


Hoe machine learning de beschikbaarheid van activa kan verbeteren
Machine learning-toepassingen in de maakindustrie bestaan al vele jaren. In de begindagen (10 jaar geleden) waren ze gereserveerd voor grote bedrijven met uitgebreide middelen. De applicaties waren erg duur in aanschaf en implementatie. Eenmaal geïmplementeerd, hadden de applicaties uitgebreid technisch personeel nodig om de assetmodellen te onderhouden en de resultaten van de machine learning-applicatie te evalueren. Tegenwoordig zijn er een aantal machine learning-toepassingen voor industriële toepassingen die in korte tijd en in sommige gevallen op proef kunnen worden ingezet. In dit artikel zal ik een overzicht geven van het gebruik van machine learning-applicaties om activa te bewaken, enkele van de verschillende machine learning-applicaties bespreken die momenteel worden aangeboden en toekomstige applicaties gedetailleerd beschrijven.
Machinaal leren voor verbeterde beschikbaarheid van productieapparatuur
Machine learning-applicaties worden gebruikt om machinestoringspunten zo vroeg mogelijk te identificeren. Als u bekend bent met een PF-curve, weet u dat hoe eerder u een mogelijke storing identificeert, hoe beter. In de machine learning-softwaretoepassingen begint u met het bouwen van een model van het activum. Het model bestaat uit alle procesparameters en parameters van de fabricageapparatuur die bij dat specifieke activum horen. Deze parameters worden doorgaans opgeslagen in een gegevenshistoricus die gegevens vastlegt van het DCS van de fabriek, bijbehorende PLC's, elektronische logboeken, enz. Als we een pomp als voorbeeld gebruiken, zouden zuigdruk, persdruk, regelkleppositie, lagertemperatuur en lagertrillingen enkele goede voorbeelden zijn van parameters om in een model op te nemen. De meeste modellen hebben tussen de 10-30 parameters, maar we hebben enkele modellen die bijna 100 parameters hebben.
Nadat het model is gemaakt, worden historische operationele gegevens in het model geïmporteerd. Dit staat meestal bekend als de trainingsgegevensset en bevat gegevens van één jaar. Met één jaar aan gegevens kan het model rekening houden met seizoensveranderingen in de werking. Een persoon met kennis van de werking van het activum zou dan bepalen welke gegevens moeten worden "opgenomen" in de trainingsgegevensset (goede werking) en welke gegevens moeten worden "uitgesloten" van de trainingsgegevensset (slechte werking). De machine learning-toepassing gebruikt vervolgens de getrainde dataset om een operationele matrix voor het activum te ontwikkelen. De matrix geeft in feite aan hoe de machine op een bepaald moment moet werken op basis van de trainingsgegevens die zijn gebruikt om de matrix te maken.
Hier vindt de magie plaats:de machinematrix wordt ingezet binnen de softwaretoepassing om constant de werking van de machine te bewaken en te voorspellen waar de machineparameters zouden moeten draaien op basis van de matrix die deze heeft ontwikkeld. Als een parameter een significant percentage afwijkt van de modelvoorspelling, creëert het systeem een waarschuwingsconditie voor die specifieke parameter. Vervolgens wordt een technische evaluatie van het activum uitgevoerd om de verandering in de toestand te evalueren. Na evaluatie zijn er waarschijnlijk drie algemene resultaten:1) de waarschuwing is geldig, waarschuw de fabriek voor de aandoening en werk samen met lokale middelen om het probleem op te lossen; 2) de waarschuwing heeft aanvullende onderzoeks-/operationele gegevens nodig, blijf de parameter en alle bijbehorende parameters controleren op waarschuwingscondities; en 3) de waarschuwing vals positief is, het model opnieuw trainen met aanvullende operationele gegevens en het model opnieuw implementeren.
In ieder geval vereist de machine learning-toepassing toegewijde middelen om de modellen te onderhouden en problemen met productieapparatuur op te lossen met eigenaren van fabrieksapparatuur. Een fulltime medewerker besteedt doorgaans 40 procent van de tijd aan het onderhouden van modellen, 40 procent van de tijd aan het werken met fabrieksbronnen om problemen op te lossen en 20 procent van de tijd aan het waarderen van de hulp die door het programma wordt gegenereerd.
