


Belangrijke opmerking over machine learning en de vier belangrijkste typen voor beginners
Big data is ongetwijfeld een belangrijk onderdeel van toekomstige technologische ontwikkeling. Echter, machine learning (ML) en Artificial Intelligence (A.I) spelen beide een belangrijke rol in deze ontwikkeling. De relatie tussen deze drie wordt kort uitgelegd:Big data is voor materialen, machine learning is voor methode en kunstmatige intelligentie is voor resultaten.
Wat is machine learning?
Machine learning (ML) is een van de vormen van kunstmatige intelligentie (A.I) waarin algoritmen zo worden geschreven dat het systeem de mogelijkheid krijgt om automatisch te leren, aan te passen en automatisch te verbeteren door de ervaring zonder expliciet te worden geprogrammeerd .
De machine learning-algoritmen bouwen een voorbeeldig model dat is gebaseerd op het type gegevens waarop het is gericht om te leren, dit type gegevens wordt "trainingsgegevens" genoemd.
Soorten machine learning?
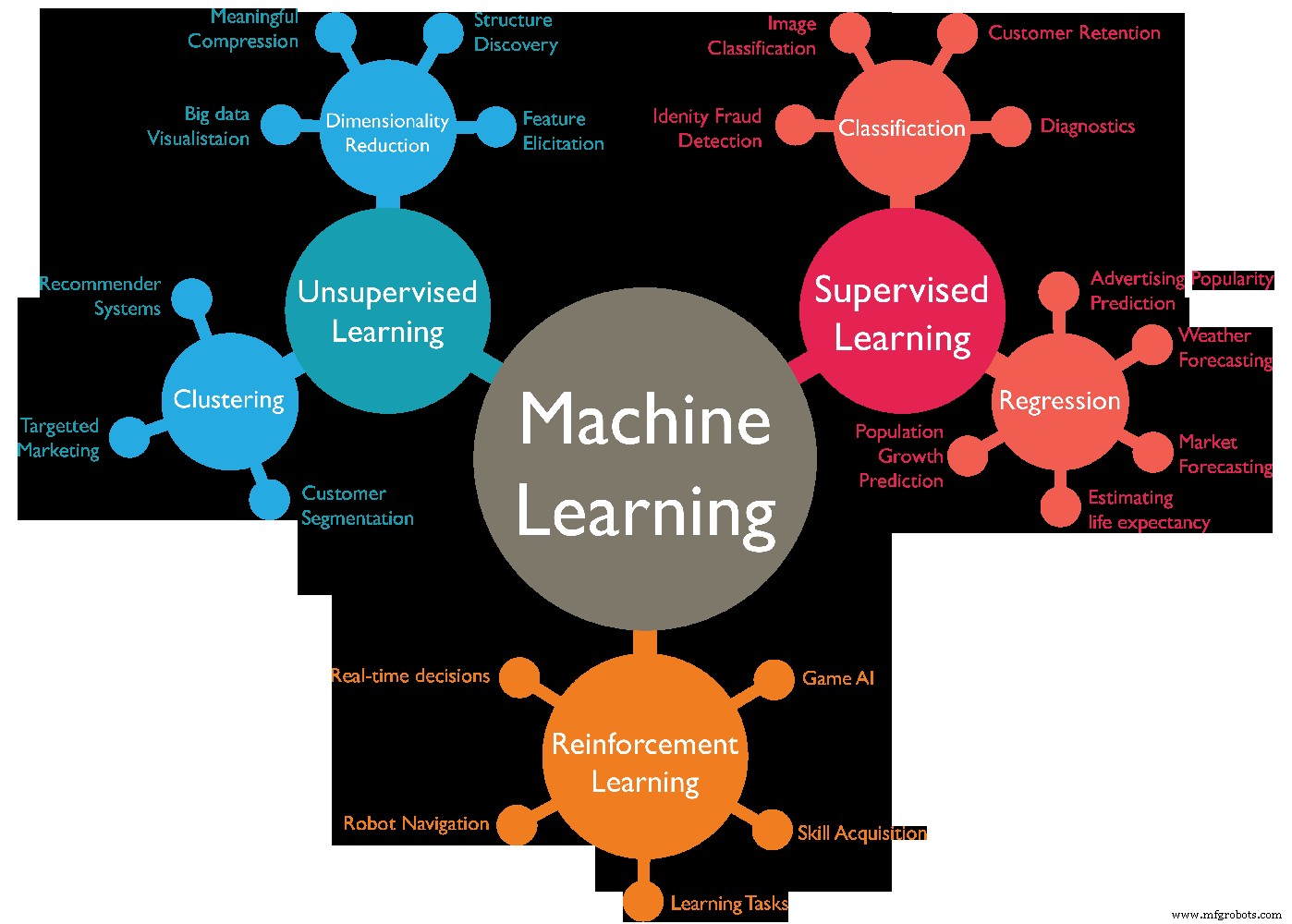
Er zijn verschillende soorten machine learning-algoritmen, deze kunnen gewoonlijk worden onderverdeeld in 4 categorieën, verschillende soorten machine learning zijn als volgt:-
- Onder toezicht leren.
