


Hoe valkuilen te vermijden met data-analyseprojecten
Uit een recent onderzoek van Capgemini blijkt dat 15% van de big data-initiatieven in Europa mislukken. Om ervoor te zorgen dat jouw project bij de 85% hoort die succesvol is, heb ik de vier belangrijkste valkuilen samengevat waar je op moet letten. (Deze blogpost bevat de eerste twee valkuilen, de andere twee zullen in een andere blogpost worden gepubliceerd. )
Als u hiervan op de hoogte bent en er rekening mee houdt, vergroot u de kans dat uw data-analyseproject een succes wordt aanzienlijk. Maak je geen zorgen:je bent lang niet de enige die met deze uitdagingen en valkuilen wordt geconfronteerd. In onze initiële workshop data-analyse zien we regelmatig deelnemers die hen tegenkomen, tot aan het einde van het project. Hier wil ik mijn inzichten uit vele succesvolle workshops en projecten met u delen, de belangrijkste valkuilen aanwijzen en deze illustreren met praktijkvoorbeelden.
1. De initiatiefnemer – IT vs. afdeling
Data-analyse en big data zijn niet één en hetzelfde, ook al worden ze vaak door elkaar gebruikt.
IT-afdelingen bekijken projecten vaak door een “big data-bril”. Ze bieden de infrastructuur voor het verzamelen van grote hoeveelheden data; bijvoorbeeld in de vorm van databaseclusters. Deze databases slaan enorme hoeveelheden data op, wat op zich geen toegevoegde waarde creëert voor het bedrijf. Daarom moet het data-analyseproject altijd een duidelijk gedefinieerd technologisch en commercieel doel hebben. Het verzamelen van gegevens alleen al levert het bedrijf geen enkel voordeel op.
Toegevoegde waarde ontstaat pas als het bedrijf gebruik maakt van de data en de daaruit voortvloeiende inzichten. Dit is waar de (niet-administratieve) afdelingen van pas komen. Zij bepalen welke doelen ze willen bereiken met data-analyse – niet met big data. Ze zorgen voor het technische inzicht waarmee datawetenschappers gericht met de data kunnen werken. Een nauwe samenwerking tussen de ideeënleverancier (afdeling) en de datawetenschappers is daarom een absolute must om het gedefinieerde projectdoel te bereiken.
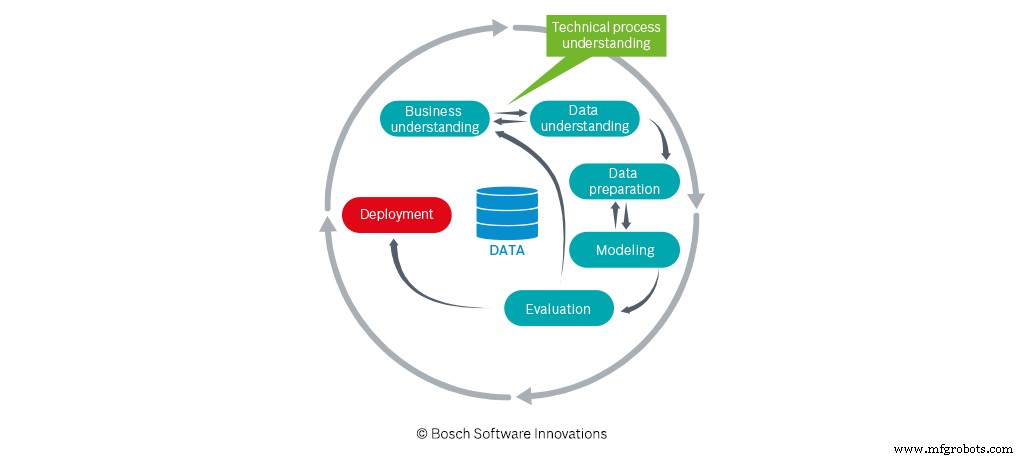
Met andere woorden:het succes of falen van een data-analyseproject hangt af van wat en hoeveel technisch procesinzicht wordt doorgegeven aan de datawetenschappers. Ook hier spelen data analytics engineers een belangrijke rol. Zij ondersteunen de “vertaling” en kennisoverdracht tussen de verschillende disciplines. Ingenieurs voor data-analyse putten uit hun operationele ervaring in productie of logistiek en een gedegen basiskennis van benaderingen van data-analyse. De data-experts moeten niet alleen het projectdoel begrijpen, maar ook en vooral de correlaties in de data. Wat nog belangrijker is, ze moeten de relatie met de echte wereld (machines, sensoren, enz.) En de gerelateerde processtappen zien.
Zoals het onderzoek van Capgemini laat zien, zijn IT-afdelingen vaak de initiatiefnemers van data-analyseprojecten. Dit is op zich geen probleem, zolang de andere afdelingen er nauw bij betrokken zijn en de technische doelstellingen van het project definiëren.
2. Niet alle gegevens zijn gelijk gemaakt
Project gestart, doel gedefinieerd - ga!
Stop!
Voordat de datawetenschappers aan de slag kunnen, moet je de kwaliteit en kwantiteit van de data verifiëren.
a) Kwaliteit van de gegevens
Hier is het belangrijk om te overwegen in welk formaat de gegevens beschikbaar zijn, waar te zoeken naar welke gegevens en of de gegevens transparant zijn over verschillende bronnen heen.
