


Hoe analoge in-memory computing power-uitdagingen van edge AI-inferentie kan oplossen
Machine learning en deep learning zijn al een integraal onderdeel van ons leven. Toepassingen van kunstmatige intelligentie (AI) via Natural Language Processing (NLP), beeldclassificatie en objectdetectie zijn diep verankerd in veel van de apparaten die we gebruiken. De meeste AI-applicaties worden bediend via cloudgebaseerde engines die goed werken voor waar ze voor worden gebruikt, zoals het krijgen van woordvoorspellingen bij het typen van een e-mailreactie in Gmail.
Hoezeer we ook genieten van de voordelen van deze AI-toepassingen, deze aanpak introduceert uitdagingen op het gebied van privacy, stroomdissipatie, latentie en kosten. Deze uitdagingen kunnen worden opgelost als er een lokale verwerkingsengine is die in staat is om gedeeltelijke of volledige berekeningen (inferentie) uit te voeren aan de oorsprong van de gegevens zelf. Dit was moeilijk te doen met traditionele digitale neurale netwerkimplementaties, waarin geheugen een op energie beluste bottleneck wordt. Het probleem kan worden opgelost met geheugen op meerdere niveaus en het gebruik van een analoge in-memory rekenmethode die, samen, verwerkingsengines in staat stelt te voldoen aan de veel lagere vermogensvereisten van milliwatt (mW) tot microwatt (uW) voor het uitvoeren van AI-inferentie op de rand van het netwerk.
Uitdagingen van cloud computing
Wanneer AI-applicaties worden bediend via cloudgebaseerde engines, moet de gebruiker enkele gegevens (gewild of onwillig) uploaden naar clouds waar computerengines de gegevens verwerken, voorspellingen doen en de voorspellingen stroomafwaarts naar de gebruiker sturen om te consumeren.

Figuur 1:Gegevensoverdracht van Edge naar Cloud. (Bron:Microchip Technology)
De uitdagingen die met dit proces gepaard gaan, worden hieronder beschreven:
- Privacy- en beveiligingsproblemen: Met always-on, always-aware apparaten bestaat de zorg dat persoonlijke gegevens (en/of vertrouwelijke informatie) worden misbruikt, hetzij tijdens uploads, hetzij tijdens de houdbaarheid ervan in datacenters.
- Onnodige vermogensdissipatie: Als elk databit naar de cloud gaat, verbruikt het stroom van hardware, radio's, transmissie en mogelijk ongewenste berekeningen in de cloud.
- Latentie voor gevolgtrekkingen in kleine batches: Soms kan het een seconde of langer duren om een reactie te krijgen van een cloudgebaseerd systeem als de gegevens afkomstig zijn van de edge. Voor de menselijke zintuigen is iets meer dan 100 milliseconden (ms) latentie merkbaar en kan vervelend zijn.
- Data-economie moet logisch zijn: Sensoren zijn overal, en ze zijn zeer betaalbaar; ze produceren echter veel gegevens. Het is niet economisch om alle gegevens naar de cloud te uploaden en te laten verwerken.
Om deze uitdagingen op te lossen met behulp van een lokale verwerkingsengine, moet het neurale netwerkmodel dat de inferentiebewerkingen uitvoert eerst worden getraind met een bepaalde dataset voor de gewenste use case. Over het algemeen vereist dit veel reken- (en geheugen) bronnen en rekenkundige bewerkingen met drijvende komma. Als gevolg hiervan moet het trainingsgedeelte van een machine learning-oplossing nog steeds worden gedaan op openbare of private clouds (of een lokale GPU, CPU, FPGA-farm) met een dataset om een optimaal neuraal netwerkmodel te genereren. Zodra het neurale netwerkmodel gereed is, kan het model verder worden geoptimaliseerd voor lokale hardware met een kleine computerengine, omdat het neurale netwerkmodel geen back-propagatie nodig heeft voor inferentiebewerking. Een inferentie-engine heeft over het algemeen een zee van Multiply-Accumulate (MAC)-engines nodig, gevolgd door een activeringslaag zoals rectified linear unit (ReLU), sigmoid of tanh, afhankelijk van de complexiteit van het neurale netwerkmodel en een poolinglaag tussen de lagen.
