


Fouttolerantie en de impact ervan op de systeembetrouwbaarheid
Apparatuur en systemen die zijn ontworpen zonder fouttolerantie in gedachten, hebben vaak een slechte(re) betrouwbaarheid.
Dit is de reden waarom een fouttolerant systeemontwerp een voor de hand liggende keuze is voor de meeste betrouwbaarheids- en ontwerpingenieurs - vooral als het gaat om kritieke apparatuur waarvan het falen de betrouwbaarheid, beschikbaarheid, onderhoudbaarheid en veiligheid (RAMS) van het hele systeem in gevaar kan brengen. onderdeel van.
Doe met ons mee terwijl we de kenmerken van fouttolerante systemen onderzoeken en manieren bespreken om de fouttolerantie te verbeteren door middel van redundante ontwerpen.
Wat is fouttolerantie?
Fouttolerantie vertegenwoordigt het vermogen van een systeem of apparaat om zijn werking te behouden tijdens de aanwezigheid van een fout.
Systemen en apparatuur met een hoge fouttolerantie kunnen, afhankelijk van het aangenomen fouttolerantiemechanisme, hun werking volledig of gedeeltelijk in stand houden bij het optreden van een fout. Om dit in de praktijk te laten werken, mogen dergelijke systemen geen single point of failure (SPOF) hebben.
De essentie van fouttolerante ontwerpen
De ontwikkeling van een fouttolerant ontwerp vereist een zorgvuldige afweging van storingen die zich gedurende de gehele levenscyclus van de apparatuur kunnen voordoen, samen met hun waarschijnlijke oorzaken en gevolgen.
De ontwerpingenieurs moeten echter ook rekening houden met de kosten en middelen die nodig zijn om het vereiste niveau van tolerantie, betrouwbaarheid en betrouwbaarheid van de apparatuur te bereiken.
Het wordt vaak verkeerd begrepen dat een fouttolerant ontwerp volledige tolerantie moet bieden voor alle soorten fouten. Dit is niet waar. Een goed ontwerp moet overeenkomen met de mate van tolerantie voor de kriticiteit van de fout, zodat de algehele optimalisatie van kosten- en resource-efficiëntie kan worden bereikt.
Het is bijvoorbeeld misschien niet kosteneffectief om geld uit te geven aan het herontwerpen van producten, alleen om een fout op te lossen waarvan de kans extreem klein is dat deze optreedt.
Kenmerken van fouttolerante systemen
Om een fouttolerant systeem te creëren, zijn inspanningen vereist in elke fase van de levenscyclus van de apparatuur. Dit omvat, maar is niet beperkt tot, de specificatie- en ontwerpfase (inclusief foutdetectiecontroles in het ontwerp), validatie en verificatie (V&V), onderhoud en bediening (gebruikmakend van OEM-goedgekeurde vervangende onderdelen en richtlijnen voor routineonderhoud), en zelfs de verwijderingsfase .
Elke fase kan combinaties van de hieronder vermelde technieken gebruiken om nieuwe ontwerpen te ontwikkelen of huidige te verbeteren om hun niveau van fouttolerantie te verbeteren:
- foutdetectie en weergave
- foutdiagnose en -beheersing
- foutmaskering en compensatie
1) Foutdetectie en weergave
Foutdetectie verwijst naar het vermogen van het systeem/de apparatuur om de fout te detecteren en weer te geven. Het is het fundamentele aspect van elk fouttolerant systeem . Alle andere aspecten zijn afhankelijk van de effectiviteit van het foutdetectieproces. Als het systeem niet is ontworpen om zijn fout te detecteren, of op de een of andere manier een fout detecteert, zullen de rest van de aspecten ook niet effectief zijn.
Een eenvoudige luchtdruksensor in een autobandenspanningscontrolesysteem (TPMS) kan bijvoorbeeld de luchtovervulling detecteren en de bestuurder hiervan op de hoogte stellen via het dashboard van de auto.
