


De basisprincipes van gezichtsherkenning
Sinds onheuglijke tijden heeft het menselijk gezicht gediend als de meest eenvoudige standaard voor identificatie. Het is dus niet verwonderlijk dat het de handigste biometrische identificatietechniek blijkt te zijn. In tegenstelling tot andere biometrische methoden zoals spraak, vingerafdrukken, handgeometrie, handpalmafdruk, vereist het analyseren van een gezicht geen actieve medewerking van het object in kwestie. Gezichtsherkenning kan worden gedaan vanaf een foto, video of live-opname.
Gezichtsherkenning is een brede term die wordt gebruikt voor het identificeren of verifiëren van mensen op foto's en video's. De methode omvat detectie, uitlijning, kenmerkextractie en herkenning.
Ondanks verschillende praktische uitdagingen, wordt gezichtsherkenning veel gebruikt in verschillende gebieden, zoals gezondheidszorg, wetshandhaving, spoorwegreservering, beveiliging, domotica en kantoren.
In dit bericht ontdek je het volgende:
- Wat is gezichtsherkenning?
- Een brede classificatie van de gezichtsherkenningsalgoritmen
- Verschillende stadia van een gezichtsherkenningssysteem
- Een overzicht van bouwstenen voor gezichtsherkenning
- Een blik op een SDK voor gezichtsherkenning
Wat is gezichtsherkenning?
Gezichtsherkenning is een biometrische identificatietechniek waarbij de software deep learning-algoritmen gebruikt om de gelaatstrekken van een persoon te analyseren en de gegevens op te slaan. De software vergelijkt vervolgens verschillende gezichten van foto's, video's of live-opnames met de opgeslagen gezichten van de databases en verifieert de identiteiten. Gewoonlijk identificeert de software ongeveer 80 verschillende knooppunten op het gezicht van een persoon. De knooppunten dienen als eindpunten voor het definiëren van de variabelen van het gezicht van een persoon. De variabelen omvatten:vorm van lippen, ogen, lengte en breedte van de neus en diepte van oogkassen.
De populariteit van gezichtsherkenning in vergelijking met de andere biometrische technieken komt voort uit het feit dat het meestal nauwkeuriger en minst opdringerig is.
Classificatie van gezichtsherkenningsalgoritme Gezichtsherkenning is de techniek om een gezicht te herkennen dat al in de database is geregistreerd. Een gezichtsherkenningssysteem is in grote lijnen betrokken bij twee taken:verificatie en Identificatie .
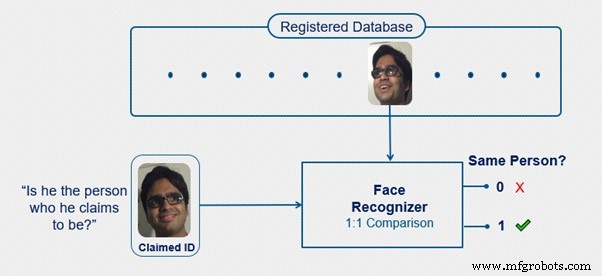
Verificatie is bedoeld om de vraag te beantwoorden:"Is hij de persoon die hij beweert te zijn?" Wanneer een persoon beweert een specifieke persoon te zijn, vindt het verificatiesysteem zijn profiel in de database. Het vergelijkt het gezicht van de persoon met dat in het profiel in de database om te controleren of ze overeenkomen. Het is een 1-op-1 matching-systeem omdat het systeem het gezicht van de persoon moet matchen met een specifiek gezicht dat al aanwezig is in het gekoppelde profiel. Verificatie is dus sneller dan identificatie en nauwkeuriger.
