


Betrouwbaarheid en beschikbaarheid:hoe kom je er met FMEA's en PF-curves
Voor organisaties die last hebben van onverwachte storingen en ongeplande downtime, kan Failure Modes and Effects Analysis (FMEA) helpen bij het bereiken van een hoge betrouwbaarheid en beschikbaarheid van activa.
U krijgt de juiste betrouwbaarheid en beschikbaarheid, en u bent al een heel eind op weg naar winstgevendheid.
Maar hier is een verrassing.
Veel organisaties en fabrikanten maken deze reis nooit en gaan vrolijk verder (als een bruikbaar product op tijd bij de klant is ) in een neerwaartse spiraal.
'Maar die reis waar je het over hebt is RCM!' roepen ze. ‘Veel te duur voor ons!’
Dezelfde fabrikanten lijken altijd tijd (en geld) te hebben om verspild product te schrappen, nieuwe lagers te kopen, olievlekken op te ruimen, machines te repareren, OEM's (Original Equipment Manufacturer) in te schakelen, en ervoor te zorgen dat mensen overwerken. En één keer per jaar - met veel tamtam en ceremonie - reiken ze een prijs uit aan reactieve onderhoudshelden.
Hmmm.
Je denkt:'Mensen krijgen hun foto in de bedrijfsnieuwsbrief, een handdruk van de VP om de fabriek in reactief onderhoud te houden ?'.
Ja, dat doen ze. Maar laten we verder gaan.
Voor een goede betrouwbaarheid van assets en hoge beschikbaarheid is geen volledig RCM-onderzoek nodig. Maar het vereist wel een goede FMEA (Failure Mode &Effect Analysis) met goede output, en de toepassing van P-F (Potential Failure to Functional failure)-curves om ervoor te zorgen dat conditiebewakingstechnieken zijn gericht op de juiste faalwijzen met de juiste inspectiefrequentie.
Failure Modes &Effects Analysis:tot op de bodem (of top) van dingen komen
Een FMEA is een veelgebruikte analysetool die ontwerpers, technici en ingenieurs helpt te begrijpen hoe een kritiek onderdeel of onderdeel kan falen, welk effect dit heeft op het algehele systeem en wat ze kan doen om de effecten te verzachten.
De essentie van een FMEA is het begrijpen van de faalwijzen, hoe groot de kans is dat ze optreden, en deze te verminderen met specifieke onderhoudsacties, herontwerpen of zelfs 'niets doen' (als de risico is laag genoeg).
FMEA's zijn er in twee basistypen.
Bottom up - deze FMEA begint met het opsommen van elk onderdeel in een asset en het opsommen van alle mogelijke manieren waarop het kan mislukken. Het wordt vaak de ‘hardwarebenadering’ genoemd. Dit type FMEA is arbeidsintensiever, maar wordt vaak gebruikt in sectoren met hoge veiligheid en milieugevolgen, zoals luchtvaart en nucleair.
Onverwachte activastoringen kunnen in deze sectoren niet worden getolereerd.
Top-down – dit type FMEA (ook bekend als de ‘functionele benadering’) komt vaker voor en – ja, je raadt het al – kijkt eerst naar de functies van het actief. Als functies bekend zijn, vragen we ons af 'hoe kan het functioneel falen?' Dit leidt ons naar faalwijzen en het zoeken naar effecten en mitigerende acties.
Een top-down FMEA pakt rechtstreeks alleen de belangrijkste bijdragers aan potentiële problemen aan, in plaats van elk afzonderlijk onderdeel.
Er zijn ook FMECA's (C voor kriticiteit) die een numerieke risicofactor toevoegen.
Bekijk dit voorbeeld dat een FMEA en een FMECA omvat.
We houden het simpel en kijken naar de ruitenwissers van een auto. We gaan ervan uit dat we in eerste instantie geen controles doen en dat we ze gewoon laten mislukken terwijl we verder rijden.