Voorbeeld:
Om een dataset uit meerdere bronnen te integreren, heb je een unieke identifier nodig waarmee de data correct kunnen worden verzameld. Dit kan bijvoorbeeld een tijdstempel of een onderdeelnummer zijn. Het gebruik van een tijdstempel maakt integratie ingewikkelder als verschillende datum-/tijdformaten worden gebruikt in de afzonderlijke gegevensbronnen (Duits vs. Amerikaans datumformaat, tijd in UTS, enz.); het is echter nog steeds mogelijk. Het is daarentegen vrijwel onmogelijk als er verschillende tijdsbases worden gebruikt. Dit is het geval wanneer er geen uniforme tijdsynchronisatie is die de tijdstempels voor alle gegevensbronnen genereert.
b) Hoeveelheid van de gegevens
Hoe meer, hoe beter, zo luidt het gezegde. Maar met betrekking tot data-analyse is dit slechts ten dele waar. Over het algemeen geldt natuurlijk:hoe meer gegevens u heeft, hoe beter. Maar ook hier zijn er een aantal belangrijke aspecten waarmee u rekening moet houden.
Afhankelijk van de technische doeldefinitie kan het bijvoorbeeld belangrijk zijn dat de onderliggende gegevens niet alleen positieve uitkomsten bevatten, maar ook voldoende negatieve uitkomsten.
Voorbeeld:een negatief resultaat voorspellen
Als het doel van het project is om een model te ontwikkelen voor het voorspellen van een negatieve uitkomst, moet de trainingsdataset die wordt gebruikt om het voorspellingsmodel te trainen een voldoende aantal negatieve uitkomsten bevatten. Anders is het model niet in staat om deze negatieve uitkomsten te leren en daarom niet in staat om ze te voorspellen - bijgevolg kunt u het projectdoel niet bereiken met deze dataset! Om deze reden moet u bij het samenstellen van de trainingsgegevensset ervoor zorgen dat deze een voldoende hoeveelheid van de te voorspellen parameter bevat (doelvariabele) - in het bovenstaande voorbeeld negatieve resultaten. Een manier om dit te bereiken is door de periode waarin de gegevens worden verzameld, uit te breiden.
c) De "juiste" gegevens
Het is dus duidelijk dat de hoeveelheid data niet het enige criterium is. Je hebt vooral de juiste gegevens nodig!
Wat bedoelen we met de "juiste gegevens"?
De gegevens moeten de relevante informatie bevatten die nodig is om het technische projectdoel te bereiken. Als u bijvoorbeeld een model wilt ontwikkelen voor het voorspellen van de productkwaliteit zoals gedefinieerd door een oppervlakteruwheidsmeting, dan moet deze variabele in de dataset worden weergegeven. Als u de meting uitvoert zonder de meetwaarde vervolgens op te slaan, kunt u geen bijbehorend model ontwikkelen. Ook dit is geen onoplosbaar probleem, maar kan de voortgang vertragen omdat er eerst een adequate databasis moet worden gegenereerd (bijvoorbeeld met behulp van aanvullende sensortechnologie, het opslaan van de relevante data, etc.).
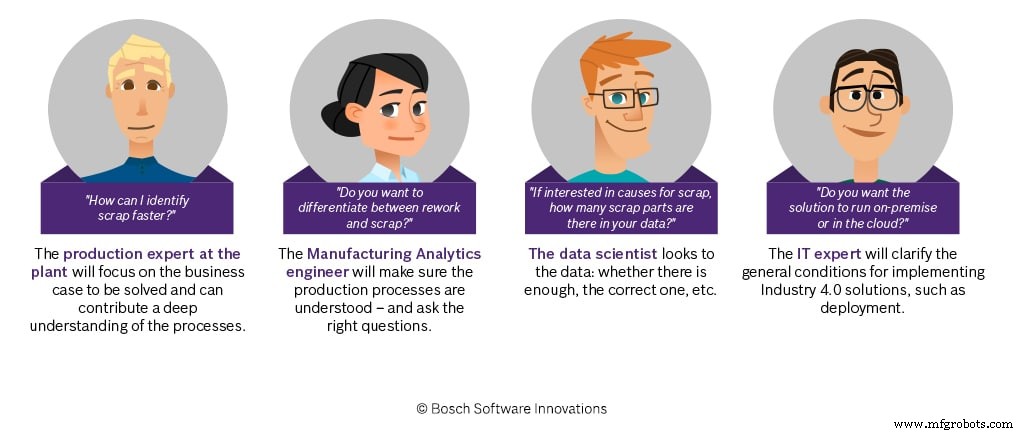
Wie zorgt ervoor dat uw data-analyseproject zal slagen?
 Bron:Bosch.IO
Bron:Bosch.IO
Om experts te helpen bij het bereiken van a), b) en c), hebben we de ervaring die we hebben opgedaan in veel succesvolle projecten, gebundeld in richtlijnen voor gegevenskwaliteit, die we aan het begin van een project verstrekken. We behandelen dit onderwerp ook in de eerste workshops door de use cases te identificeren die quick wins zullen opleveren. Op deze manier maken we productie-experts bewust van deze onderwerpen, wat altijd een duidelijk voordeel blijkt te zijn voor de volgende stappen in het proces.
Industriële technologie
- Industrie 4.0 upgraden met edge-analyse
- Productie optimaliseren met Big Data Analytics
- Hoe problemen met gebruikte CNC-machines te voorkomen
- Zakelijke resultaten behalen met big data-projecten en AI
- Drie valkuilen van last-mile delivery - en hoe ze te vermijden
- Hoe datawetenschap de uitbraak van het coronavirus heeft helpen bestrijden
- Datamining, AI:hoe industriële merken e-commerce kunnen bijhouden
- Hoe cloudanalyse de transformatie van de digitale supply chain kan versnellen
- 5 redenen waarom IoT-projecten mislukken en hoe u dit kunt vermijden
- Industriële machine learning-projecten ontwikkelen:3 veelvoorkomende fouten die u moet vermijden
- Hoe fabrikanten Analytics kunnen gebruiken voor een betere klantervaring