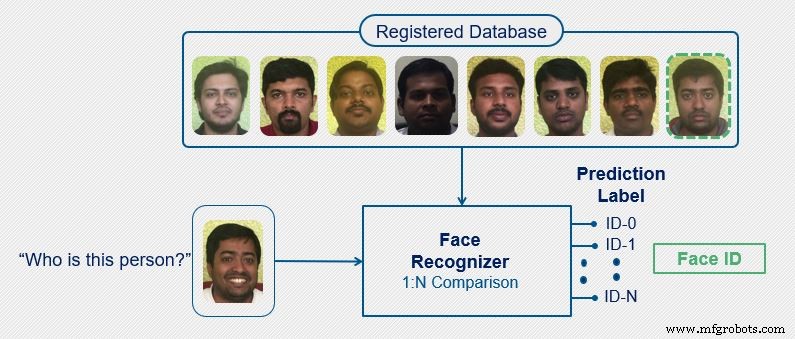
Bij gezichtsidentificatie probeert het systeem het ingevoerde gezicht te vergelijken met alle gezichten in de database. Dit is een 1-op-n matching systeem.
Verschillende stadia van een gezichtsherkenningssysteem
Laten we het hebben over de twee fasen van een gezichtsherkenningssysteem:registratie en erkenning .
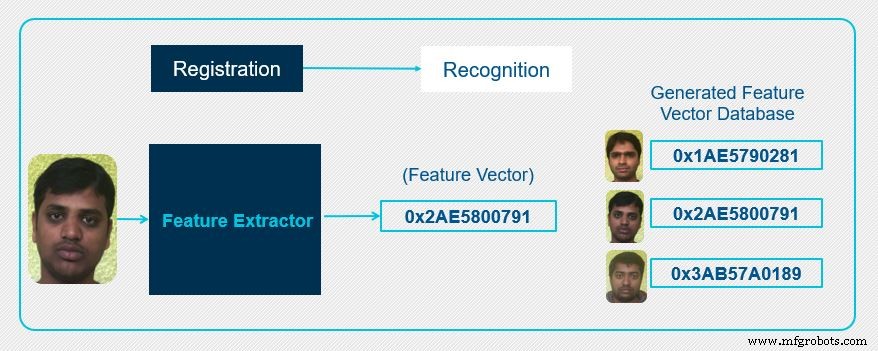
In de eerste fase of de registratiefase wordt een reeks bekende gezichten ingeschreven. De feature extractor genereert dan een unieke feature vector voor elk van de geregistreerde gezichten. De kenmerkvector wordt gegenereerd op basis van de unieke gezichtskenmerken van elk van de gezichten. De geëxtraheerde kenmerkvector, die uniek is voor elk gezicht, wordt een onderdeel van de geregistreerde database en kan worden gebruikt voor toekomstig gebruik.
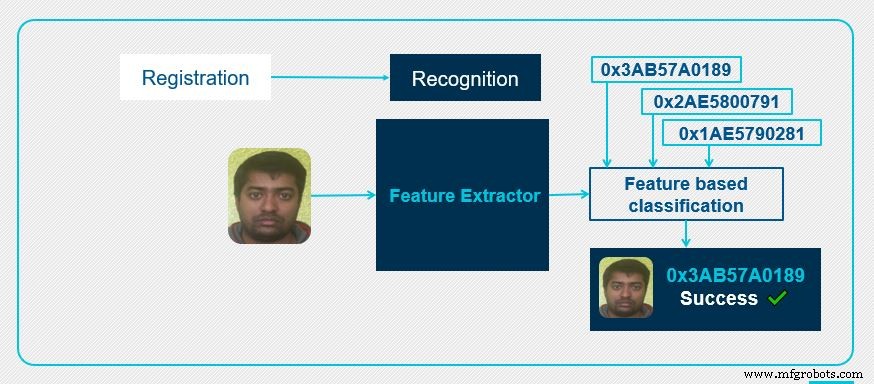
In de herkenningsfase wordt een invoerbeeld geleverd aan de feature-extractor om gezichtsherkenning uit te voeren. Ook hier genereert de feature-extractor een feature-vector die uniek is voor het invoergezichtsbeeld. Deze feature vector wordt dan vergeleken met de feature vectoren die al beschikbaar zijn in de database. Het blok 'op kenmerken gebaseerde classificatie' vergelijkt de afstand tussen de gezichtskenmerken van het ingevoerde gezicht en de geregistreerde gezichten van de database. Wanneer een geregistreerd gezicht voldoet aan de overeenkomende criteria, retourneert de op kenmerken gebaseerde classificatie de overeenkomende gezichts-ID die in de database is gevonden.