Functie | Functioneel falen | Failure Mode | Potentiële impact | Ernst | Potentiële oorzaken | Voorkomen | Detectiemodus | Detectie | RPN |
| Wat is de functie van het activum of onderdeel? | Hoe kan het zijn functie niet vervullen? | Wat kan een functionele storing veroorzaken? | Wat is de impact? d.w.z. de effecten | Hoe ernstig is het effect? | Wat veroorzaakt de storingsmodus? | Hoe vaak zal dit waarschijnlijk voorkomen? | Wat zijn de bestaande controles voor preventie of detectie? | Hoe gemakkelijk is het te detecteren met de huidige methoden? | Risicoprioriteitgetal =Sev x Occ x Det. |
| Om regen en mist van de voorruit te verwijderen (op aanvraag). | Kan niet starten. | Zekering doorgebrand. | Auto kan de voorruit niet wissen bij hevige regen. | 10 | Vuil dat de ruitenwissers blokkeert (veroorzaakt overstroom en gesprongen zekering) | 2 | Zoek op storing (tijdens het rijden) | 7 | 140 |
Aanbevolen acties | Verantwoordelijkheid | Doeldatum | Genomen actie | SEV | OCC | DET | RPN |
Hoe verminderen we het optreden van de oorzaak of verbeteren we de detectie? | Wie is verantwoordelijk voor de actie? | Wat is de streefdatum voor de actie? | Bereken de RPN opnieuw om te zien of de actie het risico heeft verminderd. |
|
|
| Nieuwe RPN na acties. |
1. Inspecteer de ruitenwissers voor elke rit op obstakels. 2. Neem een vervangende zekering mee. | Auto-eigenaar | Met onmiddellijke ingang | Checklist meegenomen in de auto als herinnering. En vervangende zekeringen. | 10 | 2 | 2 | 40 |
Zoals u kunt zien, moet uw risicoprioriteit na het implementeren van acties afnemen.
Zodra u een FMEA of FMECA op uw installatie uitvoert, heeft u een onderhoudsstrategie.
Onderhoudsstrategie:het helpt u de inherente betrouwbaarheid te behouden.
De belangrijkste output van een FMEA is dus een onderhoudsstrategie, voornamelijk in termen van wat je moet. Dit kunnen onder meer op tijd gebaseerde vervangingen, conditiebewaking, herontwerp van apparatuur, storingzoekende taken, inspecties of revisies zijn.
Om uw onderhoudsstrategie verder te verfijnen en later te implementeren, moet u beslissen wie het werk gaat doen, wanneer en welke reserveonderdelen nodig zijn.
Dit is wat je moet onthouden:
Door het juiste onderhoud op het juiste moment uit te voeren, kunt u de inherente behouden betrouwbaarheid van het actief op een hoog niveau. Correct en correct onderhoud alleen kan nooit verbeteren de inherente betrouwbaarheid die verder gaat dan de oorspronkelijke capaciteit - omdat het een ingebouwde . is karakteristiek.
Maar een goede onderhoudsstrategie kan de inherente betrouwbaarheid hoog houden waar deze thuishoort.
Conditiebewaking en op conditie gebaseerd onderhoud:beschikbaarheid is koning.
Laten we ons even concentreren op de tactieken voor conditiebewaking (ook bekend als Predictive Maintenance). Dit is de moeite waard omdat hun sensoren, gegevens en informatie ons in staat stellen de gezondheid van de activa te begrijpen. Zij zijn de drijvende kracht achter het industriële internet of things (IIoT) en industrie 4.0.
Als we de gezondheid van activa op elk moment begrijpen, kunnen we dat meest kosteneffectieve van alle onderhoud uitvoeren:condition-based maintenance (CBM) .
Dit is wat je moet onthouden:
Conditiegebaseerd onderhoud verbetert de betrouwbaarheid niet en zal de activa niet verbeteren , inherent of anderszins. Wat het u oplevert en wat net zo belangrijk is voor uw organisatiedoelstellingen, is beschikbaarheid asset . Alleen al door ongeplande uitvaltijd te verminderen, verhoogt u de beschikbaarheid.
CBM voert een reparatie- of vervangingstaak uit uitsluitend op basis van de gemeten gezondheid van een asset. Het geeft ons een vroeg waarschuwingssignaal van mogelijke of dreigende uitval van activa of componenten.
Maar als we conditiebewakingstechnieken gebruiken, hoe vaak moeten we dan gegevens meten?
P-F-curve en intervallen
Ten eerste, wat is deze P-F-curve waar we het over hebben? Het is een curve die aangeeft hoe de gezondheid van een asset in de loop van de tijd verslechtert zodra een faalmodus in gang wordt gezet.
Het diagram hier illustreert het concept.
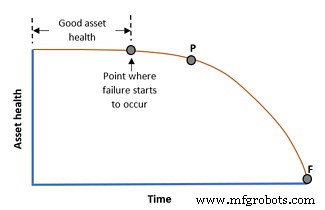
Het horizontale deel van de curve is een goede asset-gezondheid. Dit gedeelte kan worden verlengd door best practices voor onderhoud in:
- Installatie van activa
- Funderingen en ondersteunende structuren
- Asset-smering
- Uitlijning en balancering van activa
- Correcte werking binnen de mogelijkheden van het item
Maar wanneer een storingsmodus zich voordoet, hebben we een punt waarop de storing is begonnen. Maar het is nog steeds onzichtbaar tijdens het verzamelen van gegevens.
Vervolgens gaat de tijd (of de cycli van activastress) verder naar punt P.
Het punt P betekent Potentieel falen . Dit is waar onze conditiebewakingstechnieken kunnen beginnen met het detecteren van een mogelijke storing. Dan zal de gezondheid van de activa geleidelijk (of snel) verslechteren totdat het punt F bereikt, de Functionele Mislukking .