Resultaten van machine learning
De resultaten van een machine learning-toepassing zijn zeer krachtig. Deze softwaretoepassingen identificeren veranderingen in de omstandigheden van de productiemachine of procesparameters die niet waarneembaar zijn voor het menselijk oog. Figuur 1 toont een verhoogde lagertrilling op een primaire luchtventilator als gevolg van een verlies van oliestroom naar het lager. Er is een alarmtoestand binnengekomen op het buitenboordlager van de ventilator. De machine learning-applicatie had voorspeld dat de lagertrilling onder de huidige bedrijfsomstandigheden ongeveer 3,5 mils had moeten zijn. De lagertrilling was langzaam afgeweken van de voorspelde waarde en de alarmtoestand trad op bij 4,7 mils. De fabriek werd op de hoogte gebracht van de alarmtoestand en visuele inspectie van de ventilator wees uit dat de olieleiding een lek had ontwikkeld bij de verbinding met de lagerkap. De aanzuiging van de ventilator was vanaf elk uiteinde in de buurt van de lagersokkels. De ventilator zoog eigenlijk de olie in het ventilatorhuis, dus er was geen indicatie van het lek op de grond. De olie op de ventilatorbladen verzamelt vuil en puin, waardoor de ventilator uit balans raakt en vervolgens de trilling verhoogt. De fabrieksresources konden corrigerende maatregelen nemen om het lek te stoppen voordat het lager werd beschadigd.
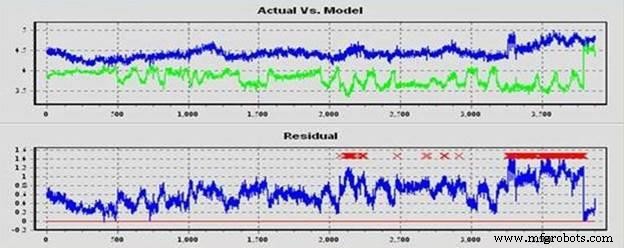
Figuur 1. Trillingen van ventilatorlagers
Figuur 2 is van een langzaam verval in waterstofzuiverheid op een grote turbinegeneratorset. De groene lijn is de voorspelde waarde van het model. De blauwe lijn is de werkelijke waarde en de rode stippen zijn waar de parameter in alarm ging. Tijdens deze trend van een maand hadden de lokale bemanningen het langzame verval van de waterstofzuiverheid niet opgemerkt. De fabriek werd van tevoren op de hoogte gebracht van een lokaal alarm of een fabriekssluiting, waardoor ze de tijd hadden om de situatie te beheersen zonder in crisismodus te hoeven werken.
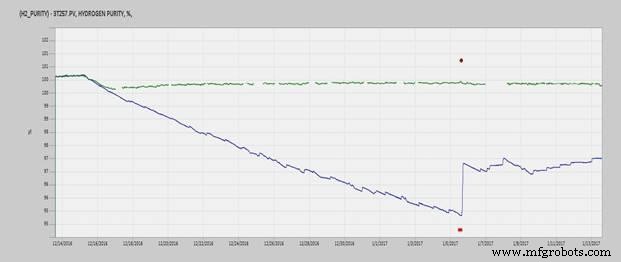
Figuur 2. Generator waterstofzuiverheid
Afbeelding 3 is gekoppeld aan het elektrohydraulische regelsysteem (EHC) dat de kleppositie, het turbinetoerental en de veiligheidskleppen regelt. In dit geval begon het drukverschil over de zeef van de EHC-pomp "A" toe te nemen. De inspectie van de zeef vindt doorgaans een of twee keer per ploeg plaats op het ronde blad van de operators voor lokale inspectie. Er werd contact opgenomen met de fabriek en ze konden overstappen van EHC-pomp "A" naar EHC-pomp "B". Dit verhinderde een turbinetrip en eventuele schade die daarbij zou zijn ontstaan.
