


Een meerlagig Perceptron neuraal netwerk maken in Python
Dit artikel leidt u stap voor stap door een Python-programma waarmee we een neuraal netwerk kunnen trainen en geavanceerde classificatie kunnen uitvoeren.
Dit is de 12e inzending in de reeks over neurale netwerkontwikkeling van AAC. Bekijk hieronder wat de serie nog meer te bieden heeft:
- Hoe classificatie uitvoeren met behulp van een neuraal netwerk:wat is de Perceptron?
- Een eenvoudig Perceptron neuraal netwerkvoorbeeld gebruiken om gegevens te classificeren
- Een basis Perceptron neuraal netwerk trainen
- Eenvoudige neurale netwerktraining begrijpen
- Een inleiding tot trainingstheorie voor neurale netwerken
- De leersnelheid in neurale netwerken begrijpen
- Geavanceerde machine learning met de meerlaagse Perceptron
- De Sigmoid-activeringsfunctie:activering in meerlaagse Perceptron neurale netwerken
- Een meerlagig Perceptron neuraal netwerk trainen
- Trainingsformules en backpropagation voor meerlaagse perceptrons begrijpen
- Neurale netwerkarchitectuur voor een Python-implementatie
- Hoe maak je een meerlaags Perceptron neuraal netwerk in Python
- Signaalverwerking met behulp van neurale netwerken:validatie in neuraal netwerkontwerp
- Trainingsdatasets voor neurale netwerken:een neuraal netwerk met Python trainen en valideren
In dit artikel nemen we het werk dat we hebben gedaan aan neurale netwerken van Perceptron en leren we hoe we er een kunnen implementeren in een bekende taal:Python.
Ontwikkelen van begrijpelijke Python-code voor neurale netwerken
Onlangs heb ik nogal wat online bronnen voor neurale netwerken bekeken, en hoewel er ongetwijfeld veel goede informatie is, was ik niet tevreden met de software-implementaties die ik vond. Ze waren altijd te complex, of te compact, of niet voldoende intuïtief. Toen ik mijn Python-neuraal netwerk aan het schrijven was, wilde ik echt iets maken dat mensen zou kunnen helpen om te leren hoe het systeem werkt en hoe de neurale-netwerktheorie wordt vertaald in programma-instructies.
Soms is er echter een omgekeerd verband tussen de duidelijkheid van code en de efficiëntie van code. Het programma dat we in dit artikel zullen bespreken is zeker niet geoptimaliseerd voor snelle prestaties. Optimalisatie is een serieus issue binnen het domein van neurale netwerken; real-life toepassingen kunnen enorme hoeveelheden training vergen, en bijgevolg kan grondige optimalisatie leiden tot een aanzienlijke vermindering van de verwerkingstijd. Voor eenvoudige experimenten zoals die we gaan doen, duurt de training echter niet erg lang, en er is geen reden om te benadrukken over codeerpraktijken die eenvoud en begrip verkiezen boven snelheid.
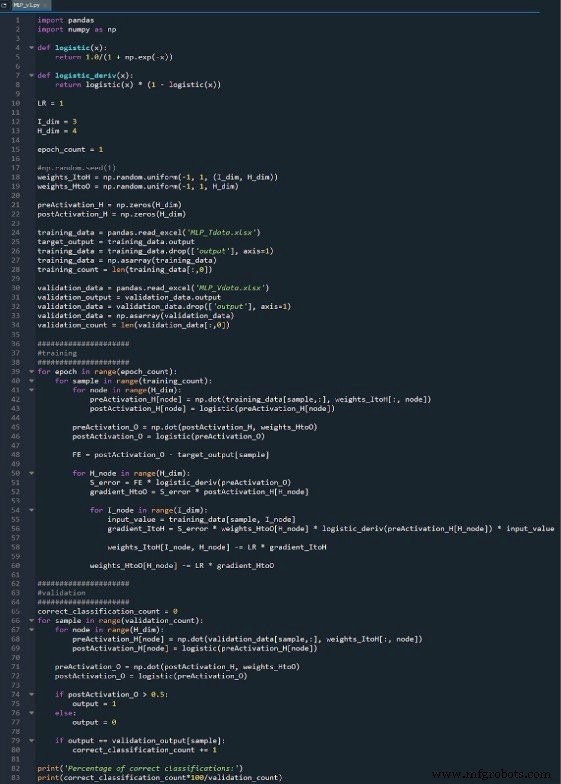
Het volledige Python-programma is als afbeelding aan het einde van dit artikel opgenomen en het bestand ("MLP_v1.py") wordt als download geleverd. De code voert zowel training als validatie uit; dit artikel is gericht op training en we zullen validatie later bespreken. Hoe dan ook, er is niet veel functionaliteit in het validatiegedeelte dat niet wordt behandeld in het trainingsgedeelte.