Dat betekent welterusten en tot ziens voor uw bezit.
Het spel is afgelopen en je moet de reactieve onderhoudshelden roepen.
Het tijdsverschil tussen P en F staat bekend als het P-F-interval. Het kan seconden tot decennia zijn. Het hangt allemaal af van de faalwijze en de asset in kwestie.
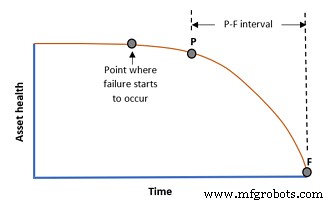
U doet er goed aan te onthouden dat het PF-interval voor een specifieke storingsmodus altijd een gemiddelde is nummer – deze dingen zullen altijd statistische variatie hebben.
Maar als we een goed idee hebben van wat het is - van eerdere storingen, RCA's (Root Cause Analysis), OEM-gegevens, enz. - dan kunnen we het interval instellen waarop wij voeren condition monitoring inspecties uit. Een goede vuistregel voor een inspectie-interval is meestal ten minste de helft van het verwachte P-F-interval.
Stel je voor dat je weet dat wanneer je kritieke eindlager van de pompaandrijving trilt met 8 mm/sec, het waarschijnlijk nog maar 3 maanden dienst heeft voordat het vastloopt. Hoe vaak moet u de trilling minimaal meten?
Inspectie-/meetinterval 
Dit zorgt ervoor dat u dat specifieke defect binnen het verwachte P-F-interval vastlegt (hoewel de meeste strategen hier conservatief en algemeen inspectie-intervallen van 1 maand zouden aanbevelen - weet u nog de statistische variatie? ).
Het is algemeen aanvaard dat verschillende technieken voor conditiebewaking verschillende niveaus van vroegtijdige waarschuwing kunnen bieden tijdens het PF-interval. Bekijk het onderstaande diagram voor een ruwe handleiding. Geen enkele techniek is een oplossing voor alle faalwijzen.
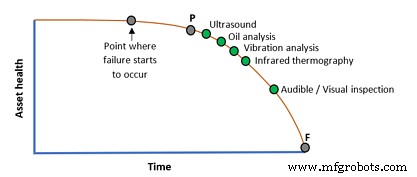
De beste strategieën maken gebruik van een combinatie van conditiebewakingstechnologieën.
De reis naar voorgeschreven onderhoud
Als laatste opmerking, gezien de voortgang van IIoT en industrie 4.0, moeten we de reis naar prescriptief onderhoud overwegen.
| Prescriptief onderhoud (Rx) is uniek omdat het, in plaats van alleen een dreigende storing te voorspellen, zoals voorspellend onderhoud (PdM), ernaar streeft om resultaatgerichte aanbevelingen voor operaties en onderhoud te produceren op basis van de Rx-analyses. Hoewel RxM nog in de kinderschoenen staat, overwegen veel opinieleiders het potentieel ervan om het volgende niveau van best practice op het gebied van betrouwbaarheid en onderhoud te worden.
|
'Maar wat is dat? ?' horen we u vragen.
Dus de volgende grens die verder gaat dan voorspellend onderhoud, is prescriptief onderhoud.
Kun je je inbeelden Dat?
Sensoren, netwerken, algoritmen, machine learning en AI combineren om uw onderhoudsteam te informeren over wat ze moeten doen en wanneer ze moeten het doen om de betrouwbaarheid te behouden en de beschikbaarheid te vergroten. Of zelfs hoe het activum (snelheden en belastingen) moet worden beheerd om de resterende levensduur te verlengen zodra een mogelijke storing wordt gedetecteerd.
Onderhoudsstrategieën van de toekomst zullen vloeiend, veranderlijk en intelligent zijn door technologie en door mensen gemaakte FMEA's, P-F-intervallen en OEM-handleidingen voor probleemoplossing.
We zijn er nog niet, maar het komt eraan...
Lees volgende:Uitgebreide handleiding voor IIoT in onderhoud
Internet of Things-technologie
- Hoe de huidige datum en tijd in Python te krijgen?
- Hoe een investering in onderhoud en betrouwbaarheid te rechtvaardigen
- Hoe bewegwijzering en etikettering de betrouwbaarheid kunnen verbeteren
- Betrouwbaarheid verhogen en onderhoudsresultaten verbeteren met machine learning
- Hoe kan IoT kinderen met ASS helpen om te leren en te spelen?
- Hoe IOT echt te maken met Tech Data en IBM Part 2
- Hoe maak je IoT echt met Tech Data en IBM Part 1
- Aan de slag met internationale verzending
- Belangrijkste oorzaken van machinestoringen en hoe ze te voorkomen
- De beschikbaarheid van machines berekenen en verbeteren
- Aan de slag met Yaskawa-robotprogrammering