De meeste neurale netwerkmodellen vereisen een enorme hoeveelheid MAC-bewerkingen. Zelfs een relatief klein '1.0 MobileNet-224'-model heeft bijvoorbeeld 4,2 miljoen parameters (gewichten) en vereist 569 miljoen MAC-bewerkingen om een inferentie uit te voeren. Aangezien de meeste modellen worden gedomineerd door MAC-bewerkingen, ligt de focus hier op dit deel van de machine learning-berekening - en het verkennen van de mogelijkheid om een betere oplossing te creëren. Een eenvoudig, volledig verbonden tweelaags netwerk wordt hieronder geïllustreerd in figuur 2.
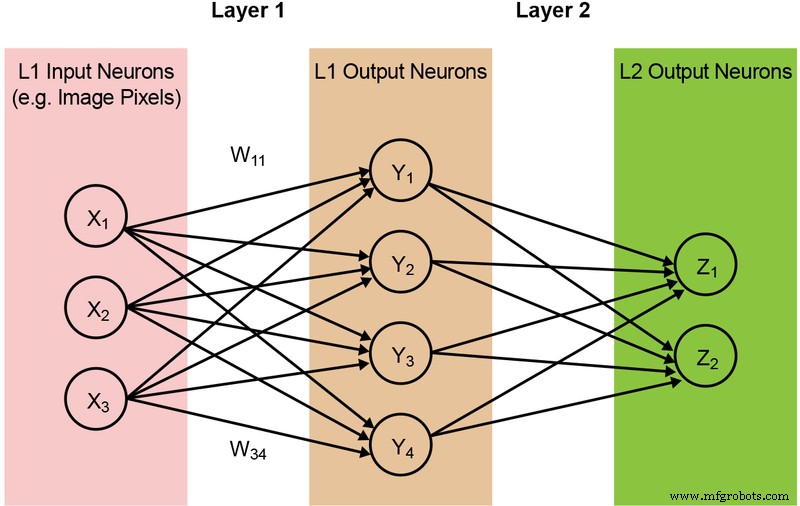
Figuur 2:Volledig verbonden neuraal netwerk met twee lagen. (Bron:Microchip Technology)
De inputneuronen (data) worden verwerkt met de eerste laag gewichten. De outputneuronen van de eerste lagen worden vervolgens verwerkt met de tweede laag met gewichten en geven voorspellingen (laten we zeggen of het model in staat was om een kattengezicht in een bepaalde afbeelding te vinden). Deze neurale netwerkmodellen gebruiken het 'a dot-product' voor de berekening van elk neuron in elke laag, geïllustreerd door de volgende vergelijking (ter vereenvoudiging de term 'bias' in de vergelijking weglatend):
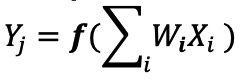
Geheugen Knelpunt bij digitale computers
In een implementatie van een digitaal neuraal netwerk worden de gewichten en invoergegevens opgeslagen in een DRAM/SRAM. De gewichten en invoergegevens moeten worden verplaatst naar een MAC-engine voor gevolgtrekking. Zoals te zien is in afbeelding 3 hieronder, resulteert deze benadering erin dat het grootste deel van het vermogen wordt gedissipeerd bij het ophalen van modelparameters en invoergegevens naar de ALU waar de eigenlijke MAC-bewerking plaatsvindt.
Afbeelding 3:Geheugenknelpunt bij computergestuurde computerleren. (Bron:Y.-H. Chen, J. Emer en V. Sze, "Eyeriss:A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks", in ISCA, 2016.)
Om dingen in een energetisch perspectief te plaatsen:een typische MAC-bewerking met digitale logische poorten verbruikt ~ 250 femtojoule (fJ, of 10 −15 joule) aan energie, maar de energie die wordt gedissipeerd tijdens gegevensoverdracht is meer dan twee ordes van grootte dan de berekening zelf en ligt in het bereik van 50 picojoule (pJ, of 10 −12 joule) tot 100 pJ. Om eerlijk te zijn, er zijn veel ontwerptechnieken beschikbaar om de gegevensoverdracht van geheugen naar ALU te minimaliseren; het hele digitale schema wordt echter nog steeds beperkt door de Von Neumann-architectuur - dus dit biedt een grote kans om verspild vermogen te verminderen. Wat als de energie voor het uitvoeren van een MAC-bewerking kan worden teruggebracht van ~100pJ tot een fractie van pJ?
Geheugenknelpunt verwijderen met analoge in-memory computing
Het uitvoeren van inferentiebewerkingen aan de rand wordt energiezuinig wanneer het geheugen zelf kan worden gebruikt om de benodigde rekenkracht te verminderen. Het gebruik van een in-memory rekenmethode minimaliseert de hoeveelheid gegevens die moet worden verplaatst. Dit elimineert op zijn beurt de energie die wordt verspild tijdens gegevensoverdracht. Energiedissipatie wordt verder geminimaliseerd met behulp van flitscellen die kunnen werken met een ultralage actieve vermogensdissipatie en bijna geen energiedissipatie in de standby-modus.
