


ETSI-rapport maakt de weg vrij voor standaardisatie van AI-beveiliging
Een nieuw rapport van ETSI, de Europese normalisatieorganisatie voor telecom-, omroep- en elektronische communicatienetwerken en -diensten, wil de weg vrijmaken voor het vaststellen van een standaard voor kunstmatige intelligentie (AI)-beveiliging.
De eerste stap op weg naar het creëren van een standaard is het beschrijven van het probleem van het beveiligen van op AI gebaseerde systemen en oplossingen. Dit is wat het 24-pagina's tellende rapport, ETSI GR SAI 004, doet, het eerste dat is gepubliceerd door de ETSI Securing Artificial Intelligence Industry Specification Group (SAI ISG). Het definieert de probleemstelling en heeft een bijzondere focus op machine learning (ML) en de uitdagingen met betrekking tot vertrouwelijkheid, integriteit en beschikbaarheid in elke fase van de levenscyclus van machine learning. Het wijst ook op enkele van de bredere uitdagingen van AI-systemen, waaronder vooringenomenheid, ethiek en uitlegbaarheid. Er worden een aantal verschillende aanvalsvectoren geschetst, evenals verschillende gevallen van gebruik en aanvallen in de echte wereld.
Om de problemen te identificeren die betrokken zijn bij het beveiligen van AI, was de eerste stap het definiëren van AI. Voor de ETSI-groep is kunstmatige intelligentie het vermogen van een systeem om representaties te verwerken, zowel expliciete als impliciete, en procedures om taken uit te voeren die als intelligent zouden worden beschouwd als ze door een mens zouden worden uitgevoerd. Deze definitie vertegenwoordigt nog steeds een breed spectrum aan mogelijkheden. Een beperkt aantal technologieën wordt nu echter haalbaar, grotendeels gedreven door de evolutie van machine learning en deep-learningtechnieken, en de brede beschikbaarheid van de gegevens en verwerkingskracht die nodig zijn om dergelijke technologieën te trainen en te implementeren.
Talloze benaderingen van machine learning worden algemeen gebruikt, waaronder gesuperviseerd, niet-gesuperviseerd, semi-gesuperviseerd en versterkend leren.
- Gesuperviseerd leren - waarbij alle trainingsgegevens worden gelabeld en het model kan worden getraind om de output te voorspellen op basis van een nieuwe set invoer.
- Semi-gesuperviseerd leren - waarbij de dataset gedeeltelijk is gelabeld. In dit geval kunnen zelfs de niet-gelabelde gegevens worden gebruikt om de kwaliteit van het model te verbeteren.
- Onbewaakt leren - waarbij de dataset niet-gelabeld is en het model zoekt naar structuur in de data, inclusief groepering en clustering.
- Reinforcement learning - waarbij een beleid dat bepaalt hoe te handelen wordt geleerd door agenten door ervaring om hun beloning te maximaliseren; en agenten doen ervaring op door interactie in een omgeving door middel van toestandsovergangen.
Binnen deze paradigma's kan een verscheidenheid aan modelstructuren worden gebruikt, waarbij een van de meest voorkomende benaderingen het gebruik van diepe neurale netwerken is, waarbij leren wordt uitgevoerd over een reeks hiërarchische lagen die het gedrag van het menselijk brein nabootsen.
Verschillende trainingstechnieken kunnen ook worden gebruikt, namelijk adversarial leren, waarbij de trainingsset niet alleen voorbeelden bevat die de gewenste resultaten weerspiegelen, maar ook adversariële voorbeelden, die bedoeld zijn om het verwachte gedrag uit te dagen of te verstoren.
“Er zijn veel discussies over AI-ethiek, maar geen over normen rond het beveiligen van AI. Toch worden ze cruciaal om de beveiliging van op AI gebaseerde geautomatiseerde netwerken te waarborgen. Dit eerste ETSI-rapport is bedoeld om een uitgebreide definitie te geven van de uitdagingen waarmee AI wordt geconfronteerd. Tegelijkertijd werken we aan een ontologie van dreigingen, hoe we een AI-dataleveringsketen kunnen beveiligen en testen”, legt Alex Leadbeater, voorzitter van ETSI SAI ISG, uit.
