


Wat zit er achter de overstap naar custom voice agents?
Automatisering is de weg van de toekomst. We leven in het tijdperk van nu en willen dat alles snel beantwoord, bereikt en ontvangen wordt. Ondanks deze fundamentele verschuiving omarmen veel mensen technologie niet. Voor sommigen is het gerelateerd aan levensstijl:grote bedrijven kunnen te onhandig zijn om hun systeem te transformeren, en individuen kunnen vast komen te zitten in hun manier van doen en niet willen leren navigeren op een aanraakscherm. Voor de meesten komt het echter neer op gegevens - wie de eigenaar is en hoe ze veilig kunnen worden gehouden.
De oplossing? Het is zo simpel als een stem. Voice enablement-technologie kan de behoefte aan automatisering ontsluiten en tegelijkertijd gegevens binnen handbereik houden, en het is iets dat we elke dag gebruiken, ongeacht de plaats of het platform. Aangezien de digitale transformatie steeds meer applicaties beïnvloedt, zijn voice agents het antwoord. Meer bedrijven onderzoeken het bouwen van aangepaste spraakplatforms, ingebed in de technologie, afgezien van populaire bekende namen van stemagenten zoals Alexa en Google Voice. Unieke spraakplatforms zullen de weg vooruit zijn voor bedrijven die hun eigen gegevens willen behouden en beheren.
Achter de verstoring zit automatisering
Nu het Internet of Things (IoT) voortbouwt op kunstmatige intelligentie (AI), beginnen we de noodzaak in te zien dat automatisering moet groeien. Wanneer IoT samenwerkt met AI, verbetert het de controle die gebruikers hebben over de enorme en brede verzamelingen internetapparaten. We beginnen het inschakelen van spraak thuis en daarbuiten te zien uitbreiden, via platforms zoals Google Voice, Amazon Alexa, Microsoft Cortana of uniek gecreëerde platforms. Bij Harman Embedded Audio hebben we met elke afzonderlijke voice-engine ter wereld gewerkt en begrijpen we de breedte van de markt uit de eerste hand. We zien meer bedrijven die hun spraakgestuurde producten willen bouwen op hun eigen aangepaste stemassistentplatforms, zodat ze controle hebben over de gegevens.
De vraag naar spraakbesturing groeit
Het is een van de populairste trends in audio. Het volgende grote ding in de gebruikersinterface, nu functies zoals aanraakschermen bijna alomtegenwoordig zijn, is het kunnen praten met een apparaat. Voice leidt de volgende generatie van menselijke samenwerking. Denk aan natuurlijke taalverwerking op een computer:spraak wordt verwerkt op een manier die past bij wat de machine liever zou horen, maar als je datzelfde verwerkte bestand zou afspelen, zou het mechanisch en onnatuurlijk zijn. Hetzelfde geldt voor telefoneren:het wekt niet dezelfde indruk met iemand in een kamer te zijn. Dit is waar spraak naartoe moet en waar de hierboven genoemde unieke spraakplatforms zullen volgen.
Hoe aangepaste spraakagenten eruit zien en wat er bij komt kijken
Hoewel elke spraakoplossing anders is, is het belangrijk dat alle oplossingen flexibel genoeg zijn om zich aan te passen aan de noodzakelijke vereisten van hun gebruik, terwijl ze toch gebruikersgegevens verzamelen en beschermen. Om dit te bereiken, zijn er drie hoofdelementen betrokken bij het bouwen en integreren van een voice-agent.
De eerste is far-field-algoritmen. Gebruik een eersteklas algoritme dat far-field-stem zal vastleggen. Bij mijn bedrijf gebruiken we vier belangrijke software-algoritmen van Sonique-algoritmen:ruisonderdrukking, akoestische ruisonderdrukking, geluidsscheiding en straalvorming, evenals detectie van stemactiviteit. Deze algoritmen zijn speciaal ontwikkeld om in combinatie met elkaar te worden gebruikt om spraakgestuurde applicaties te ondersteunen.
Hoe werken ze? Denk erover na om een slimme luidspreker met een mens te vergelijken. De DSP/SOC fungeert als het ‘brein’ van de spreker, de microfoons zijn de oren en de luidsprekers zijn de mond. Voor ons, wanneer iemand onze naam roept, annuleert ons brein alle geluiden om ons heen en steekt al zijn energie in dat sleutelwoord. Dit is wat we hebben bereikt in een slimme luidspreker:wanneer het trefwoord wordt gedetecteerd, gebruikt de microfoon verschillende ruisonderdrukkingstechnieken en zet hij al zijn kracht in op de bron. In het proces annuleert het de meeste ruis eromheen. In akoestische omgevingen zijn er veel geluidsbronnen, zoals omgevingsgeluid, lokale luidsprekers, HVAC en meer, die feedback van de spreker naar de microfoon echoën. Elk van deze geluidsbronnen heeft zijn eigen individuele oplossing nodig. Sonique-algoritmen onderdrukken de geluiden en vangen de best mogelijke duidelijke spraakopdracht op.
