


Uw investeringen in betrouwbaarheid rationaliseren
Wat zijn de werkelijke kosten van een storing? Helaas weten we dit pas nadat de storing is opgetreden - en betrouwbaarheid gaat over het voorkomen van de storing. Dus hier is ons dilemma:hoeveel is een niet-evenement waard? De technische wereld van fabricagebetrouwbaarheid zit vol met zeer competente en goed opgeleide mensen die gewend zijn hun wereld te definiëren in parametrische en deterministische termen.
Om vertrouwd te raken met het proces van het voorspellen van de toekomst onder de huidige omstandigheden en vervolgens veranderingen te rechtvaardigen om een nieuwe en meer winstgevende toekomst te creëren, moeten professionals op het gebied van productiebetrouwbaarheid vertrouwd raken met het proces van het definiëren van hun wereld in probabilistische en niet-parametrische termen.
We weten twee dingen:elk productieproces zal mislukken en het falen zal enige impact hebben op de organisatie. Evenzo zijn er twee dingen die we niet weten:wanneer het proces zal mislukken en de ernst van de impact op de organisatie.
In mijn ervaring hebben betrouwbaarheidsprofessionals de neiging om naar een van de twee uitersten te gaan bij het definiëren van de impact van een storing. Enerzijds claimt de conservatieve betrouwbaarheidsingenieur alleen de vermeden kosten voor onderdelen, ervan uitgaande dat de arbeidskosten zijn gedaald; er zijn geen kosten voor uitvaltijd omdat we er niet van kunnen uitgaan dat de productiecapaciteit van de fabriek is uitverkocht; en we kunnen geen op risico gebaseerde kosten aannemen, zoals persoonlijk letsel, impact op het milieu, enz. Aan de andere kant beweren overijverige betrouwbaarheidsingenieurs dat als ze de mogelijke lagerstoring niet hadden ontdekt en gepland voor reparatie, de pomp zou hebben mislukte, veroorzaakte een totaal verlies van uitverkochte productie en leidde tot een brand die de fabriek opblies, iedereen doodde, een grote ecologische afvalzone creëerde en ervoor zorgde dat de aarde niet langer om haar as draaide! Ik maak een grapje, maar het punt is dat de waarheid ergens tussenin ligt.
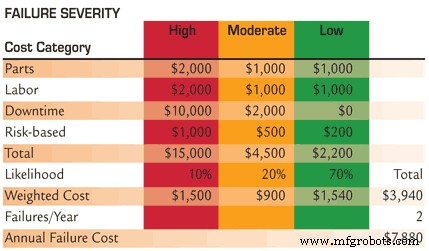
Figuur 1. De werkelijke faalkosten kunnen pas achteraf deterministisch worden geschat. Voor planningsdoeleinden moet een probabilistische benadering worden gebruikt.
In de kern is betrouwbaarheid verwant aan risicobeheer. Risicomanagers bekijken de wereld op een probabilistische, niet-parametrische manier, omdat dat de enige redelijke manier is om te proberen de toekomst te voorspellen. Aan de hand van een hoofdstuk uit risicobeheer 101 en verschillende bijbehorende normen met betrekking tot het onderwerp, heb ik een model gemaakt om voor u te illustreren hoe u de kosten van een functioneel falen van een productieproces kunt inschatten. Dit model wordt geïllustreerd in figuur 1. Hier vindt u stapsgewijze instructies voor het maken en gebruiken van voor risico gecorrigeerde faalkostenmodellen.
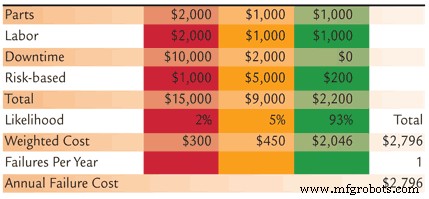
Figuur 2. Geschatte jaarlijkse faalkosten na implementatie van monitoring, planning en betrouwbaarheidsverbeteringen
1) Maak op ernst gebaseerde kostenramingen: Zoals figuur 1 illustreert, brengt elke functionele storing kosten met zich mee. Deze kunnen onderdelen, arbeid, uitvaltijd, op risico's gebaseerde kosten, enz. omvatten. De sleutel is om kostenmodellen op basis van de ernst van fouten te creëren. Een zeer ernstige gebeurtenis kan ertoe leiden dat u aanzienlijke downtime-kosten en/of bijkomende kosten maakt, terwijl matige en kleine gebeurtenissen een kleinere impact op de organisatie hebben. In mijn voorbeeldmodel kost een zeer ernstige storing $ 15.000 per gebeurtenis, een matige storing kost $ 4.500 en een lage ernstige storing $ 2.200. Dit wil niet zeggen dat elk evenement dat als matig wordt beoordeeld, precies $ 4.500 kost (vergeet niet dat we onze niet-parametrische denkcaps aan hebben); dit is een gewogen gemiddelde binnen die categorie van de ernst van de storing.
Ik heb gekozen voor drie ernstclassificaties, wat mijn typische benadering is in het werken met klanten. U kunt zoveel categorieën aanmaken als u wilt. Er is echter een afnemend marginaal nut voor elke extra categorie. Ik stel ook voor dat u de verleiding weerstaat om de arbeidskosten te verlagen op basis van de logica dat ze verzonken zijn. De waarheid is dat arbeid variabele kosten zijn. Als productieprocessen meer geautomatiseerd en betrouwbaarder worden, hebben we simpelweg minder mensen nodig om ze te bedienen en te onderhouden, punt uit.