- Onbewaakt leren.
- Semi-gesuperviseerd leren.
- Versterkend leren.
Onder toezicht leren
Als de machine onder toezicht staat terwijl deze zich in de "leerfase" bevindt, wordt dit type training begeleid leren genoemd. Wat bedoelen we echt als we zeggen dat een machine bewaakt ?. Wat het werkelijk betekent om algoritmen op zo'n manier toe te passen dat de machine leert om zijn oude gegevens (gegevens die in het verleden zijn verstrekt) te gebruiken en deze te gebruiken om voorspellingen te doen van toekomstige gebeurtenissen rond het type gegevens dat is ingevoerd, d.w.z. oude gegevens.
De analyse wordt gestart en alle materialen in de trainingsdataset en gelabeld correleren zodanig met de machine dat deze een voorspelling kan doen van de juiste outputwaarden. Het betekent dat we de machine veel informatie geven over een bepaald geval en vervolgens een casusresultaat geven. Het resultaat wordt de gelabelde gegevens genoemd, terwijl de rest van de informatie wordt gebruikt als invoerfuncties. Het systeem kan dan na voldoende training ook doelen bieden voor nieuwe input. Het algoritme kan zijn uitvoer vergelijken met de beoogde uitvoer en verschillen vinden om het model dienovereenkomstig te wijzigen.
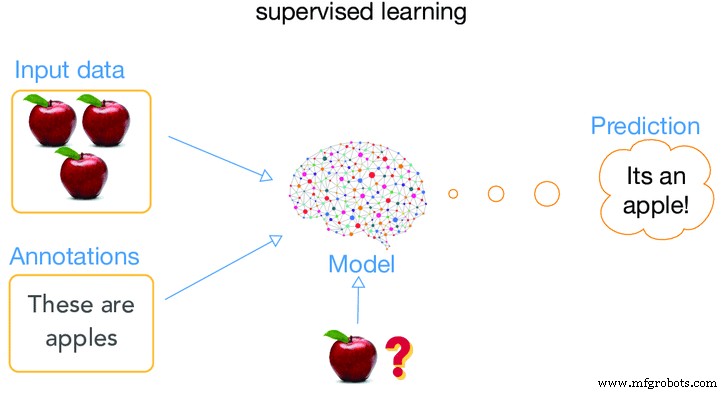
afbeelding met dank aan artificialintelligence.oodles.io/
Meestal is deze methode handmatige classificatie, die het gemakkelijkst is uit te voeren voor een computer en het moeilijkst voor mensen. Een voorbeeld van deze methode is, de machine standaardantwoorden vertellen, en wanneer de machine wordt getest, zal de machine altijd antwoorden volgens het standaardantwoord en daarom zal de betrouwbaarheid ook groter zijn.
Onbegeleid leren
In tegenstelling tot leren onder toezicht worden algoritmen voor niet-gesuperviseerd leren gebruikt wanneer de informatie die wordt gebruikt om de machine te trainen niet is geclassificeerd of gelabeld, zoals de naam al doet vermoeden, wordt bij leren zonder toezicht geen hulp aangeboden van de gebruiker aan de computer om te helpen het leert.
Het geleverde materiaal heeft geen label en de machine matcht vervolgens de kenmerken van de gegevens en classificeert de materialen. Door het ontbreken van gelabelde trainingssets identificeert de machine vervolgens patronen in de gegevens die voor mensen niet zo duidelijk zijn.
image Courtesy data-flair.training/Bij deze methode is er geen handmatige classificatie, wat het gemakkelijkst is voor mensen, maar het moeilijkst voor de computer en veel meer fouten kan veroorzaken. Het systeem berekent meestal niet de beoogde output, maar het onderzoekt de verstrekte gegevens en kan relaties uit datasets trekken om verborgen structuren van niet-gelabelde gegevens te beschrijven. Daarom is het zeer nuttig om patronen te herkennen in gegevens zonder toezicht, en het helpt ons ook bij het nemen van beslissingen.
Semi-supervisie leren
Semi-gesuperviseerd leren is anders dan gesuperviseerd leren en niet-gesuperviseerd leren waarbij er ofwel geen labels aanwezig zijn voor alle observatie van gegevens of er wel labels aanwezig zijn.
In Semi-supervised worden zowel gelabelde (gesuperviseerde) als niet-gelabelde (niet-gesuperviseerde) gegevens gebruikt voor training. SSL is een mengeling van de twee soorten lessen waarbij een kleine hoeveelheid gegevens is gelabeld en grote hoeveelheden gegevens ongelabeld. De machine moet functies vinden via gelabelde gegevens en vervolgens met behulp van het basismodel andere gegevens dienovereenkomstig classificeren. SSL-systemen kunnen niet alleen hun leernauwkeurigheid aanzienlijk verbeteren, maar kunnen ook nauwkeurigere voorspellingen doen.