Gevraagd naar tijdlijnen, vertelde Leadbeater aan embedded.com:"Nog 12 maanden is een redelijke schatting voor technische specificaties. De komende kwartalen komen er meer technische rapporten (AI Threat Ontology, Data Supply Chain Report, SAI Mitigation Strategy-rapport). In feite zou één specificatie over beveiligingstests van AI vóór het einde van het tweede kwartaal van het derde kwartaal moeten verschijnen. De volgende stappen zijn het identificeren van specifieke gebieden in de probleemstelling die kunnen worden uitgebreid tot meer gedetailleerde informatieve werkitems.”
Rapportoverzicht
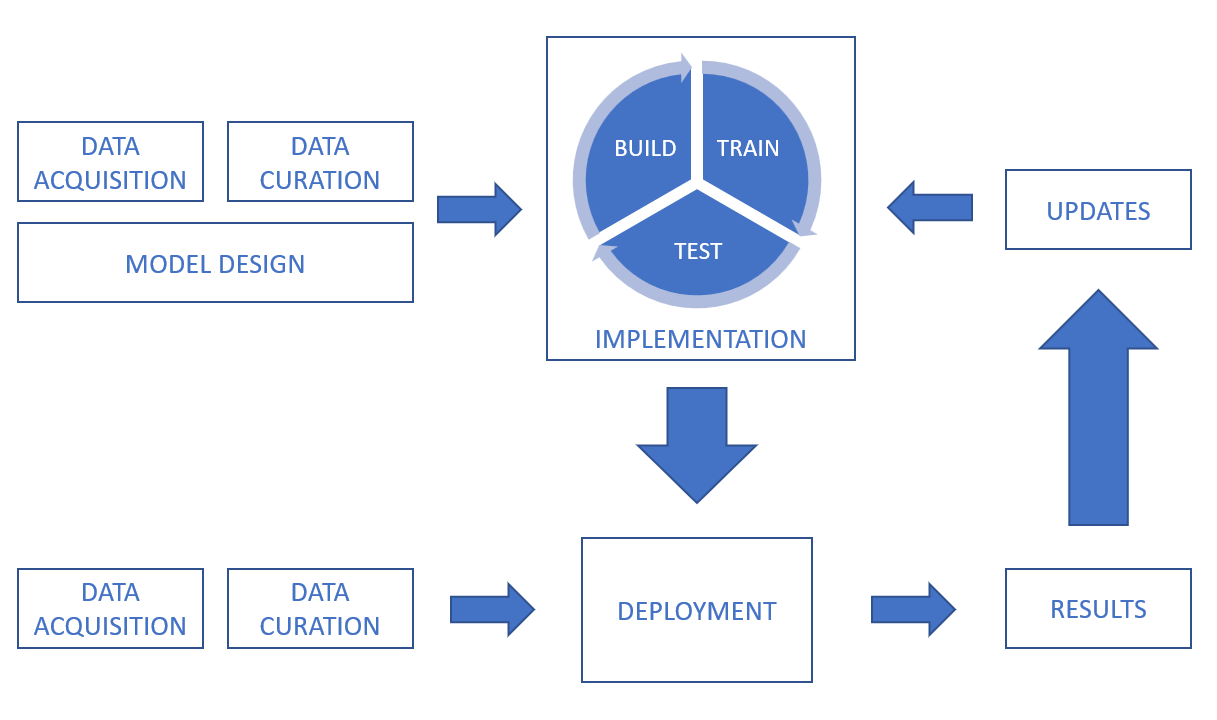
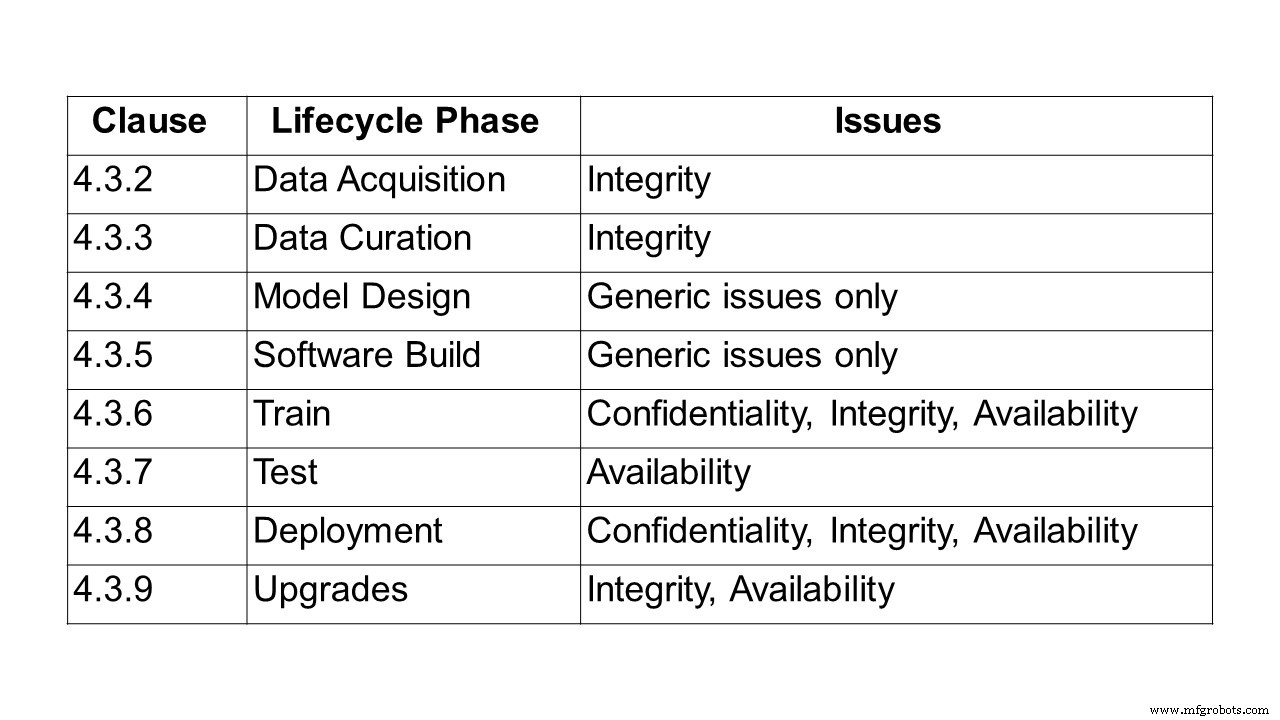
Na de definitie van AI en machine learning, kijkt het rapport vervolgens naar de gegevensverwerkingsketen, waarbij uitdagingen op het gebied van vertrouwelijkheid, integriteit en beschikbaarheid gedurende de hele levenscyclus worden behandeld, van gegevensverwerving, gegevensbeheer, modelontwerp en softwareontwikkeling tot training, testen, implementatie en gevolgtrekking en upgrades.
