


Gebruik FPGA's voor diepgaand leren
Ik heb onlangs het Xilinx Development Forum (XDF) 2018 in Silicon Valley bijgewoond. Op dit forum maakte ik kennis met een bedrijf genaamd Mipsology, een startup op het gebied van kunstmatige intelligentie (AI) die beweert de AI-gerelateerde problemen te hebben opgelost die verband houden met veldprogrammeerbare poortarrays (FPGA's). Mipsology is opgericht met een grootse visie om de berekening van elk neuraal netwerk (NN) te versnellen met de hoogst haalbare prestaties op FPGA's zonder de beperkingen die inherent zijn aan hun implementatie.
Mipsology toonde het vermogen aan om meer dan 20.000 afbeeldingen per seconde uit te voeren, draaiend op de nieuw aangekondigde Alveo-kaarten van Xilinx en het verwerken van een verzameling NN's, waaronder ResNet50, InceptionV3, VGG19, en andere.
Introductie van neurale netwerken en diep leren
Los gemodelleerd naar het web van neuronen in het menselijk brein, vormt een neuraal netwerk de basis van deep learning (DL), een complex wiskundig systeem dat zelfstandig taken kan leren. Door veel voorbeelden of associaties te bekijken, kan een NN leren verbindingen en relaties sneller dan een traditioneel herkenningsprogramma. Het proces van het configureren van een NN om een specifieke taak uit te voeren op basis van leren miljoenen samples van hetzelfde type heet training .
Een NN kan bijvoorbeeld naar veel vocale samples luisteren en DL gebruiken om de klanken van specifieke woorden te leren 'herkennen'. Deze NN zou dan een lijst met nieuwe vocale samples kunnen doorzoeken en samples met de woorden die het heeft geleerd correct kunnen identificeren, met behulp van een techniek genaamd inference .
Ondanks zijn complexiteit is DL gebaseerd op het uitvoeren van eenvoudige bewerkingen - meestal optellingen en vermenigvuldigingen - in de miljarden of biljoenen. De computationele vraag om dergelijke bewerkingen uit te voeren is ontmoedigend. Meer specifiek zijn de computerbehoeften om DL-inferenties uit te voeren groter dan die voor DL-training. Terwijl DL-training slechts één keer hoeft te worden uitgevoerd, moet een NN, eenmaal getraind, keer op keer gevolgtrekkingen uitvoeren voor elk nieuw monster dat het ontvangt.
Vier keuzes om de gevolgtrekking van diep leren te versnellen
In de loop van de tijd nam de technische gemeenschap zijn toevlucht tot vier verschillende computerapparaten om NN's te verwerken. In oplopende volgorde van verwerkingskracht en stroomverbruik, en in afnemende volgorde van flexibiliteit/aanpasbaarheid, omvatten deze apparaten:centrale verwerkingseenheden (CPU's), grafische verwerkingseenheden (GPU's), FPGA's en toepassingsspecifieke geïntegreerde schakelingen (ASIC's). De onderstaande tabel geeft een overzicht van de belangrijkste verschillen tussen de vier computerapparaten.
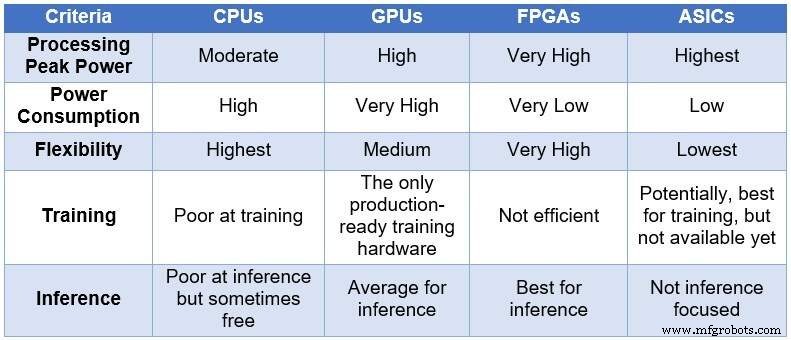
Vergelijking van CPU's, GPU's, FPGA's en ASIC's voor DL-computing (Bron:Lauro Rizzatti)
CPU's zijn gebaseerd op de Von Neuman-architectuur. Hoewel ze flexibel zijn (de reden van hun bestaan), worden CPU's beïnvloed door lange latentie omdat geheugentoegangen verschillende klokcycli in beslag nemen om een eenvoudige taak uit te voeren. Wanneer ze worden toegepast op taken die profiteren van de laagste latenties, zoals NN-berekening en in het bijzonder DL-training en inferentie, zijn ze de slechtste keuze.