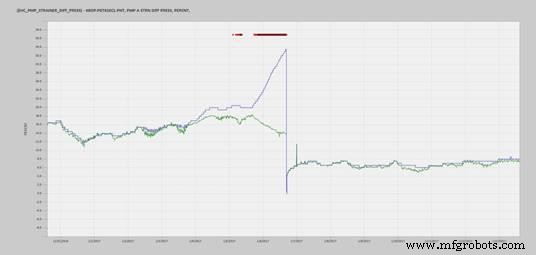
Figuur 3. EHC-pompzeef
Figuur 4 wordt geassocieerd met het smeersysteem op een grote vergruizer, ook wel bekend als een kommolen. Het smeersysteem levert olie aan de geïntegreerde versnellingsbak en alle bijbehorende lagers. Het activamodel voorspelde dat de temperatuur 90 graden F zou zijn, maar het liep in werkelijkheid op tot 110 graden F. Er werd contact opgenomen met lokale fabrieksbronnen en ze ontdekten dat de koelwaterregelklep naar de smeeroliewarmtewisselaar defect was. De regelklep werd vervangen en het systeem keerde terug naar normaal.
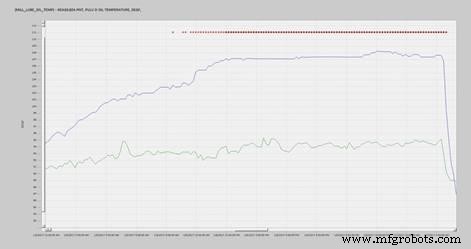
Figuur 4. Olietemperatuur vergruizer
De overige voorbeelden zijn afkomstig uit een tweede machine learning-softwaretoepassing. Hoewel de gebruikersinterface heel anders kan zijn, lijken de werkingsprincipes en de output van de softwareapplicaties erg op elkaar. De echte waarde van de machine learning-applicatie zijn de communicatie- en follow-upactiviteiten die plaatsvinden zodra de applicatie een verandering ten opzichte van de historische bedrijfstoestand heeft geïdentificeerd.
In de volgende grafieken is de blauwe lijn de werkelijke waarde, de rode lijn de voorspelde waarde, het lichtgroen gearceerde gebied vertegenwoordigt een alarmtoestand en de magenta verticale lijn is waar de parameter een alarmtoestand bereikte vanwege de afwijking. Het grijze gebied is waar de machine offline is. Merk op dat er geen voorspelling of alarmen optreden wanneer de machine offline is.
In figuur 5 hieronder volgen we een stoomturbine die wordt gevoed door een stoomgenerator met warmteterugwinning (HRSG) in een warmtekrachtcentrale. De procesparameter is de hogedrukspuitstroom naar de stoomturbine. De rode en blauwe lijnen lopen goed samen tot een stoomstroom van 1.000 pond per uur. De werkelijke en voorspelde beginnen af te wijken met 1.000 pond per uur, en er treedt een groene waarschuwingsconditie op binnen de applicatie.
De twee waarden blijven afwijken tot een alarmconditie, weergegeven door de magenta verticale lijn. Er is contact opgenomen met fabrieksbronnen om de werking van de stoomgenerator en de modelvoorspelling te bespreken.
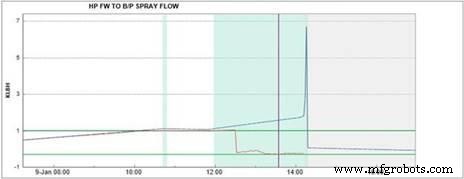
Figuur 5. Sproeistroom onder hoge druk
Afbeelding 6 illustreert de verandering in trilling op een verbrandingsturbine tijdens het opstarten. De grafiek toont vijf afzonderlijke opstartscenario's, weergegeven door de verticaal gestripte gebieden. In alle gevallen is de trilling die wordt weergegeven door de blauwe lijn veel hoger wanneer het apparaat voor het eerst weer in gebruik wordt genomen. Bij de derde keer opstarten wordt de trilling zelfs lang genoeg verhoogd om een alarmconditie voor de parameter te creëren. De fabriek werd op de hoogte gebracht en er werd vastgesteld dat de trillingssensor los was geraakt door normaal gebruik.