Ook is het van cruciaal belang om een engine voor het spotten van zoekwoorden (KWS) te bouwen. KWS detecteert trefwoorden zoals "Alexa" of "OK Google", om een gesprek te beginnen. Ik heb met bijna elke leverancier van KWS-engines gewerkt en elke provider wordt aangedreven door diepe neurale netwerken - zeer aanpasbaar, altijd luisterend, lichtgewicht en ingebed. Voor een geweldige klantervaring in een verre spraaktoepassing is het cruciale onderdeel een False Accept- en False Reject-percentage. In een echte wereldsituatie is het echt een uitdaging om een lage False Reject-snelheid te behouden, aangezien er veel externe geluiden zijn, zoals tv's, huishoudelijke apparaten, douches, enz., die een onvolmaakte annulering van het afspelen van audio veroorzaken. Ervaren ontwikkelaars stemmen de KWS-engine af om de False Accept Rate laag te houden.
Ten slotte converteert de Automatic Speech Recognition (ASR)-engine spraak naar tekst. ASR bestaat uit de kerntool voor spraak naar tekst (STT) en natuurlijke taalbegrip (NLU), die de onbewerkte tekst omzet in gegevens. De engine vereist ook vaardigheid, oftewel een kennisbank van waaruit antwoorden kunnen worden gegeven, evenals de inverse tekst-naar-spraaktool. We hebben bijvoorbeeld een ASR-engine ontwikkeld met de naam E-NOVA, die multi-platform, on-premise integraties biedt, meerdere talen ondersteunt (momenteel zeven talen en in toenemende mate), en inclusief trainbare modellen, integratieondersteuning door derden en sprekeridentificatie.
ASR is de eerste stap waarmee de spraaktechnologieën zoals Amazon Alexa, OK Google, Cortana of de klant kunnen reageren wanneer daarom wordt gevraagd:"Wat is het weer in Los Angeles?" Het is het belangrijkste onderdeel dat het gesproken geluid detecteert, het herkent als woorden, het vergelijkt met het geluid in een bepaalde taal en uiteindelijk de woorden identificeert die we zeggen. Door de ASR-engine voelt het gesprek natuurlijk aan. En met moderne technologieën profiteren de meeste ASR-engines van cloud computing. Met aanvullende technologieën zoals NLU worden de gesprekken tussen mens en computer slimmer en complexer.
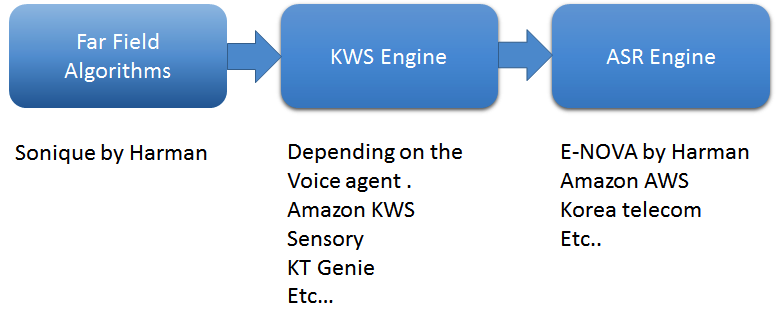
Figuur 1:Basisverwerkingspijplijn in voice agents. (Bron:Harman Embedded Audio)
Het bouwen van aangepaste spraakagenten brengt echter een groot aantal unieke uitdagingen met zich mee. Het begrijpen van de omgeving van het product is een van de belangrijkste uitdagingen van het proces, en elke toepassing zal variëren op basis van de specifieke gebruikssituatie. Stel je bijvoorbeeld voor dat je thuis kookt, je handen zijn druk en vol, als het tijd is om wat water te koken, hoef je alleen maar een snel verzoek te doen aan de stemagent die is aangesloten op je sanitaire ruimte:"Kook water tot x graden." De uitdaging hier is of het apparaat kan horen wat je zei en hoeveel ruis het apparaat zal annuleren om het schone signaal te krijgen en je goed te horen. Om dit te garanderen, moeten spraakalgoritmen worden afgestemd op vijandige omgevingen, moeten de microfoonlocaties worden aangepast zodat ze het geluid kunnen opvangen en moeten luidsprekers met een lage THD worden gebruikt om een hoge SNR voor microfoons te ondersteunen. Hierdoor krijgt u de duidelijkst mogelijke audio naar de ASR-engine, wat resulteert in het juiste antwoord op uw vragen.