In een AI-systeem kunnen gegevens worden verkregen uit een groot aantal bronnen, waaronder sensoren (zoals CCTV-camera's, mobiele telefoons, medische apparaten) en digitale activa (zoals gegevens van handelsplatforms, documentuittreksels, logbestanden). Gegevens kunnen ook veel verschillende vormen hebben (waaronder tekst, afbeeldingen, video en audio) en kunnen gestructureerd of ongestructureerd zijn. Naast beveiligingsuitdagingen met betrekking tot de gegevens zelf, is het belangrijk om rekening te houden met de beveiliging van verzending en opslag.
Om een indicatie te geven van de integriteitsuitdagingen bij datacuratie, is het bij het repareren, aanvullen of converteren van datasets belangrijk ervoor te zorgen dat de processen geen risico lopen dat de kwaliteit en integriteit van de data wordt aangetast. Voor gesuperviseerde machine learning-systemen is het belangrijk dat de gegevenslabeling nauwkeurig en zo volledig mogelijk is, en ervoor te zorgen dat de labeling zijn integriteit behoudt en niet wordt aangetast, bijvoorbeeld door vergiftigingsaanvallen. Het is ook belangrijk om de uitdaging aan te gaan om ervoor te zorgen dat de dataset onbevooroordeeld is. Technieken voor gegevensvergroting kunnen van invloed zijn op de integriteit van de gegevens.