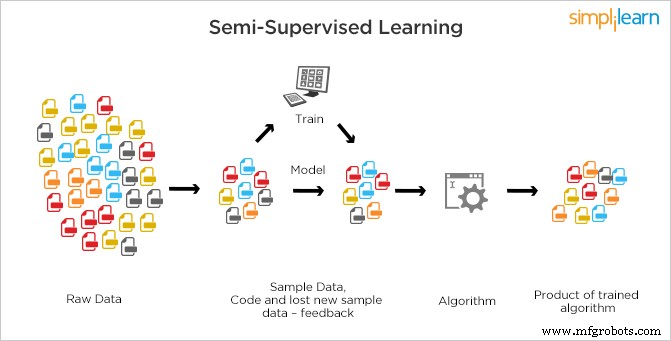
Het is de meest gebruikte methode omdat de kosten voor het etiketteren hoog zijn, omdat er bekwame menselijke experts nodig zijn. Het vereist relevante middelen om het te trainen en ervan te leren, terwijl het verkrijgen van niet-gelabelde gegevens over het algemeen geen extra middelen vereist. Vanwege het ontbreken van labels in de meeste waarnemingen, maar de aanwezigheid van een paar, semi-gesuperviseerde algoritmen hebben de voorkeur de beste kandidaten voor het bouwen van een model.
Deze methoden profiteren van het idee dat, hoewel de groepsleden onbekend zijn omdat ongelabelde gegevens meer in het algemeen zijn, informatie over de parameters nog steeds in de gelabelde gegevens wordt bewaard en kan worden gevonden met behulp hiervan.
Versterkend leren
Reinforcement learning komt het dichtst in de buurt van hoe wij mensen leren. RML-algoritmen zijn een leermethode waarbij de machine herhaaldelijk interageert met zijn omgeving door nieuwe acties te construeren en fouten of beloningen te ontdekken. Het maakt gebruik van een positief of een negatief beloningssysteem.
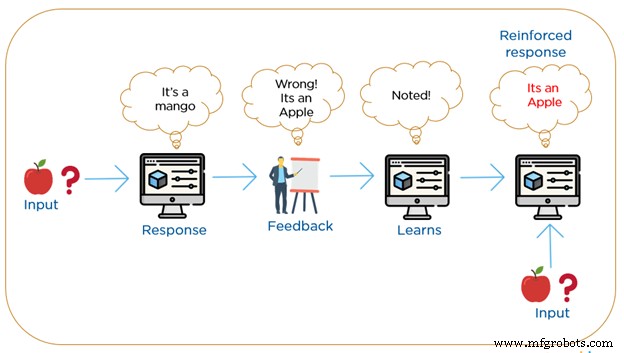
Zoeken met vallen en opstaan met uitgestelde beloning zijn de meest relevante kenmerken van versterkend leren. De machine construeert een gedrag met behulp van observaties die zijn verzameld door interactie met de omgeving en onderneemt acties die de beloning maximaliseren of het risico minimaliseren. Met deze methode kunnen de machines automatisch het ideale gedrag binnen een bepaalde context bepalen om de prestaties te verhogen. Bij het leren van versterking zijn er geen gelabelde materialen, maar in plaats daarvan vereist het eenvoudige feedback welke stap correct is en welke stap verkeerd is, dit staat bekend als het versterkingssignaal.

Volgens de standaard van feedback, herziet de machine geleidelijk zijn classificatie totdat uiteindelijk het juiste resultaat wordt verkregen. Integratie van versterkend leren is nodig om een bepaald niveau van precisie te bereiken bij niet-gesuperviseerd leren,
RML is waarschijnlijk het moeilijkst te produceren en uit te voeren in een zakelijke omgeving, maar het wordt vaak gebruikt voor zelfrijdende auto's.
Industriële technologie
- De toeleveringsketen en machine learning
- Vier belangrijke vragen voor het ontsluiten van de kracht van live veldgegevens
- Elementary Robotics haalt $ 13 miljoen op voor zijn machine learning en computer vision-aanbod aan de industrie
- Machine learning in het veld
- De rol van data-analyse voor eigenaren van activa in de olie- en gasindustrie
- De vele soorten polyurethaan en waarvoor ze worden gebruikt
- AWS versterkt zijn AI- en machine learning-aanbod
- Wat is een freesmachine en waarvoor wordt hij gebruikt?
- Kepware versus MachineMetrics:wat is de betere oplossing voor het verzamelen van machinegegevens?
- De 9 machine learning-applicaties die u moet kennen
- De molenmachine en zijn verschillende subcategorieën