Bouwstenen van een gezichtsherkenningssysteem
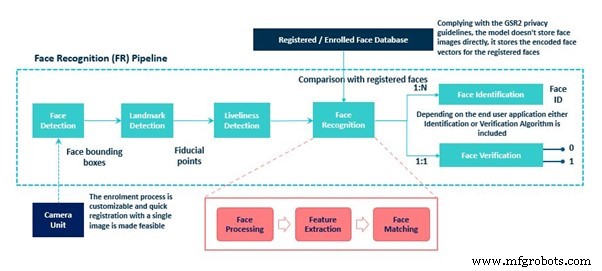
De belangrijkste onderdelen van een gezichtsherkenningssysteem zijn:gezichtsherkenning, herkenningspuntherkenning, levendigheidsdetectie, gezichtsherkenningsmodule (gezichtsherkenning, gezichtsherkenning/gezichtsverificatie).
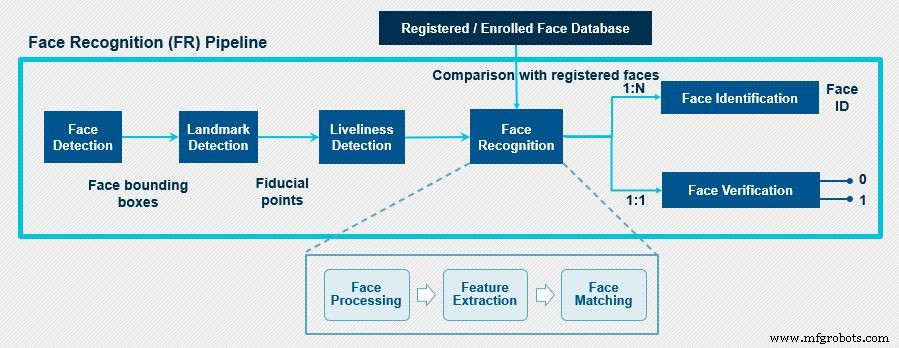
Bij het begin wordt een afbeelding of een frame van een videostream naar de gezichtsdetectiemodule gestuurd waar de gezichten worden gedetecteerd vanuit het invoerbeeld. Als uitvoer stuurt het de coördinaten van het begrenzingsvak voor de gedetecteerde gezichten. De valkuil hier is dat hoewel de gezichtsdetector de gezichten van de afbeelding lokaliseert en het begrenzingskader voor elk gezicht maakt, dit niet de juiste uitlijning van de gezichten garandeert en dat de aan het gezicht gebonden vakken onderhevig zijn aan jitter. Er is dus een gezichtsvoorbewerkingsfase vereist om een effectieve gezichtsvector te verkrijgen. Deze fase helpt bij het verbeteren van de gezichtsdetectie van het systeem.
Gezichtsvoorbewerking wordt gedaan in het herkenningspuntdetectieblok, dat de locatie van de referentiepunten (ook wel de vaste oriëntatiepunten genoemd) op het gezicht identificeert, zoals ogen, neus, lippen, kin, kaak. Deze gedetecteerde gezichtsoriëntatiepunten worden vervolgens gecompenseerd voor ruimtelijke veranderingen in het gezicht. Dit wordt gedaan door de geometrische structuur van het gezicht te identificeren en een canonieke uitlijning te verkrijgen op basis van verschillende transformaties zoals translatieschaalrotatie. Dit geeft een strak begrenzend kader van het gezicht met genormaliseerde canonieke coördinaten.
Voordat we het uitgelijnde gezicht naar de gezichtsherkenningsmodule sturen, is het essentieel om te controleren op gezichtsspoofing om er zeker van te zijn dat het gezicht afkomstig is uit een live feed van een afbeelding of video en niet een vervalsing is om ongeautoriseerde toegang te krijgen. De levendigheidsdetector doet deze controle.