Een ander gebied dat wordt behandeld, betreft ontwerpuitdagingen, andere onbedoelde factoren rond vooringenomenheid, gegevensethiek en verklaarbaarheid.
Zo moet er niet alleen rekening worden gehouden met vooringenomenheid tijdens de ontwerp- en opleidingsfase, maar ook nadat een systeem is geïmplementeerd, omdat er nog steeds sprake kan zijn van vooringenomenheid. Het rapport haalt een voorbeeld aan uit 2016, toen een chatbot werd gelanceerd, die bedoeld was als experiment in ‘conversational understanding’. De chatbot zou via tweets en directe berichten in contact komen met gebruikers van sociale netwerken. Binnen een paar uur begon de chatbot zeer beledigende berichten te tweeten. Nadat de chatbot was ingetrokken, werd ontdekt dat het account van de chatbot was gemanipuleerd om bevooroordeeld gedrag te vertonen door internettrollen. Bias vertegenwoordigt niet noodzakelijk een beveiligingsprobleem, maar kan er eenvoudig toe leiden dat het systeem niet aan zijn functionele vereisten voldoet.
Op het gebied van ethiek belicht het rapport verschillende voorbeelden, waaronder zelfrijdende auto's en gezondheidszorg. Het citeert een paper van de Universiteit van Brighton waarin een hypothetisch scenario werd besproken waarin een auto aangedreven door AI een voetganger aanrijdt en de juridische verplichtingen die daaruit voortvloeien, onderzocht. In maart 2018 werd dit scenario werkelijkheid toen een zelfrijdende auto een voetganger aanreed en doodde in de stad Tempe, Arizona. Dit bracht niet alleen de wettelijke verplichtingen scherp in beeld, maar ook de potentiële ethische uitdagingen van het besluitvormingsproces zelf. In 2016 lanceerde het Massachusetts Institute of Technology (MIT) een website genaamd Moral Machine die de uitdagingen onderzoekt om intelligente systemen beslissingen te laten nemen die van ethische aard zijn. De site probeert te onderzoeken hoe mensen zich gedragen wanneer ze worden geconfronteerd met ethische dilemma's, en om een beter begrip te krijgen van hoe machines zich zouden moeten gedragen.
Het rapport benadrukt dat ethische zorgen weliswaar geen directe invloed hebben op de traditionele beveiligingskenmerken van vertrouwelijkheid, integriteit en beschikbaarheid, maar een aanzienlijk effect kunnen hebben op de perceptie van een persoon of een systeem kan worden vertrouwd. Het is daarom van essentieel belang dat ontwerpers en uitvoerders van AI-systemen rekening houden met de ethische uitdagingen en proberen robuuste ethische systemen te creëren die vertrouwen kunnen wekken bij gebruikers.
Ten slotte kijkt het rapport naar soorten aanvallen, van vergiftiging en achterdeuraanvallen tot reverse engineering, gevolgd door praktijkgevallen en aanvallen.
Bij een vergiftigingsaanval probeert een aanvaller het AI-model te compromitteren, normaal gesproken tijdens de trainingsfase, zodat het ingezette model zich gedraagt op een manier die de aanvaller wenst. Dit kan komen doordat het model faalt op basis van bepaalde taken of invoer, of dat het model een reeks gedragingen leert die wenselijk zijn voor de aanvaller, maar niet bedoeld zijn door de modelontwerper. Vergiftigingsaanvallen kunnen doorgaans op drie manieren plaatsvinden:
- Gegevensvergiftiging – waarbij de aanvaller tijdens de dataverzamelings- of datacuratiefasen onjuiste of onjuist geëtiketteerde gegevens in de dataset invoert.
- Algoritmevergiftiging – wanneer een aanvaller de voor het leerproces gebruikte algoritmen verstoort. Federaal leren omvat bijvoorbeeld het trainen van individuele modellen op subsets van gegevens en het vervolgens combineren van de geleerde modellen om het uiteindelijke model te vormen. Dit betekent dat de individuele datasets privé blijven, maar een inherente kwetsbaarheid creëren. Aangezien elke individuele dataset door een aanvaller kan worden beheerd, kunnen ze dat deel van het leermodel rechtstreeks manipuleren en het algemene leren van het systeem beïnvloeden.