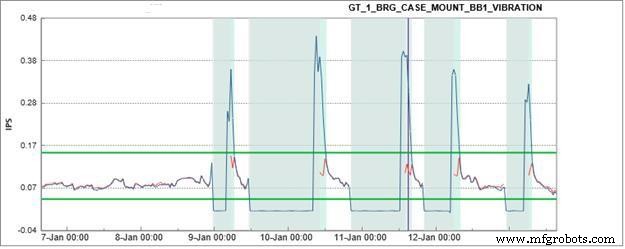
Figuur 6. Trilling verbrandingsturbine
Afbeelding 7 illustreert meerdere opstartscenario's, waarbij de vierde opstart resulteert in een alarmtoestand. De softwaretoepassing had voorspeld dat de tussenliggende stoomtrommeldruk in de HRSG 278 psi zou zijn, maar de werkelijke waarde was 240 psi. De toestand werd gemeld aan de plaatselijke fabrieksbronnen en de eenheid werd offline gehaald om reparaties aan de regelklep uit te voeren. Toen de volgende dag weer in gebruik werd genomen, waren de modelvoorspelling en de werkelijke waarde weer normaal.
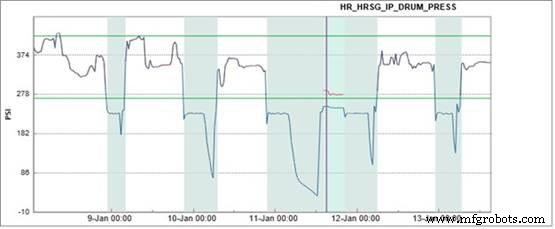
Figuur 7. HRSG-vatdruk
Toekomstige toepassingen voor machine learning
Op een bepaald moment in de nabije toekomst zullen dit soort softwaretoepassingen standaard zijn in wat we vandaag kennen als een DCS. Het DCS-systeem zou voorspellingen van elke parameter bouwen op basis van de correlatie met andere parameters binnen het proces. Aangezien de voorspellingen afwijken van de werkelijke, zouden waarschuwingen naar de operator worden gestuurd met informatie over welke procesparameters de afwijking veroorzaken. Naarmate de machine leert welke corrigerende maatregelen moeten worden genomen, heeft de machinist steeds minder betrokkenheid nodig totdat u een punt bereikt waarop de machine zichzelf kan bedienen. Dit lijkt misschien onbereikbaar, maar we hebben hier vandaag voorbeelden van. De automatische piloot van Tesla is waarschijnlijk het beste voorbeeld van de mogelijkheden van machine learning vandaag de dag. In december 2016 bracht Tesla een video uit van volledig autonoom rijden van uw huis naar uw werk met automatisch parkeren en ophalen. Het is een indrukwekkende video om te zien en laat ons zien wat de toekomst zal brengen.
Machine learning-softwaretoepassingen kunnen krachtige verbeteringen opleveren in de beschikbaarheid van activa, procesverbeteringen en productieverhogingen wanneer ze worden toegepast op een productieproces. Het implementeren en onderhouden van de softwareapplicaties vereist gespecialiseerde vaardigheden, maar de drempel om toe te treden is de laatste jaren veel lager. Naarmate deze softwaretoepassingen meer mainstream worden, zullen de kosten van de toepassing nog verder dalen. Op een gegeven moment zullen applicaties die zijn gebouwd voor het grote publiek hun weg vinden naar de industriële omgeving.
Onderhoud en reparatie van apparatuur
- Wat is SCADA en hoe kan het de productie-efficiëntie verbeteren?
- Gegevensbeheer stimuleert machine learning en A.I. in IIOT
- Hoe bewegwijzering en etikettering de betrouwbaarheid kunnen verbeteren
- Hoe het industriële internet activabeheer verandert
- Hoe data science en machine learning kunnen helpen bij het stimuleren van website-ontwerp
- Hoe machine learning fabrikanten kan helpen de klimaatverandering tegen te gaan
- Machine learning in het veld
- Hoe fabrieksmanagers regelmatig machineonderhoud kunnen plannen
- De beschikbaarheid van machines berekenen en verbeteren
- Hoe de machinenauwkeurigheid te verbeteren
- Hoe een straalkopmachine de productiviteit kan verbeteren