Een voorbeeld van deze aanpak is de memBrain™-technologie van Silicon Storage Technology (SST), een bedrijf van Microchip Technology. Gebaseerd op SuperFlash ® . van SST geheugentechnologie, omvat de oplossing een in-memory computing-architectuur waarmee berekeningen kunnen worden uitgevoerd waar de gewichten van het inferentiemodel worden opgeslagen. Dit elimineert de geheugenknelpunt bij MAC-berekening, aangezien er geen gegevensverplaatsing is voor de gewichten - alleen invoergegevens hoeven van een invoersensor zoals een camera of microfoon naar de geheugenarray te gaan.
Dit geheugenconcept is gebaseerd op twee fundamenten:(a) Analoge elektrische stroomrespons van een transistor is gebaseerd op de drempelspanning (Vt) en de invoergegevens, en (b) de huidige wet van Kirchhoff, die stelt dat de algebraïsche som van stromen in een netwerk van conducteurs die op een punt samenkomen is nul.
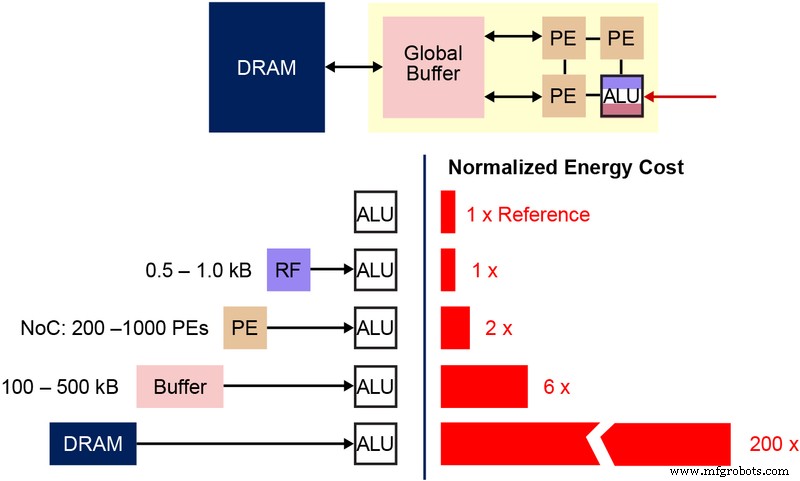
Het is ook belangrijk om de fundamentele niet-vluchtige geheugen (NVM) bitcel te begrijpen die wordt gebruikt in deze multi-level geheugenarchitectuur. Het onderstaande diagram (Figuur 4) is een dwarsdoorsnede van twee ESF3 (Embedded SuperFlash 3 rd generatie) bitcellen met gedeelde Erase Gate (EG) en Source Line (SL). Elke bitcel heeft vijf terminals:Control Gate (CG), Work Line (WL), Erase Gate (EG), Source Line (SL) en Bitline (BL). Wisbewerking op de bitcel wordt gedaan door hoogspanning op EG aan te brengen. De programmering gebeurt door het toepassen van hoog-/laagspanningsbiassignalen op WL, CG, BL en SL. De leesbewerking wordt uitgevoerd door laagspanningsbiassignalen toe te passen op WL, CG, BL en SL.
Figuur 4:SuperFlash ESF3-cel. (Bron:Microchip Technology)
Met deze geheugenarchitectuur kan de gebruiker de geheugenbitcellen op verschillende Vt-niveaus programmeren door middel van fijnmazige programmeerbewerkingen. De geheugentechnologie maakt gebruik van een slim algoritme om de zwevende poort (FG) Vt van de geheugencel af te stemmen om een bepaalde elektrische stroomrespons van een ingangsspanning te bereiken. Afhankelijk van de vereisten van de eindtoepassing, kunnen de cellen worden geprogrammeerd in een lineair of subdrempelig werkgebied.
Figuur 5 illustreert de mogelijkheid om meerdere niveaus op de geheugencel op te slaan en te lezen. Laten we zeggen dat we proberen een 2-bit integerwaarde op te slaan in een geheugencel. Voor dit scenario moeten we elke cel in een geheugenarray programmeren met een van de vier mogelijke waarden van de 2-bits integerwaarden (00, 01, 10, 11). De vier onderstaande curven zijn een IV-curve voor elk van de vier mogelijke toestanden, en de elektrische stroomrespons van de cel zou afhangen van de spanning die op CG wordt toegepast.