Stel je bovendien voor dat je op een cruiseschip zit:de geluiden om je heen zijn totaal anders dan wat je in een woonkamer of keuken hoort. De grootste uitdaging is het trainen van algoritmen om die geluiden te onderdrukken en het zuivere audiosignaal naar het systeem te krijgen voor een nauwkeurige respons. Als het op de juiste manier is geïmplementeerd, kan een virtueel persoonlijk cruise-assistentsysteem, zoals het systeem dat we voor MSC Cruises hebben ontwikkeld, op betrouwbare wijze de stappen uitvoeren die worden weergegeven in afbeelding 2.
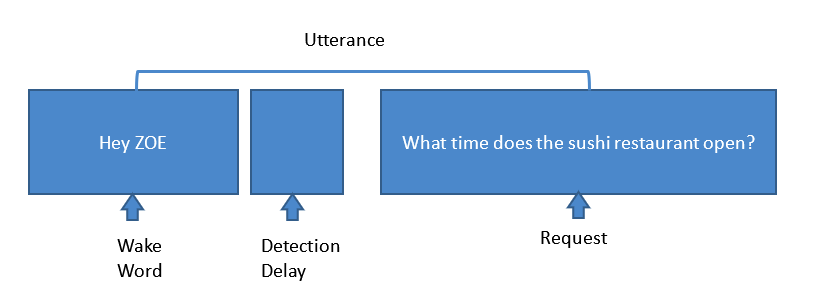
Afbeelding 2:Stappen die betrokken zijn bij een typisch verzoek voor een stemassistent. (Bron:Harman Embedded Audio)
Hier detecteert een spraakassistent in de passagierskamer het wekwoord 'Hey Zoe'. Vervolgens, terwijl KWS het sleutelwoord detecteert, leidt de hele microfoon, gebaseerd op ruisonderdrukkingsalgoritmen, hun energie naar de bron en annuleert het omgevingsgeluid, zoals AC-geluid, tv, ongecorreleerde geluiden, propeller- en motorgeluiden, windgeluiden, AEC , enz. Sonique-algoritmen zijn afgestemd om al deze geluiden te onderdrukken en het schoonst mogelijke signaal naar het systeem te krijgen. Wanneer het systeem het verzoek ontvangt, converteert de ASR-engine deze stem vervolgens naar tekst. NLU-engines zetten deze tekst vervolgens om in onbewerkte gegevens om het antwoord te krijgen. Maar we zijn nog niet klaar. Om het antwoord te krijgen waarnaar u op zoek bent, biedt de kennisvaardigheid het antwoord op het verzoek en de ASR-engine converteert die gegevenstekst naar spraak en voert deze uit via de spreker.
Een andere uitdaging is het omringen van False Rate Rejection (FRR). Het proces om Wake Word FRR te bereiken, een van de controlepunten die wordt gebruikt om de prestaties van slimme luidsprekers te meten, is zowel tijdrovend als kostbaar. Het systeem wordt gebruikt om te controleren of het product goed kan ontwaken wanneer een wekwoord wordt gedetecteerd. Om FRR te bereiken, zijn getrainde sleutelwoorden essentieel. In onze ervaring stelt het combineren van het getrainde model met een eersteklas algoritme ontwikkelingsteams in staat om de uitdaging aan te gaan en de best mogelijke FRR te bereiken. De activeringswoordrespons wordt verder getest onder verschillende omstandigheden in een laboratorium om er zeker van te zijn dat het systeem voldoet aan de industrienormen.
De voordelen van het gebruik van unieke voice agents
Voice agents bieden een grote meerwaarde aan de gebruikerservaring. Muziek is de grootste, eenvoudigste use case, maar de waarde van spraakagenten gaat veel verder dan het op afstand openen van je Spotify-account. Stem kan dingen aanzetten, communiceren met apparaten, water koken, een kraan aanzetten - en meer! Voice is krachtig en de agenten weten veel over hun gebruikers. Daarom willen bedrijven hun eigen gegevens in handen krijgen - ze bezitten, opslaan en beveiligen.
Spraakoplossingen hebben brede toepassingen, maar de sleutel is om een technologie te gebruiken die op verschillende platforms werkt - een technologie die relevant is voor slimme luidsprekers, laptops en smartphones, op Apple, Windows of Android - en de verzamelde gegevens te gebruiken om een agent te bouwen die begrijpt, leert voortdurend en onthoudt gebruikersbehoeften. Het creëren van een unieke voice-agent maakt deze gebruiksflexibiliteit mogelijk — en houdt tegelijkertijd de gegevens intern.
Ingebed
- Wat is het metalen glas?
- Wielen versus zwenkwielen:wat is het verschil?
- Wat is het verschil tussen massaproductie en aangepaste productie?
- Wat is opnieuw platformen in de cloud?
- Wat moet ik doen met de gegevens?!
- Wat is de circulaire economie?
- DC versus AC-motor:wat is het verschil?
- Wat zit er in het productieproces?
- Wat is de grafische industrie?
- Wat is de verfindustrie?
- Wat is de verpakkingsindustrie?