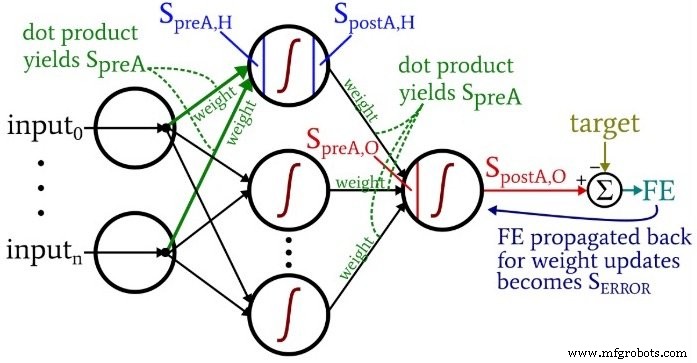
Terwijl je over de code nadenkt, wil je misschien terugkijken naar het enigszins overweldigende maar zeer informatieve architectuur-plus-terminologiediagram dat ik in deel 10 heb verstrekt.
Functies en variabelen voorbereiden
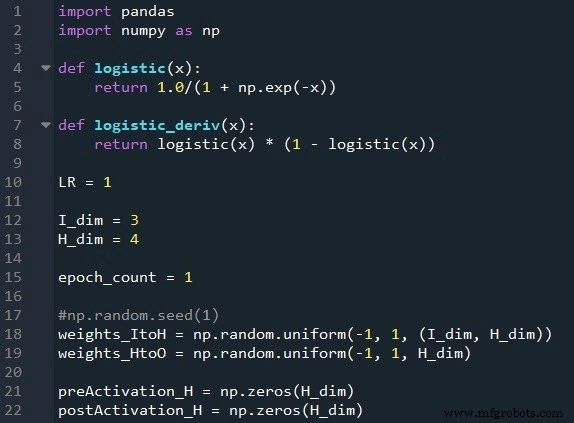
De NumPy-bibliotheek wordt veel gebruikt voor de berekeningen van het netwerk en de Pandas-bibliotheek biedt me een handige manier om trainingsgegevens uit een Excel-bestand te importeren.
Zoals je al weet, gebruiken we de logistieke sigmoid-functie voor activering. We hebben de logistieke functie zelf nodig voor het berekenen van postactivatiewaarden, en de afgeleide van de logistieke functie is vereist voor backpropagation.
Vervolgens kiezen we de leersnelheid, de dimensionaliteit van de invoerlaag, de dimensionaliteit van de verborgen laag en het aantal tijdperken. Trainen over meerdere tijdperken is belangrijk voor echte neurale netwerken, omdat je hiermee meer uit je trainingsgegevens kunt halen. Wanneer u trainingsgegevens in Excel genereert, hoeft u niet meerdere tijdperken uit te voeren, omdat u eenvoudig meer trainingsvoorbeelden kunt maken.
De np.random.uniform() functie vult onze twee gewichtsmatrices met willekeurige waarden tussen –1 en +1. (Merk op dat de verborgen-naar-uitvoermatrix eigenlijk gewoon een array is, omdat we maar één uitvoerknooppunt hebben.) De np.random.seed(1) statement zorgt ervoor dat de willekeurige waarden elke keer dat u het programma uitvoert hetzelfde zijn. De initiële gewichtswaarden kunnen een aanzienlijk effect hebben op de uiteindelijke prestaties van het getrainde netwerk, dus als u probeert te beoordelen hoe andere Als variabelen de prestaties verbeteren of verslechteren, kunt u commentaar op deze instructie verwijderen en zo de invloed van willekeurige gewichtsinitialisatie elimineren.
Ten slotte maak ik lege arrays voor de pre- en postactivation-waarden in de verborgen laag.
Trainingsgegevens importeren

Dit is dezelfde procedure die ik in deel 4 heb gebruikt. Ik importeer trainingsgegevens uit Excel, scheid de doelwaarden in de kolom "output", verwijder de kolom "output", converteer de trainingsgegevens naar een NumPy-matrix en bewaar het aantal trainingsvoorbeelden in de training_count variabel.