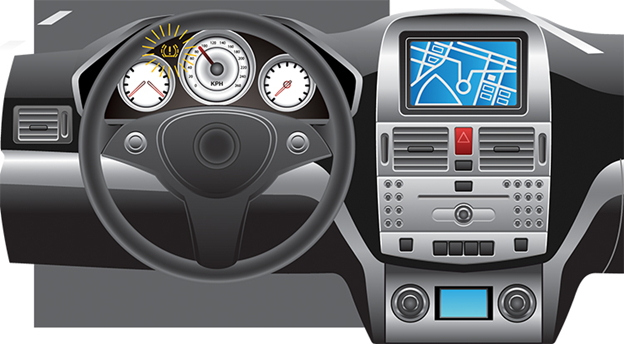
Een weergave van TPMS-activering
In dit geval is de detectie en weergave het enige acceptabele tolerantieniveau voor deze foutgebeurtenis. De klant kan de luchtslang veilig losmaken voordat de band scheurt.
Als de drukdetectie onnauwkeurig is, kan de bestuurder de slang te vroeg/laat loskoppelen en tijdens het rijden bandenpech krijgen. Aangezien er geen automatische correctie van de luchtdruk is, is het tolerantieaspect voor deze fout beperkt tot alleen detectie en weergave.
2) Foutdiagnose en -beheersing
In meer geavanceerde systemen worden vaak extra lagen toegevoegd in de productontwerpfase. Hun doel is om naast detectie en weergave een diagnose te stellen en insluiting uit te voeren. Deze extra lagen zijn gerechtvaardigd vanwege de kriticiteit van het systeem of vanwege verschillende veiligheidsproblemen.
Een Distributed Control System (DCS) - een besturingssysteem voor procesinstallaties - bewaakt bijvoorbeeld niet alleen kritieke procesparameters via een reeks sensoren, maar voert ook een diagnose uit om de locatie van de fout te detecteren en de noodzakelijke inperking uit te voeren.
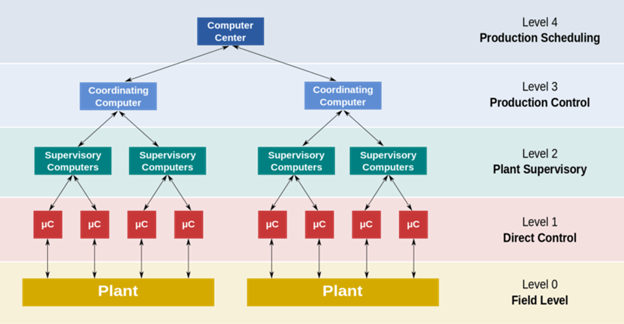
Een weergave van het DCS-systeem
Zo wordt bij overdruk van aardolieproducten in een vat het systeem getriggerd door relevante druksensoren. Het opent de veiligheidsdrukklep en voert de dampen uit in de fakkelpijp.
In dit voorbeeld wordt de insluiting uitgevoerd door de ontvlambare damp onder hoge druk naar de uitlaatpijp te leiden, waardoor het systeem wordt beschermd tegen brand of explosie.
3) Foutmaskering en compensatie
Een andere effectieve benadering van fouttolerantie is het maskeren van de foutstatus. Het is zeer effectief voor apparatuur die kan worden gecontroleerd en bestuurd via de Internet of Things (IoT)-technologie.
Met dergelijke apparatuur komt een van de grootste uitdagingen in de vorm van cyberbeveiligingsbedreigingen. Dit soort bedreigingen kan proberen de fout te veroorzaken door de toestand van de apparatuur te wijzigen door valse apparatuurgegevens in de server te injecteren.
Met onjuiste gegevens over de staat van de apparatuur, kan het controle- en bewakingssysteem dat oorspronkelijk bedoeld was om te beschermen, in plaats daarvan het falen van het activum veroorzaken. Als alternatief kan het worden "misleid" door te denken dat het activum in goede staat verkeert, terwijl dit in werkelijkheid niet het geval is - waardoor de verslechtering tot een storing kan leiden zonder waarschuwingen te activeren.
Door foutmaskering op te nemen, is het systeem zo ontworpen dat het die onjuiste waarden kan herkennen en maskeren.
In de elektriciteitsnetten worden de stroomonderbrekers bijvoorbeeld vaak aangestuurd en bewaakt door middel van Supervisory Control and Data Acquisition (SCADA).