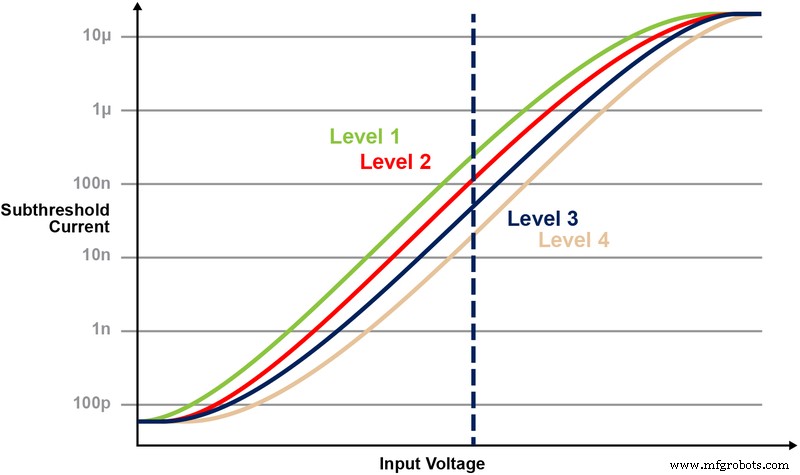
Figuur 5:Vt-niveaus programmeren in ESF3-cel. (Bron:Microchip Technology)
Multiply-Accumulate-bewerking met in-memory computing
Elke ESF3-cel kan worden gemodelleerd als variabele conductantie (gm ). Geleiding van een ESF3-cel hangt af van de zwevende poort Vt van de geprogrammeerde cel. Een gewicht van een getraind model is geprogrammeerd als zwevende poort Vt van de geheugencel, daarom gm van de cel vertegenwoordigt een gewicht van het getrainde model. Wanneer een ingangsspanning (Vin) wordt toegepast op de ESF3-cel, wordt de uitgangsstroom (Iout) gegeven door de vergelijking Iout =gm * Vin, de vermenigvuldigingsbewerking tussen de ingangsspanning en het gewicht dat is opgeslagen op de ESF3-cel.
Afbeelding 6 hieronder illustreert het concept van meervoudig accumuleren in een kleine arrayconfiguratie (2×2 array) waarin de accumulatiebewerking wordt uitgevoerd door uitgangsstromen toe te voegen (van de cellen (van de vermenigvuldigingsbewerking) die op