


Is 2017 het jaar van de spraakinterface?
In de afgelopen jaren hebben aanzienlijke vorderingen op het gebied van automatische spraakherkenning (ASR) geleid tot een overvloed aan apparaten en toepassingen die spraak als hun belangrijkste interface gebruiken. Het IEEE-spectrum magazine heeft 2017 uitgeroepen tot het jaar van spraakherkenning; ZDNet meldde vanaf CES 2017 dat spraak de volgende computerinterface is; en vele anderen delen soortgelijke opvattingen. Dus, waar staan we met betrekking tot de vooruitgang van spraakinterfaces? Dit bericht geeft een overzicht van de huidige staat van spraakinterfaces en de bijbehorende technologieën.
Hoeveel van uw apparaten praten met u?
Stemactivering is overal om ons heen. Bijna elke smartphone heeft een spraakinterface, met vlaggenschepen zoals de Apple iPhone 7 en Samsung Galaxy S7 inclusief altijd luisterende functies. De meeste smartwatches bieden spraakactivering, evenals andere wearables, en vooral hearables, zoals Apple's AirPods en Samsung's Gear IconX. In de meeste van die apparaten is er geen gemakkelijke manier om een andere interface te integreren, waardoor spraak een ideale en noodzakelijke oplossing is. Nieuwe camera's, zoals de GoPro Hero 5, kunnen worden bediend met spraakopdrachten, wat geweldig is voor selfies. Spraakgestuurde infotainmentsystemen voor auto's zijn een handelsartikel geworden, waardoor het veel veiliger is om tijdens het rijden van station te wisselen.
De Amazon Echo ontketende de trend van gespreksassistenten, die in vuur en vlam staat met Google Home die probeert te strijden en een verscheidenheid aan vergelijkbare klonen die op CES 2017 worden getoond. De spraakservice van de Echo, genaamd Alexa, wordt geleverd met verschillende ingebouwde vaardigheden. Je kunt bijvoorbeeld "Alexa, vertel me een grapje" zeggen (zeer wrange levering), "Alexa, hebben de Warriors gewonnen?" (natuurlijk deden ze dat), of "Alexa, die speelde in de film 2001:A Space Odyssey?" (niemand anders schijnt het te weten). Er zijn ook een heleboel grappige paaseieren, zoals de reactie als je zegt "Alexa, start zelfvernietigingsreeks." (zie ook deze video waarin enkele van Alexa's paaseieren worden gedemonstreerd).
Naast de ingebouwde functies kunnen er nieuwe mogelijkheden aan Alexa worden toegevoegd door derden met behulp van de Alexa Skills Kit (ASK). Deze VRAAG stelt ontwikkelaars in staat Alexa nieuwe vaardigheden aan te leren, zodat zij (of het?) meer producten en diensten kan bedienen en ermee kan werken. Zoals je in deze video kunt zien, heeft iemand bijvoorbeeld zijn iRobot Roomba gehackt en een vaardigheid toegevoegd om de stofzuigerrobot te besturen.
Andere Alexa-vaardigheden zijn handige dingen, zoals eten bestellen bij verschillende eetgelegenheden of een Uber aanroepen, en willekeurig amusement, zoals magische 8-ball-vragen stellen, Seinfeld-trivia en nieuwe feiten over fruit leren. Samenwerkingen tussen Amazon en bedrijven zoals Whirlpool en GE zullen ook de geschiktheid van Alexa in het slimme huis versterken, door mogelijkheden toe te voegen om huishoudelijke apparaten zoals wasmachines, koelkasten, lampen en meer te bedienen.
Momenteel lijkt Amazon voorop te lopen in deze markt, maar anderen doen enorme inspanningen (en investeringen) om die achterstand in te halen. Mark Zuckerberg rekruteerde Morgan Freeman als de stem van zijn kunstmatige intelligentie (AI) stemassistent. Volgens een notitie waarin wordt beschreven hoe hij het heeft gebouwd, heeft Zuckerberg een jaar besteed aan het ontwikkelen van de applicatie als een eenvoudige AI om zijn huis te helpen “zoals Jarvis in Iron Man” (hij noemde het ook Jarvis). Jarvis identificeert naar verluidt wie er aan het woord is, en herkent ook gezichten, zodat het geautoriseerde mensen aan de deur kan laten terwijl ze rapporteren aan Zuckerberg.
Een andere interessante kanshebber is een Japans Amazon-Echo-achtig apparaat genaamd Gatebox, met een holografisch personage genaamd Azuma Hikari.