GPU's bieden een hoge rekencapaciteit ten koste van verminderde flexibiliteit. Bovendien verbruiken GPU's veel stroom waarvoor koeling nodig is, waardoor ze niet ideaal zijn voor implementatie in datacenters.
Hoewel aangepaste ASIC's misschien een ideale oplossing lijken, hebben ze hun eigen problemen. Het ontwikkelen van een ASIC duurt jaren. DL en NN evolueren snel met voortdurende doorbraken, waardoor de technologie van vorig jaar irrelevant is. Bovendien zou een ASIC, om te kunnen concurreren met een CPU of een GPU, een groot siliciumgebied gebruiken met behulp van de dunste procesknooppunttechnologie. Dit maakt de initiële investering duur, zonder enige garantie op lange termijn relevantie. Alles bij elkaar genomen zijn ASIC's effectief voor specifieke taken.
FPGA-apparaten zijn naar voren gekomen als de best mogelijke keuze voor gevolgtrekking. Ze zijn snel, flexibel, energiezuinig en bieden een goede oplossing voor dataverwerking in datacenters, vooral in de snel veranderende wereld van DL, aan de rand van het netwerk en onder het bureau van AI-wetenschappers.
De grootste FPGA's die momenteel beschikbaar zijn, omvatten miljoenen eenvoudige Booleaanse operators, duizenden geheugens en DSP's en verschillende CPU ARM-kernen. Al deze bronnen werken parallel - elke tik op de klok activeert tot miljoenen gelijktijdige bewerkingen - wat resulteert in biljoenen bewerkingen die per seconde worden uitgevoerd. De verwerking die DL vereist, past redelijk goed op FPGA-bronnen.
FPGA's hebben andere voordelen ten opzichte van CPU's en GPU's die voor DL worden gebruikt, waaronder de volgende:
Ze zijn niet beperkt tot bepaalde soorten gegevens. Ze kunnen een niet-standaard lage precisie aan die meer geschikt is om een hogere doorvoer voor DL te leveren.
Ze verbruiken minder stroom dan CPU's of GPU's — meestal vijf tot tien keer minder gemiddeld vermogen voor dezelfde NN-berekening. Hun terugkerende kosten in datacenters zijn lager.
Ze kunnen geherprogrammeerd worden zodat ze bij elke taak passen, maar ze zijn generiek genoeg om verschillende taken aan te kunnen. DL evolueert snel en dezelfde FPGA zal voldoen aan nieuwe vereisten zonder dat het silicium van de volgende generatie nodig is (wat typisch is voor ASIC's), waardoor de eigendomskosten worden verlaagd.
Ze variëren van grote tot kleine apparaten. Ze kunnen worden gebruikt in datacenters of in een internet of things (IoT)-knooppunt. Het enige verschil is het aantal blokken dat ze bevatten.
Alles wat blinkt is geen goud
De hoge rekenkracht, het lage stroomverbruik en de flexibiliteit van een FPGA hebben een prijs:moeilijk te programmeren.
Internet of Things-technologie
- ETSI-rapport maakt de weg vrij voor standaardisatie van AI-beveiliging
- CEVA:tweede generatie AI-processor voor diepe neurale netwerkworkloads
- Pleidooi voor neuromorfe chips voor AI-computing
- ICP:FPGA-gebaseerde acceleratorkaart voor diepgaande leerinferentie
- Uitbestede AI en deep learning in de zorgsector – loopt de gegevensprivacy gevaar?
- Hoe de hightechindustrie AI inzet voor exponentiële bedrijfsgroei
- Kunstmatige intelligentie versus machinaal leren versus diep leren | Het verschil
- Apple &IBM Watson-team voor enterprise mobile machine learning
- Deep Learning en de vele toepassingen ervan
- Gereedschapsstabiliteitsoplossing voor diepgatboren
- Hoe deep learning inspectie automatiseert voor de biowetenschappenindustrie