2) Maak wegingsfactoren voor waarschijnlijkheid: In mijn voorbeeld ben ik ervan uitgegaan dat 10 procent van mijn faalgebeurtenissen van hoge ernst zijn, 20 procent van matige ernst en 70 procent van lage ernst. Vermenigvuldig de totale faalkosten voor elke ernstcategorie met de bijbehorende waarschijnlijkheidsschatting en tel de producten bij elkaar op om de gewogen gemiddelde totale kosten voor een faalgebeurtenis te produceren. In mijn voorbeeld dragen evenementen met een hoge ernst $ 1.500 bij aan het gewogen gemiddelde, terwijl evenementen met een gemiddelde en lage ernst respectievelijk $ 900 en $ 1.540 bijdragen, voor een totaal van $ 3.940 per evenement. Suggereert dit dat onze volgende mislukking precies $ 3.940 zal kosten? Natuurlijk niet. Nogmaals, we denken probabilistisch en niet-parametrisch.
3) Schat het aantal evenementen per jaar: In de financiële wereld is de kosten-batenanalyse gebaseerd op geannualiseerde kosten en baten. We moeten dus inschatten hoeveel faalgebeurtenissen van dit type we in een jaar kunnen verwachten. In mijn voorbeeld verwachten we twee evenementen per jaar. Onze geschatte gemiddelde jaarlijkse faalkosten voor deze functionele faalmodus zijn dus $ 7.880. Alle risicobeperkende maatregelen die u neemt, zullen ofwel de ernstverdeling beïnvloeden en/of het aantal storingsgebeurtenissen per jaar verminderen (waardoor de gemiddelde tijd tussen storing [MTBF] of gemiddelde tijd tot storing [MTTF]) wordt vergroot.
4) De kansverdeling wijzigen: Over het algemeen hebben planningstools de neiging om de kansverdeling te wijzigen. Beschermende monitoring, inspecties en voorspellende monitoring helpen ons bijvoorbeeld om problemen in hun beginstadium op te sporen, voordat ze de kans krijgen om te escaleren tot ernstige of catastrofale niveaus. Evenzo zorgen effectieve processen voor planning, planning en werkbeheer ervoor dat de gedetecteerde problemen worden aangepakt. Deze maatregelen hebben geen invloed op het basisfalenpercentage, maar hebben wel een invloed op de waarschijnlijkheidsverdeling, waardoor de kans kleiner wordt dat een gebeurtenis van hoge ernst zal zijn, terwijl de kans groter wordt dat het een gebeurtenis van lage ernst zal zijn.
In ons voorbeeld, als we ons vermogen om storingen te detecteren en te beheren verbeteren, schatten we dat de kans op een zeer ernstige gebeurtenis van 10 procent naar 2 procent afneemt, de kans op een matige ernstige gebeurtenis van 20 procent naar 5 procent, terwijl de kans op een gebeurtenis met een lage ernst toeneemt van 70 procent naar 93 procent. Door de ernstwaarschijnlijkheid opnieuw te verdelen, worden de geschatte gewogen gemiddelde kosten per gebeurtenis verlaagd van $ 3.940 naar $ 2.796 (Figuur 2).
5) Het uitvalpercentage wijzigen: Proactieve maatregelen daarentegen beïnvloeden de betrouwbaarheid van het fabricageproces, waardoor het faalpercentage afneemt. Proactieve conditiecontrole en -bewaking om de smering, contaminatiecontrole, balans en uitlijning te verbeteren, evenals nauwkeurige bediening en onderhoudsacties op basis van gedocumenteerde standaard operationele procedures (SOP's) en standaard onderhoudsprocedures (SMP's) verminderen de snelheid waarmee storingen optreden. In ons voorbeeld schatten we dat we van twee storingen per jaar kunnen terugbrengen naar één. Ervan uitgaande dat we de kosten per gebeurtenis verlagen door ons vermogen om problemen op te sporen en te beheren in combinatie met onze initiatieven voor verbetering van de betrouwbaarheid, verwachten we onze jaarlijkse faalkosten te verlagen van $ 7.880 naar $ 2.796 (figuren 1 en 2).
In ons voorbeeld levert het verbeteren van ons vermogen om storingen op te sporen en te beheren een nettovoordeel op van $ 1.144 per jaar voor de gespecificeerde functionele storingsmodi. Gecombineerd met onze initiatieven om de betrouwbaarheid te verbeteren, is de nettowinst $ 5.084. Zolang de investeringen in betrouwbaarheid die nodig zijn om de veranderingen door te voeren een passend rendement opleveren voor de organisatie, moeten de initiatieven worden uitgevoerd.
In deze kolom hebben we modellen voor risicobeheer aangenomen om ons te helpen de kosten van een functionele storingsmodus te kwantificeren. In toekomstige uitgaven duiken we in het gebied van besluitvorming onder onzekerheid om modellen te bespreken voor het maken van schattingen wanneer er weinig empirische gegevens beschikbaar zijn. betrouwbaarheidsverbeteringsprojecten in een vorm die uw goedkeuringsclassificatie drastisch zal verbeteren.
Onderhoud en reparatie van apparatuur
- Wat uw IoT-bedrijfscase mogelijk mist
- FRACAS:hoe je apparatuurstoringen tot je vriend kunt maken
- Run to failure:maak het onderdeel van uw onderhoudsplanning
- Uw onderhoudskosten zijn te hoog!
- Betrouwbaarheid van de machine verwachten, maar mislukking belonen
- Kies uw distributeurs verstandig om de betrouwbaarheid te maximaliseren
- Frietfabrikant ziet kostenbesparingen, verhoogde betrouwbaarheid
- Uw investeringen maximaliseren door beveiligingsautomatisering
- 4 redenen waarom uw CMMS-implementatie een mislukking zal zijn
- 7 manieren om uw PCB-kosten te verlagen
- Hoe u de kosten van perslucht in uw faciliteit kunt bepalen?