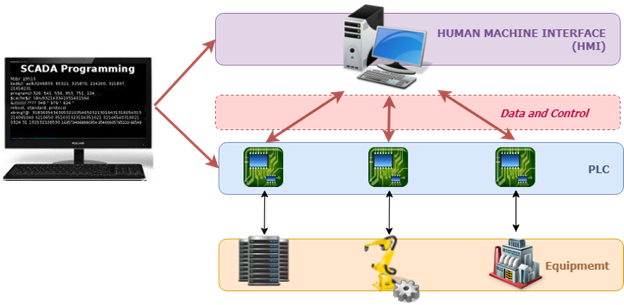
Een weergave van het SCADA-systeem
Een dergelijk systeem houdt de spannings- en frequentieparameters van de elektrische apparatuur nauwlettend in de gaten en zorgt ervoor dat ze sluiten of openen om de stabiliteit van het stroomnetwerk te behouden.
Een inkomende cyberaanval kan de spannings- en frequentielimieten op de apparatuur wijzigen. Gevolgen? Het systeem kan een stroomstoring veroorzaken in plaats van te voorkomen.
Foutmaskering wordt vaak uitgevoerd door middel van algoritmen die afwijkende gegevensstromen detecteren en valse gegevens injecteren met als doel de gegevens te maskeren die de defecte toestand van de apparatuur vertegenwoordigen. Dit voorkomt dat de slechte data-actoren de fout verspreiden en de betrouwbaarheid van het netwerk verder verergeren.
Fouttolerantie verbeteren door redundante ontwerpen
Een van de eenvoudige acties die kunnen worden ondernomen om de fouttolerantie te vergroten, is door redundanties in het ontwerp op te nemen. Redundantie betekent simpelweg de aanwezigheid van een alternatief systeem of oplossing die de beoogde functie kan overnemen als het primaire systeem uitvalt.
Hoewel redundantie de fouttolerantie verbetert, zou het lukraak toevoegen van systemen niet het doel moeten zijn, aangezien de kosten die nodig zijn om een nieuw systeem toe te voegen aanzienlijk groter kunnen zijn dan het haalbare betrouwbaarheidsvoordeel.
Vanuit het perspectief van fysieke apparatuur kunnen ze grofweg worden geclassificeerd als actief of passieve ontslagen .
Actieve ontslagen
Actieve redundanties kunnen tot stand worden gebracht wanneer meerdere apparaten tegelijkertijd worden bediend. In deze configuratie draagt elk apparaat zijn aandeel bij aan het bereiken van de beoogde functie, terwijl het nog steeds als redundantie voor elkaar fungeert.
Een simplistische actieve redundantie is de parallelle werking van twee pompen op de helft van hun nominale capaciteit. Beide pompen werken samen om de gewenste afvoerdruk te bereiken. Als een pomp uitvalt, kan de andere pomp nog steeds worden opgevoerd tot zijn nominale capaciteit om zelf de beoogde afvoerdruk te bereiken. Om een economisch ontwerp te realiseren, hebben de betrouwbaarheidsingenieurs verschillende andere gecompliceerde manieren bedacht om actieve redundanties te bereiken, zoals K of N-redundanties en sierlijke degradatie.
In K van N ontslagen , is een bepaalde subset van apparatuur altijd in bedrijf. Dit verhoogt de betrouwbaarheid van het systeem, aangezien een deel van de apparatuur nog steeds in stand-by staat en kan worden ingeschakeld als bepaalde apparatuur uitvalt. Dit garandeert een grotere betrouwbaarheid in vergelijking met de eenvoudige parallelle werking van twee pompen, aangezien er een groter aantal kleine pompen zal werken.
Sierlijke degradatie is een alternatief voor het toevoegen van dure identieke en parallelle systemen. Het zorgt ervoor dat de kenmerken of functionaliteit van de algehele apparatuur evenredig verslechtert met het aantal defecte componenten. Om een dergelijke schaalbare degradatie te bereiken, moet een onderzoek worden uitgevoerd naar alle mogelijke storingen binnen alle componenten. Hun impact op de prestaties van het algehele systeem moet worden geanalyseerd en gedocumenteerd.
Dergelijke technieken bieden tolerantie voor gedeeltelijke storingen en stellen het systeem in staat zijn functie voort te zetten met een verminderde capaciteit.
Passieve ontslagen
Passieve redundantie is de standby-redundantie waarbij de alternatieve apparatuur aanwezig is, maar deze kan alleen de beoogde functie overnemen bij uitval van de primaire apparatuur.
We kunnen twee soorten passieve ontslagen onderscheiden:
- passieve ontslagen uitvoeren
- niet-operationele passieve ontslagen
Passieve ontslagen uitvoeren zijn degenen waar de alternatieve apparatuur als hot spare aanwezig is. De stand-byapparatuur is heet omdat deze mogelijk onbelast werkt. In sommige gevallen kan het een functie vervullen die buiten de definitie van de functie van de primaire apparatuur valt.