dezelfde kolom zijn aangesloten (bijvoorbeeld I1 =I11 + I21) Afhankelijk van de toepassing kan de activeringsfunctie worden uitgevoerd binnen het ADC-blok of kan dit worden gedaan met een digitale implementatie buiten het geheugenblok.
klik voor grotere afbeelding
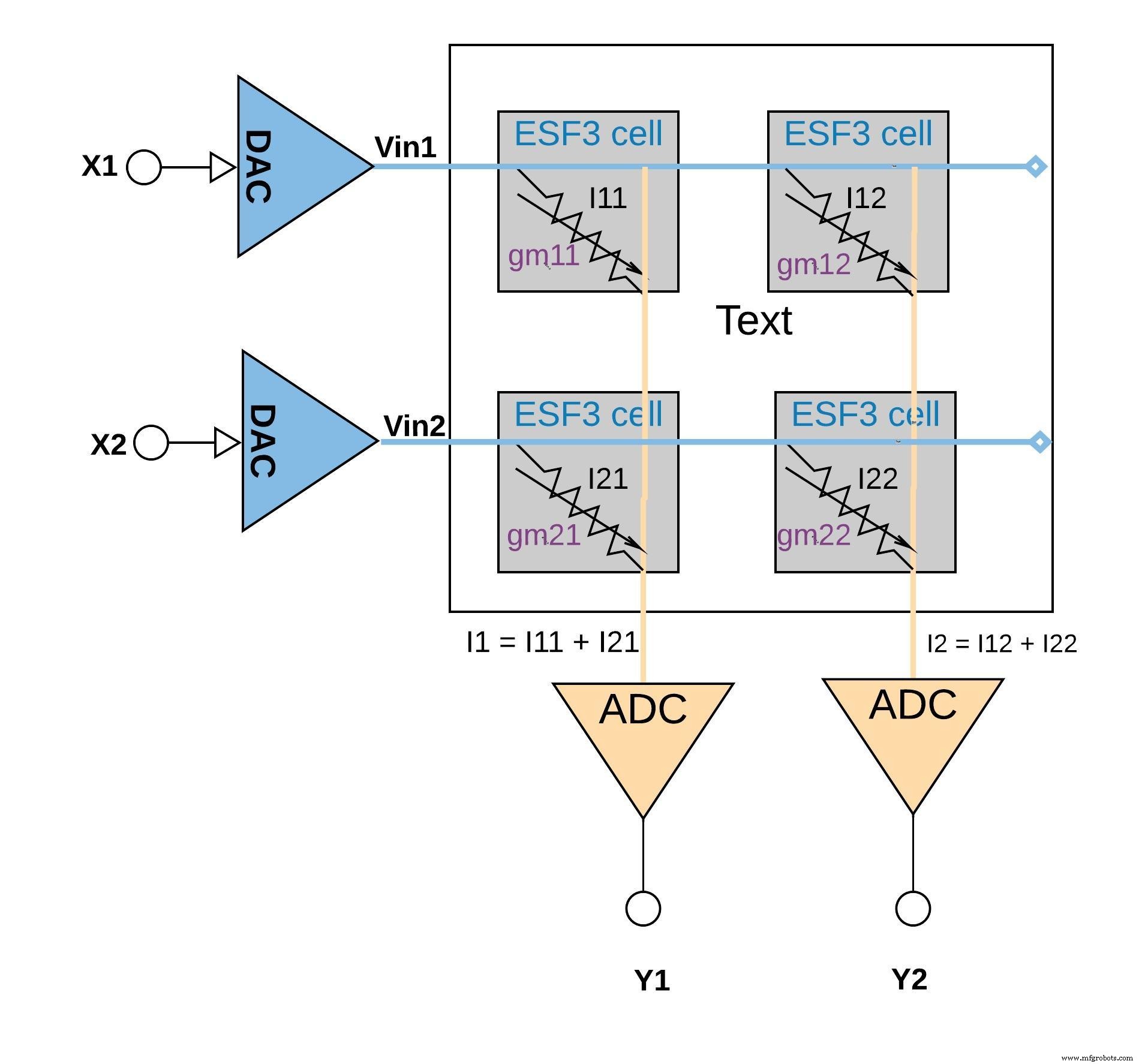
Afbeelding 6:multi-accumulerende bewerking met ESF3-array (2×2). (Bron:Microchip Technology)
Het concept op een hoger niveau verder illustreren; individuele gewichten van een getraind model worden geprogrammeerd als zwevende poort Vt van de geheugencel, dus alle gewichten van elke laag van het getrainde model (laten we zeggen een volledig verbonden laag) kunnen worden geprogrammeerd op een geheugenarray die er fysiek uitziet als een gewichtsmatrix , zoals geïllustreerd in figuur 7.
klik voor grotere afbeelding
Figuur 7:Gewichtsmatrixgeheugenarray voor gevolgtrekking. (Bron:Microchip Technology)
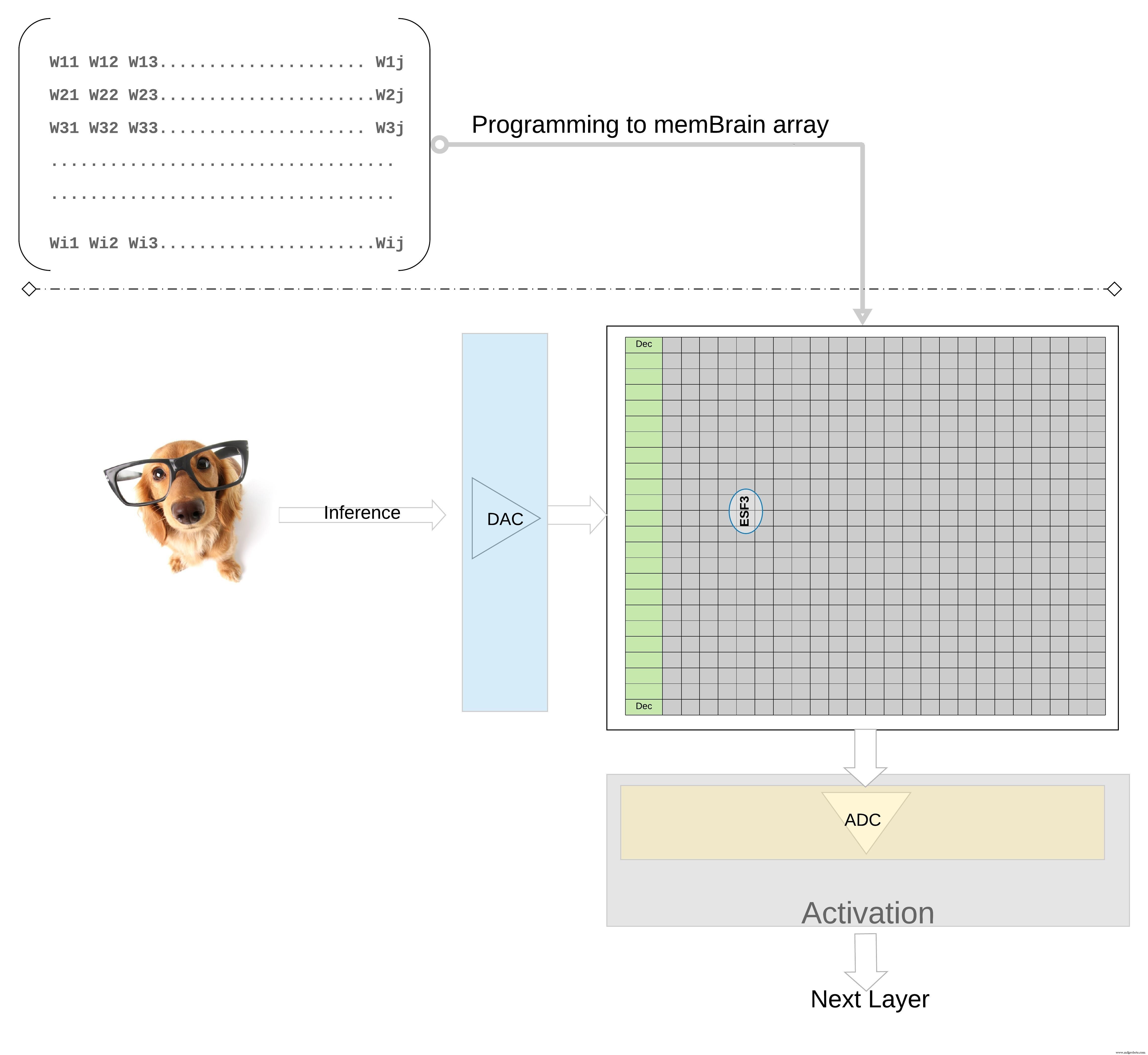
Voor een inferentiebewerking wordt een digitale ingang, laten we zeggen beeldpixels, eerst omgezet in een analoog signaal met behulp van een digitaal-naar-analoogomzetter (DAC) en toegepast op de geheugenarray. De array voert vervolgens duizenden MAC-bewerkingen parallel uit voor de gegeven invoervector en produceert uitvoer die naar de activeringsfase van de respectieve neuronen kan gaan, die vervolgens weer kan worden omgezet in digitale signalen met behulp van een analoog-naar-digitaalomzetter (ADC). De digitale signalen worden vervolgens verwerkt voor pooling voordat ze naar de volgende laag gaan.
Dit type geheugenarchitectuur is zeer modulair en flexibel. Veel memBrain-tegels kunnen aan elkaar worden genaaid om een verscheidenheid aan grote modellen te bouwen met een mix van gewichtsmatrices en neuronen, zoals geïllustreerd in figuur 8. In dit voorbeeld wordt een 3×4 tegelconfiguratie aan elkaar genaaid met een analoge en digitale stof tussen de tegels en gegevens kunnen via een gedeelde bus van de ene tegel naar de andere worden verplaatst.
