mistcomputers
- 1G bidirectionele transceivers voor serviceproviders en IoT-toepassingen
- ETSI zet stappen om normen te stellen voor IoT-toepassingen in noodcommunicatie
- IIC en TIoTA werken samen aan IoT/Blockchain Best Practices
- NIST publiceert concept-beveiligingsaanbevelingen voor IoT-fabrikanten
- Partnerschap streeft naar eindeloze batterijduur van IoT-apparaten
- 3 beste redenen om IoT-technologie te gebruiken voor activabeheer
- Waarom zou u IoT als het beste platform voor milieumonitoring beschouwen?
- Beste toepassingen voor persluchtsystemen
- Best practices voor productiemarketing voor 2019