Bij uitval van de primaire apparatuur kan de werkende standby-apparatuur automatisch worden overgezet naar het uitvoeren van de functie van primaire apparatuur.
Een voorbeeld van werkende passieve redundanties kan een secundaire dynamo zijn die werkt onder onbelaste omstandigheden en voldoet aan alle andere parallelle voorwaarden, zoals dezelfde klemspanning, frequentie en fasevolgorde. Bij uitval van de primaire dynamo kan de secundaire dynamo automatisch worden gesynchroniseerd met het systeem en de belasting overnemen.
In het geval van niet-operationele passieve ontslagen , wordt de stand-byapparatuur uitgeschakeld. Bij uitval van primaire apparatuur kan de standby-apparatuur automatisch of handmatig worden ingesteld op bedrijfsomstandigheden en de functionaliteit van primaire apparatuur overnemen.
Een goed voorbeeld van niet-werkende passieve redundantie is een stand-by gemeentelijke waterpomp die handmatig kan worden gestart en bediend om water te leveren aan bewoners als de primaire waterpomp defect raakt. Aangezien het herstel van de werking niet van cruciaal belang is, kan een operator de pomp gaan starten (en indien nodig later synchroniseren met het systeem).
Betrouwbaarheidstechnieken voor het analyseren van fouttolerantie
Fouttolerantie maakt deel uit van de inspanningen van de betrouwbaarheidsengineering en vereist een zorgvuldig onderzoek van alle mogelijke storingen die binnen de apparatuur kunnen optreden. De Failure Mode Effect Analysis (FMEA) en de Fault Tree Analysis (FTA) zijn twee bekende technieken om systeemontwerp te analyseren vanuit respectievelijk bottom-up en top-down benaderingen.
Om tolerantie beter te begrijpen, moeten de faalvolgorde en afhankelijkheden worden geanalyseerd en onderzocht. Een bijzonder bruikbare techniek om afhankelijkheden en volgorde te analyseren, is het Markov-model, waarbij de kans op een storingsgebeurtenis zou afhangen van de toestand van de vorige gebeurtenis.
Evenzo is een andere krachtige techniek Monte Carlo-simulaties die kunnen worden gebruikt om de impact van onzekerheden van een storingsgebeurtenis op de systeemprestaties te modelleren.
Fouttolerantie en onderhoudswerkzaamheden
Hebben fouttolerante systemen minder onderhoud nodig? Nou ja en nee.
Vanwege redundanties en andere kenmerken die we eerder hebben besproken, kunnen dergelijke systemen meestal meer fouten opnemen voordat hun functionaliteit in gevaar komt. Als de problemen echter niet worden aangepakt, zal de opeenstapeling van fouten uiteindelijk leiden tot een systeem- of apparatuurstoring. Daarom moeten onderhoudsteams een CMMS-systeem gebruiken om ervoor te zorgen dat correctieve onderhoudsacties tijdig worden ondernomen.
In zekere zin geeft fouttolerantie onderhouds- en ondersteuningsteams meer ademruimte. Ze moeten het probleem nog steeds oplossen, maar misschien niet meteen.
Hoewel fouttolerante ontwerpen hun uitdagingen hebben in termen van hogere kosten en complexiteit, maken ze dit goed in de vorm van verbeterde betrouwbaarheid van de apparatuur.
Onderhoud en reparatie van apparatuur
- COVID 19 en Cloud; COVID 19 en de impact ervan op bedrijven
- Onderhoud en betrouwbaarheid beste prestaties
- Onderhoud en betrouwbaarheid - goed genoeg is nooit
- Details zijn belangrijk voor onderhoud en betrouwbaarheid
- Onderhoud en betrouwbaarheid Leveranciers:Let op koper
- Flexibele productie en betrouwbaarheid kunnen naast elkaar bestaan
- Entropie toepassen op onderhoud en betrouwbaarheid
- UT hernoemt programma naar Reliability and Maintenance Center
- Een kajakkersperspectief op betrouwbaarheid en veiligheid
- ISA publiceert boek over veiligheid en betrouwbaarheid van controlesystemen
- Tips om een succesvol en goed onderhouden septisch systeem te behouden