klik voor grotere afbeelding
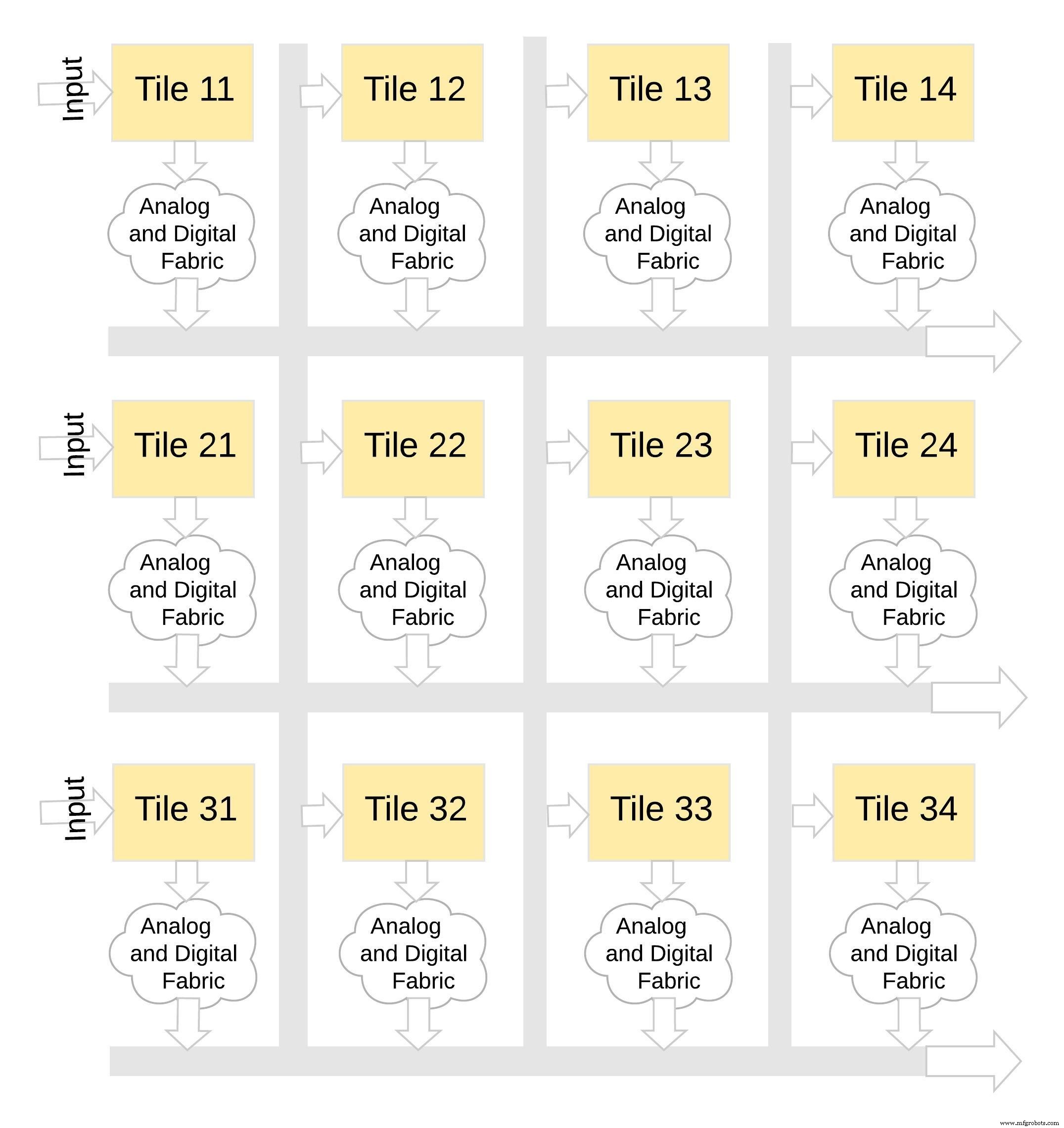
Figuur 8:memBrain™ is modulair. (Bron:Microchip Technology)
Tot nu toe hebben we vooral de siliciumimplementatie van deze architectuur besproken. De beschikbaarheid van een Software Development Kit (SDK) (Afbeelding 9) helpt bij de implementatie van de oplossing. Naast het silicium vergemakkelijkt de SDK de implementatie van de inferentie-engine.
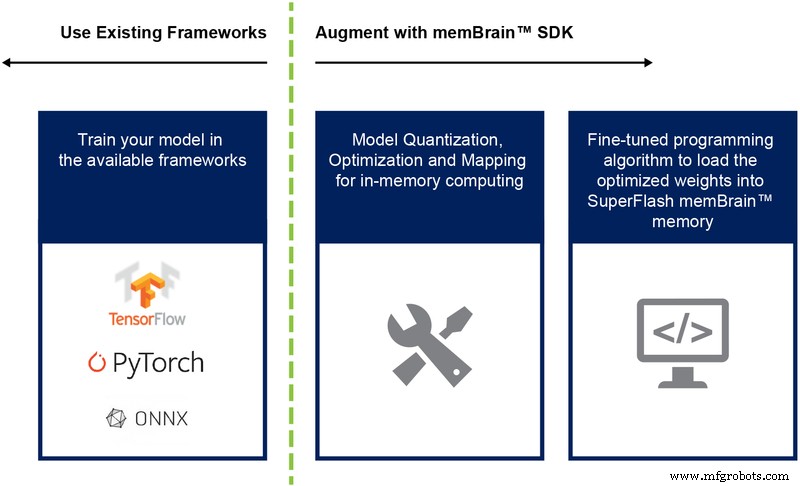
Figuur 9:memBrain™ SDK-stroom. (Bron:Microchip Technology)
De SDK-stroom is agnostisch voor het trainingskader. De gebruiker kan een neuraal netwerkmodel maken in elk van de beschikbare frameworks zoals TensorFlow, PyTorch of andere, met behulp van drijvende-kommaberekening zoals gewenst. Zodra een model is gemaakt, helpt de SDK het getrainde neurale netwerkmodel te kwantificeren en toe te wijzen aan de geheugenarray waar de vector-matrixvermenigvuldiging kan worden uitgevoerd met de invoervector afkomstig van een sensor of computer.