Japans antwoord op de Amazon Echo (Bron:Gatebox)
Bovenop een eenvoudige luidspreker maakt het apparaat gebruik van een scherm en een projector om de virtuele assistent zowel visueel als hoorbaar tot leven te brengen. Naast microfoons heeft het ook camera's en bewegings- en temperatuursensoren waarmee het op een meer holistische manier met de gebruiker kan communiceren.
Hoe werkt die far-field spraakopname?
Hoe luistert en begrijpt een apparaat uw spraakopdrachten terwijl het aan de andere kant van de kamer muziek afspeelt? Er zijn veel componenten betrokken bij het mogelijk maken van deze prestatie, maar een paar ervan zijn van het grootste belang. De eerste is de engine voor automatische spraakherkenning (ASR), waarmee machines de geluiden die we maken kunnen omzetten in uitvoerbare instructies. Om de ASR-engine goed te laten werken, moet deze een schoon spraakvoorbeeld ontvangen. Dit vereist ruisonderdrukking en echo-onderdrukking, om de interferenties uit te filteren. De volgende zijn enkele van de belangrijkste technologieën die spraakopname in het verre veld mogelijk maken:
Deep Learning speelt hierin een grote rol. Het vermogen om natuurlijke taal te begrijpen is een aantal jaren geleden ontwikkeld, maar door recente verfijningen komt het dicht bij het vermogen van de mens. Door gebruik te maken van op leren gebaseerde technieken zoals Deep Neural Networks (DNN's), hebben zowel taalverwerking als visuele objectherkenning de menselijke prestaties in veel testgevallen geëvenaard of overtroffen. DNN's worden gegenereerd met behulp van enorme datasets tijdens de trainingsfase. Nadat de training offline is uitgevoerd, worden de DNN's gebruikt om hun functie in realtime uit te voeren.
Adaptieve beamforming is de sleutel voor een robuuste spraakgestuurde gebruikersinterface. Het maakt functies mogelijk zoals ruisonderdrukking, luidsprekertracking voor het geval de gebruiker beweegt tijdens het praten en luidsprekerscheiding voor wanneer meerdere gebruikers tegelijkertijd praten.
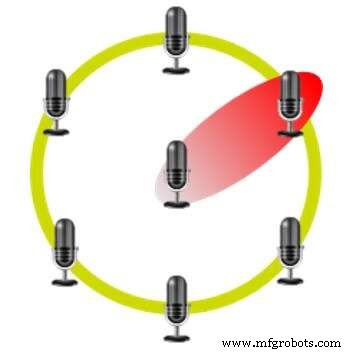
Beamforming met behulp van een zeshoekige microfoonarray (Bron:CEVA)
Deze methode maakt gebruik van meerdere microfoons op vaste posities ten opzichte van elkaar. The Amazon Echo gebruikt bijvoorbeeld zeven microfoons in een zeshoekige lay-out met één microfoon op elk hoekpunt en één in het midden. De tijdsvertraging tussen de ontvangst van het signaal in de verschillende microfoons stelt het apparaat in staat te identificeren waar de stem vandaan komt en geluiden uit andere richtingen te onderdrukken.
Akoestische echo-onderdrukking is noodzakelijk omdat veel van de producten die automatische spraakherkenning uitvoeren ook zelf geluiden produceren; bijvoorbeeld muziek afspelen of informatie geven. Zelfs tijdens het uitvoeren van deze acties moeten de apparaten kunnen horen, zodat de gebruiker de muziek kan onderbreken (barge-in) en kan stoppen of een andere actie kan aanvragen. Om te kunnen blijven luisteren, moet de machine het geluid dat hij zelf genereert kunnen neutraliseren. Dit wordt akoestische echo-onderdrukking (AEC) genoemd.
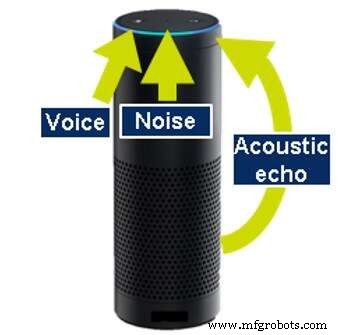
Akoestische echo-onderdrukking (Bron:CEVA)
Om AEC uit te voeren, moet het apparaat zich bewust zijn van het geluid dat het maakt, door de uitvoergegevens te analyseren of door naar de gegenereerde geluiden te luisteren met een extra speciale microfoon. Soortgelijke technologie wordt ook toegepast om echo's te verwijderen die terugkaatsen van muren en andere objecten rond het apparaat.

Een ontwikkelplatform met meerdere microfoons voor het modelleren van DNN's, beamforming en echo-onderdrukkingsalgoritmen (Bron:CEVA)
Een ander type echo wordt gegenereerd door de gebruikerscommando's zelf wanneer ze terugkaatsen van objecten of van de muren. Om dergelijke onvoorspelbare echo's te annuleren, is nog een ander algoritme nodig, dereverberatie genaamd. Het geluid wordt dan gefilterd en de machine kan luisteren naar commando's van de gebruiker.
De spraakinterfaces van tegenwoordig zijn verre van perfect
Enerzijds lijkt 2017 een opmerkelijk jaar te worden voor spraakinterfaces, gezien hoe wijdverbreid ze al zijn geworden. Aan de andere kant, zelfs met alle indrukwekkende vorderingen van de afgelopen jaren, is er nog een lange weg te gaan.
Er blijven veel problemen met de huidige implementaties van spraakinterfaces in massaproductie-apparaten, maar dat zal het onderwerp zijn voor een toekomstige column. In mijn volgende bericht ben ik van plan om te kijken naar enkele van de gebreken en ontbrekende functies die de spraakinterfaces van vandaag teisteren. Zorg ervoor dat je afstemt.
Eran Belaish is Product Marketing Manager van CEVA's audio- en spraakproductlijn en bedenkt voortreffelijke oplossingen, variërend van spraakactivering en mobiele spraak tot draadloze audio en high-definition home-audio. Hoewel hij niet bezig is met de fascinerende wereld van meeslepend geluid, duikt Eran graag in de betoverende stilte van de onderwaterwereld.
Ingebed
- Monroe Engineering CEO is finalist in Entrepreneur of The Year door EY
- De opdrachtregelinterface
- MajorTom:Alexa Voice Controlled ARDrone 2.0
- Motion uitgeroepen tot leverancier van het jaar
- Mobius wint Product of the Year Awards
- 2020 wordt het jaar van continue intelligentie
- CMMS-trends 2019:het jaar van de klant
- Monroe won Business of the Year 2019!
- The Great Wisconsin Chili Cook-Off
- De verenigde stem van de persluchtindustrie
- Een jaaroverzicht:2017