De afbeelding wordt vervolgens naar het volgende blok gestuurd, het gezichtsherkenningsblok. Dit blok voert een reeks verwerkingstaken uit voordat de gezichtsherkenning met succes is voltooid. De eerste stap is gezichtsverwerking, die nodig is om variaties binnen de klasse in het invoervlak af te handelen. Dit is een essentiële stap omdat we niet willen dat de gezichtsherkenningsmodule wordt afgeleid door variaties zoals verschillende poses, uitdrukkingen, verlichtingsveranderingen en occlusies die aanwezig zijn in het invoergezichtsbeeld. Nadat de intraklasse-variaties in het invoervlak zijn opgelost, is de volgende belangrijke verwerkingsstap kenmerkextractie. De functie van een feature extractor is hierboven al besproken.
De laatste stap van een gezichtsherkenningsmodule is de face matching stap, waarbij een vergelijking wordt gemaakt tussen de in de laatste stap verkregen kenmerkvectoren en de geregistreerde gezichtsvectoren in de database. In deze stap wordt de overeenkomst berekend en wordt een overeenkomstscore gegenereerd die verder wordt gebruikt voor gezichtsidentificatie of gezichtsverificatie volgens de vereiste.
Een voorbeeld van een SDK voor gezichtsherkenning

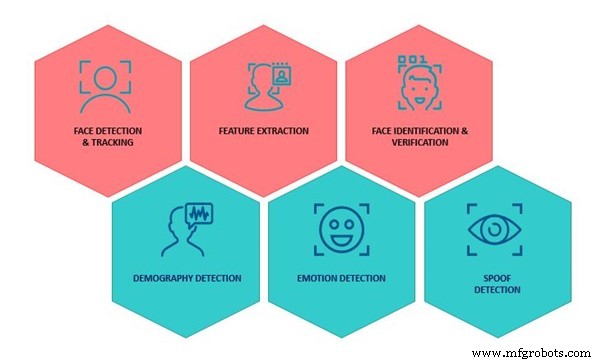
We gebruiken de licentiebare SDK-softwareoplossing voor gezichtsherkenning van PathPartner om te laten zien hoe een nauwkeurig gezichtsdetectie- en gezichtsherkenningssysteem kan worden geïmplementeerd. De SDK, die machine learning en computer vision-algoritmen omvat, stelt u in staat zes essentiële gezichtsherkenningstaken uit te voeren.
De SDK is er in twee varianten:
- Lange complexiteitsvariant met een modelgrootte van slechts 10 MB, geschikt voor eindapparaten met weinig geheugen en verwerkingskracht.
- Hoge complexiteitsvariant met een modelgrootte van 90 MB geschikt voor full-service edge-apparaten.
Het algoritme is geoptimaliseerd op een reeks embedded platforms van Texas Instruments, Qualcomm, Intel, Arm, NXP en kan verder werken op de cloudserverplatforms.
Ontwikkelen van een op CNN gebaseerd gezichtsherkenningssysteem
De op CNN gebaseerde aanpak heeft de voorkeur boven een niet-CNN-gebaseerde aanpak om de inspanningen voor het bestrijden van uitdagingen zoals occlusie en verschillende lichtomstandigheden te verminderen. Het herkenningsproces omvat de volgende stappen:
Gegevensverzameling
Openbaar beschikbare datasets dekken niet alle evaluatieparameters die essentieel zijn voor gezichtsherkenning. Dit vereist daarom gedetailleerde benchmarking op een aantal standaard en interne datasets die een breed scala aan variaties dekken die kunnen worden gebruikt voor de gezichtsanalyse. De volgende variaties worden ondersteund in deze SDK:pose, verlichting, expressie, occlusie, geslacht, achtergrond, etniciteit, leeftijd, oog, uiterlijk.
Deep learning-modelontwerp
De complexiteit van het model hangt af van de eindgebruikerstoepassing. Deze SDK is geïmplementeerd in chauffeursbewakingssystemen (DMS) en slimme aanwezigheidssystemen.
Driver monitoring systeem:om de alertheid en focus van de bestuurder in realtime te beoordelen, is edge computing nodig. Er is dus een robuust systeem met een lage complexiteit nodig. Hier wordt een machine learning-model gebruikt voor gezichtsdetectie en regressie van herkenningspunten en een ondiep en diep CNN-model voor schattingen en classificaties.