- Modelvergiftiging – wanneer het gehele ingezette model simpelweg wordt vervangen door een alternatief model. Dit type aanval is vergelijkbaar met een traditionele cyberaanval waarbij de elektronische bestanden waaruit het model bestaat, kunnen worden gewijzigd of vervangen.
Hoewel de term 'kunstmatige intelligentie' zijn oorsprong vond op een conferentie in de jaren vijftig aan het Dartmouth College in Hanover, New Hampshire, VS, laten de gevallen van gebruik in de praktijk die in het ETSI-rapport worden beschreven, zien hoeveel het sindsdien is geëvolueerd. Dergelijke gevallen zijn onder meer adblocker-aanvallen, verduistering van malware, deepfakes, reproductie van handschrift, menselijke stem en nepgesprekken (die al veel reacties hebben opgeleverd bij chatbots).
Wat nu? Lopende rapporten als onderdeel van deze ISG
Deze groep voor branchespecificaties (ISG) bekijkt verschillende lopende rapporten, aangezien een deel van de werkitems eronder dieper zal ingaan.
Beveiligingstesten :Het doel van dit werk is het identificeren van doelstellingen, methoden en technieken die geschikt zijn voor het testen van de beveiliging van op AI gebaseerde componenten. Het algemene doel is om richtlijnen te hebben voor het testen van de beveiliging van AI en AI-gebaseerde componenten, rekening houdend met de verschillende algoritmen van symbolische en subsymbolische AI en het aanpakken van relevante bedreigingen uit het werkitem "AI-dreigingsontologie". Beveiligingstests van AI hebben enkele overeenkomsten met beveiligingstests van traditionele systemen, maar bieden nieuwe uitdagingen en vereisen verschillende benaderingen vanwege
(a) significante verschillen tussen symbolische en subsymbolische AI en traditionele systemen die grote gevolgen hebben voor hun beveiliging en voor het testen van hun beveiligingseigenschappen;
(b) non-determinisme aangezien op AI gebaseerde systemen in de loop van de tijd kunnen evolueren (zelflerende systemen) en beveiligingseigenschappen kunnen verslechteren;
(c) test-orakelprobleem, het toekennen van een testoordeel is anders en moeilijker voor op AI gebaseerde systemen omdat niet alle verwachte resultaten a priori bekend zijn, en (d) datagedreven algoritmen:in tegenstelling tot traditionele systemen, (trainings)data vormt het gedrag van subsymbolische AI.
De reikwijdte van dit werkitem over beveiligingstests omvat de volgende onderwerpen (maar niet beperkt tot):
- benaderingen voor beveiligingstests voor AI
- gegevens testen voor AI vanuit veiligheidsoogpunt
- beveiligingstest-orakels voor AI
- definitie van testtoereikendheidscriteria voor beveiligingstests van AI
- doelen testen voor beveiligingskenmerken van AI
En het biedt richtlijnen voor het testen van de beveiliging van AI, rekening houdend met de bovengenoemde onderwerpen. De richtlijnen zullen de resultaten van het werkitem "AI Threat Ontology" gebruiken om relevante bedreigingen voor AI te dekken door middel van beveiligingstests en zullen ook uitdagingen en beperkingen aanpakken bij het testen van op AI-gebaseerd systeem.
AI-bedreigingsontologie :Het doel van dit werkitem is om te definiëren wat als een AI-bedreiging wordt beschouwd en hoe dit kan verschillen van bedreigingen voor traditionele systemen. Het uitgangspunt dat de grondgedachte voor dit werk biedt, is dat er momenteel geen algemeen begrip is van wat een aanval op AI is en hoe deze kan worden gecreëerd, gehost en verspreid. Het werkitem "AI-dreigingsontologie" zal trachten de terminologie af te stemmen op de verschillende belanghebbenden en meerdere industrieën. Dit document definieert wat wordt bedoeld met deze termen in de context van cyber- en fysieke beveiliging en met een begeleidend verhaal dat gemakkelijk toegankelijk moet zijn voor zowel experts als minder goed geïnformeerd publiek in de verschillende sectoren. Merk op dat deze dreigingsontologie AI zal aanspreken als systeem, een vijandige aanvaller en als systeemverdediger.