Conclusie
Voordelen van deze multi-level geheugenbenadering met zijn in-memory rekenmogelijkheden zijn onder meer:
- Extreem laag vermogen: De technologie is ontworpen voor toepassingen met een laag vermogen. Het krachtvoordeel op het eerste niveau komt van het feit dat de oplossing in-memory computing is, zodat er geen energie wordt verspild aan gegevens- en gewichtsoverdracht van SRAM/DRAM tijdens de berekening. Het tweede energievoordeel vloeit voort uit het feit dat flitscellen in subthreshold-modus worden gebruikt met zeer lage stroomwaarden, zodat de dissipatie van actief vermogen erg laag is. Het derde voordeel is dat er bijna geen energieverlies is tijdens de standby-modus, omdat de niet-vluchtige geheugencel geen stroom nodig heeft om de gegevens voor altijd-aan-apparaat te bewaren. De aanpak is ook zeer geschikt voor het benutten van schaarste in gewichten en invoergegevens. De geheugenbitcel wordt niet geactiveerd als de invoergegevens of het gewicht nul is.
- Verkleinde voetafdruk van het pakket: De technologie maakt gebruik van een split-gate (1,5T) celarchitectuur, terwijl een SRAM-cel in een digitale implementatie is gebaseerd op een 6T-architectuur. Bovendien is de cel een veel kleinere bitcel in vergelijking met een 6T SRAM-cel. Bovendien kan één celcel de hele 4-bit integerwaarde opslaan, in tegenstelling tot een SRAM-cel die hiervoor 4*6 =24 transistors nodig heeft. Dit zorgt voor een aanzienlijk kleinere voetafdruk op de chip.
- Lagere ontwikkelingskosten: Vanwege knelpunten op het gebied van geheugenprestaties en beperkingen van de Von Neumann-architectuur, hebben veel speciaal gebouwde apparaten (zoals Nvidia's Jetsen of Google's TPU) de neiging om kleinere geometrieën te gebruiken om prestaties per watt te behalen, wat een dure manier is om de edge AI-computeruitdaging op te lossen. Met de multi-level geheugenbenadering met behulp van analoge on-memory rekenmethoden, wordt de berekening op de chip gedaan in flash-cellen, zodat men grotere geometrieën kan gebruiken en de maskerkosten en doorlooptijden kan verminderen.
Edge computing-applicaties zijn veelbelovend. Toch zijn er uitdagingen op het gebied van stroom en kosten die moeten worden opgelost voordat edge computing van de grond kan komen. Een grote hindernis kan worden weggenomen door een geheugenbenadering te gebruiken die berekeningen op de chip in flashcellen uitvoert. Deze aanpak maakt gebruik van een in productie bewezen, de facto standaard type geheugentechnologie met meerdere niveaus die is geoptimaliseerd voor machine learning-toepassingen.
Ingebed
- Hoe edge-computing zakelijke IT ten goede kan komen
- Wat kan cloud computing betekenen voor IT-personeel?
- Een inleiding tot edge computing en voorbeelden van use-cases
- Edge computing:5 mogelijke valkuilen
- Hoe IIoT-gegevens de winstgevendheid van lean manufacturing kunnen stimuleren
- Dichter bij de rand:hoe edge computing Industrie 4.0 zal stimuleren
- Hoe een stroomstoring uw voedingen kan beschadigen
- 6 goede redenen om edge computing te gebruiken
- Edge Computing en 5G Schaal de onderneming op
- Hoe geconnecteerde technologie kan helpen bij het oplossen van de supply chain-uitdagingen
- Hoe kleine winkels digitaal kunnen worden - economisch!