Training en optimalisatie
De modules zijn vooraf getraind op de dataset die in eerste instantie is opgesteld. De oplossing is getest op verschillende open-source datasets zoals FDDB, LFW en een op maat gemaakte in-house ontwikkelde dataset.
De verschillende uitdagingen overwinnen
- Verlichting variatie – om het probleem op te lossen dat wordt gepresenteerd als gevolg van variatie in verlichtingsomstandigheden, worden twee benaderingen gevolgd. Een daarvan is de conversie van RGB naar NIR-achtige afbeeldingen met behulp van op Gantt gebaseerde benaderingen. Een ander voorbeeld is het trainen van het model met RGB-gegevens en het finetunen met NIR-beelden aan de ingang.
- Poseer- en uitdrukkingsvariaties – als gezichtsafbeeldingen beschikbaar zijn vanuit een niet-frontale weergave, moet de canonieke weergave van gezichtsafbeelding worden afgeleid van een of meer van de beschikbare afbeeldingen. Dit wordt bereikt door de houdingsverandering met betrekking tot de hoofdhoeken te schatten op basis van de oriëntatiepunten en vervolgens kantelen, strekken, spiegelen en andere bewerkingen te gebruiken om de frontale koers te verkrijgen. Hierdoor kan het gezichtsherkenningssysteem pose-invariante representaties uitvoeren en wordt de nauwkeurigheid van de gezichtsherkenning aanzienlijk verbeterd. Om de effecten als gevolg van variatie in uitdrukking tegen te gaan, wordt de gezichtsuitlijning uitgevoerd in de voorbewerkingsfase.
- Occlusie – momenteel wordt de SDK getraind om gemaskerde gezichten te detecteren. In dit geval wordt het model getraind om alleen te werken met gegevens rond de ogen en het voorhoofd; deze benadering geeft echter de beste resultaten in een ongecontroleerde omgeving zoals kantooromgevingen wanneer een beperkt aantal mensen in het systeem is geregistreerd.
- Uiterlijk variatie – verschillen in haarstijlen, veroudering en gebruik van cosmetica kunnen grote verschillen in het uiterlijk van individuen veroorzaken. Dus de nauwkeurigheid van de gezichtsherkenning in grote mate verslechteren. Om dit probleem aan te pakken, gebruikt de SDK een weergave- en afstemmingsschema dat bestand is tegen veranderingen in uiterlijk.

Conclusie
Tegenwoordig wordt gezichtsherkenning beschouwd als de meest natuurlijke van alle biometrische metingen. Deep learning is het centrale onderdeel geworden van de meeste algoritmen voor gezichtsherkenning die worden ontwikkeld. Algoritmen voor gezichtsherkenning zien exponentiële vooruitgang. Volgens een recent NIST-rapport is er in de afgelopen vijf jaar (2013-2018) enorme vooruitgang geboekt in de nauwkeurigheid van de herkenning en zijn ze groter dan de verbeteringen die in de periode 2010-2013 zijn bereikt.
Ondanks verschillende praktische uitdagingen, wordt gezichtsherkenningstechnologie op grote schaal gebruikt in verschillende sectoren, zoals de detailhandel, de auto-industrie, het bankwezen, de gezondheidszorg, marketing en nog veel meer. Naast het verbeteren van de nauwkeurigheid van het herkennen van een persoon, breiden gezichtsherkenningsalgoritmen hun reikwijdte uit bij het detecteren van de emoties en het gedrag van gezichten.
Ingebed
- De 555 IC
- De kwadratische formule
- Windows IoT:deur met gezichtsherkenning
- De grondbeginselen van de fabricage van printplaten
- De basisprincipes van het toepassen van elektrohydraulische ventielen
- Verstoren of sterven? Begin met de basis
- De grondbeginselen van een verticaal bewerkingscentrum (VMC)
- Grondbeginselen van het scheermes:de effecten van meskwaliteit op de scheerprestaties
- De grondbeginselen van verzinken en de bijbehorende voordelen
- De grondbeginselen van afschuinen en ontbramen van tandwielen
- Grondbeginselen van OD-slijpen