Feedforward-verwerking
De berekeningen die een uitvoerwaarde produceren en waarin gegevens van links naar rechts bewegen in een typisch neuraal netwerkdiagram, vormen het "feedforward" -gedeelte van de werking van het systeem. Hier is de feedforward-code:
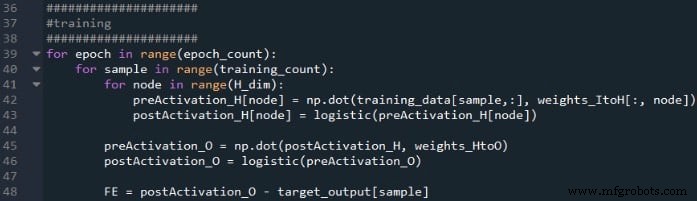
De eerste for-lus stelt ons in staat om meerdere tijdperken te hebben. Binnen elk tijdperk berekenen we een uitvoerwaarde (d.w.z. het postactiveringssignaal van het uitvoerknooppunt) voor elk monster, en die bewerking per monster wordt vastgelegd door de tweede for-lus. In de derde for-lus behandelen we elk verborgen knooppunt afzonderlijk, waarbij we het puntproduct gebruiken om het preactiveringssignaal te genereren en de activeringsfunctie om het postactiveringssignaal te genereren.
Daarna zijn we klaar om het preactiveringssignaal voor het outputknooppunt te berekenen (opnieuw met behulp van het puntproduct), en passen we de activeringsfunctie toe om het postactiveringssignaal te genereren. Vervolgens trekken we het doel af van het postactiveringssignaal van het uitgangsknooppunt om de uiteindelijke fout te berekenen.
Terugpropagatie
Nadat we de feedforward-berekeningen hebben uitgevoerd, is het tijd om van richting te veranderen. In het backpropagation-gedeelte van het programma gaan we van het uitvoerknooppunt naar de verborgen-naar-uitvoergewichten en vervolgens de invoer-naar-verborgen gewichten, waarbij we de foutinformatie meenemen die we gebruiken om het netwerk effectief te trainen.

We hebben hier twee lagen for-lussen:één voor de verborgen-naar-uitvoergewichten en één voor de invoer-naar-verborgen gewichten. We genereren eerst SERROR , die we nodig hebben voor het berekenen van beide gradiëntHtoO en verloopItoH , en dan werken we de gewichten bij door de gradiënt vermenigvuldigd met de leersnelheid af te trekken.
Merk op hoe de invoer-naar-verborgen gewichten worden bijgewerkt binnen de lus van verborgen naar uitvoer. We beginnen met het foutsignaal dat terugleidt naar een van de verborgen knooppunten, daarna breiden we dat foutsignaal uit naar alle invoerknooppunten die zijn verbonden met dit ene verborgen knooppunt:
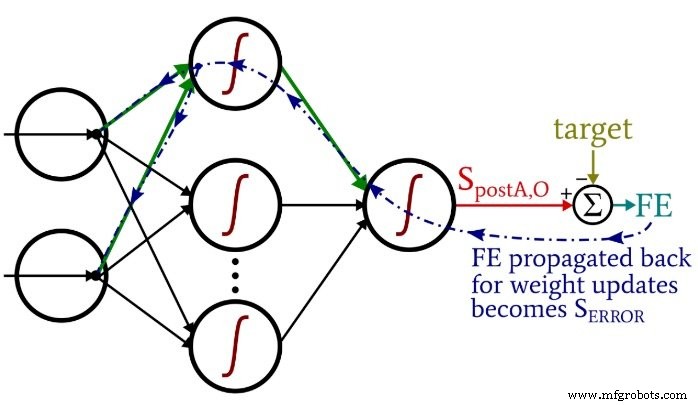
Nadat alle gewichten (zowel ItoH als HtoO) die bij dat ene verborgen knooppunt horen, zijn bijgewerkt, gaan we terug en beginnen we opnieuw met het volgende verborgen knooppunt.
Merk ook op dat de ItoH-gewichten worden aangepast vóór de HtoO-gewichten. We gebruiken het huidige HtoO-gewicht wanneer we gradiëntItoH . berekenen , dus we willen de HtoO-gewichten niet wijzigen voordat deze berekening is uitgevoerd.
Conclusie
Het is interessant om na te denken over hoeveel theorie er in dit relatief korte Python-programma is gestoken. Ik hoop dat deze code je helpt om echt te begrijpen hoe we een meerlagig Perceptron neuraal netwerk in software kunnen implementeren.
Je kunt mijn volledige code hieronder vinden:
Downloadcode
Industriële robot
- Een CloudFormation-sjabloon maken met AWS
- Hoe creëer je een cloud center of excellence?
- Hoe maak je een wrijvingsloze UX
- Een lijst met strings maken in VHDL
- Hoe maak je een zelfcontrolerende testbank aan
- Een timer maken in VHDL
- Een geklokt proces maken in VHDL
- Lokale minima in neurale netwerktraining begrijpen
- Bias-knooppunten opnemen in uw neurale netwerk
- Hoe een array van objecten in Java te maken
- Python - Netwerkprogrammering