Rapport gegevensleveringsketen :Data is een cruciaal onderdeel bij de ontwikkeling van AI-systemen. Dit omvat zowel onbewerkte gegevens als informatie en feedback van andere systemen en mensen in de lus, die allemaal kunnen worden gebruikt om de functie van het systeem te veranderen door de AI te trainen en opnieuw te trainen. De toegang tot geschikte gegevens is echter vaak beperkt, waardoor een beroep moet worden gedaan op minder geschikte gegevensbronnen. Het is aangetoond dat het compromitteren van de integriteit van trainingsgegevens een levensvatbare aanvalsvector is tegen een AI-systeem. Dit betekent dat het beveiligen van de supply chain van de data een belangrijke stap is in het beveiligen van de AI. Dit rapport vat de methoden samen die momenteel worden gebruikt om gegevens te verzamelen voor het trainen van AI, samen met de voorschriften, normen en protocollen die de verwerking en het delen van die gegevens kunnen regelen. Het zal vervolgens een hiaatanalyse van deze informatie bieden om mogelijke vereisten voor normen te bepalen om de traceerbaarheid en integriteit van de gegevens, bijbehorende attributen, informatie en feedback te waarborgen, evenals de vertrouwelijkheid hiervan.
SAI-beperkende strategie rapport:Dit werkitem is bedoeld om bestaande en potentiële mitigatie van bedreigingen voor op AI gebaseerde systemen samen te vatten en te analyseren. Het doel is om richtlijnen te hebben voor het mitigeren van bedreigingen die worden geïntroduceerd door AI in systemen toe te passen. Deze richtlijnen zullen een licht werpen op de basislijnen voor het beveiligen van op AI gebaseerde systemen door te mitigeren tegen bekende of potentiële beveiligingsbedreigingen. Ze gaan ook in op beveiligingsmogelijkheden, uitdagingen en beperkingen bij het toepassen van mitigatie voor op AI gebaseerde systemen in bepaalde potentiële gebruikssituaties.
?De rol van hardware in de beveiliging van AI: Een rapport opstellen dat de rol van hardware, zowel gespecialiseerd als algemeen, in de beveiliging van AI identificeert. Hiermee wordt ingegaan op de beperkingen die beschikbaar zijn in hardware om aanvallen te voorkomen en ook op de algemene vereisten voor hardware om SAI te ondersteunen. Daarnaast gaat dit rapport in op mogelijke strategieën om AI te gebruiken voor de bescherming van hardware. Het rapport zal ook een samenvatting geven van academische en industriële ervaring op het gebied van hardwarebeveiliging voor AI. Daarnaast gaat het rapport in op kwetsbaarheden of zwakke punten die zijn geïntroduceerd door hardware die aanvalsvectoren op AI kunnen versterken.
Het volledige ETSI-rapport waarin de probleemstelling voor het beveiligen van AI wordt gedefinieerd, is hier beschikbaar.
Internet of Things-technologie
- IIoT-beveiligingstips en trends voor 2020
- Een recept voor industriële beveiliging:een vleugje IT, een snufje OT en een snufje SOC
- De zoektocht naar een universele IoT-beveiligingsstandaard
- TI:BAW-resonatortechnologie maakt de weg vrij voor communicatie van de volgende generatie
- Cyberbeveiligingsgids uitgegeven voor zakelijke cloudgebruikers
- Meld oproepen tot dringende actie om de cyberdreiging voor kritieke infrastructuur het hoofd te bieden
- Drie stappen voor wereldwijde IoT-beveiliging
- Een gids in vier stappen voor beveiligingsgarantie voor IoT-apparaten
- Wat de komst van 5G betekent voor IoT-beveiliging
- FTC's 'Made in USA' claimt boete baant weg voor extra handhaving
- Rapport State of Cyber Assets vindt nog steeds kwetsbaarheden