


Inleiding tot datawetenschap | Belangrijkste onderdelen | Soorten en kansen
Wat is datawetenschap?
Data Science is een interdisciplinair veld waarbij wetenschappelijke methoden, processen en systemen worden gebruikt om gegevens in gestructureerde en ongestructureerde vorm te verzamelen, voor te bereiden en te analyseren. Data science maakt gebruik van verschillende gebieden, waaronder wiskunde, statistiek, databases, informatiewetenschap en informatica. De gegevens kunnen van vele soorten en van verschillende grootte zijn.
Behoefte aan Data Science als een apart veld:
De belangrijkste reden om data science te upgraden naar het niveau van een apart vakgebied is de exponentieel groeiende hoeveelheid data om ons heen. Schattingen laten zien dat in 2020 ongeveer 1,7 megabyte aan data per seconde zal worden geproduceerd. De digitale dataaccumulatie zal 44 biljoen gigabyte bereiken. Met zulke grote hoeveelheden gegevens wordt het steeds moeilijker om het te begrijpen en op te slaan. Als gevolg hiervan hebben we een manier nodig om deze gegevens te bestuderen en te begrijpen. Vandaar dat Data Science als een apart vakgebied werd erkend. 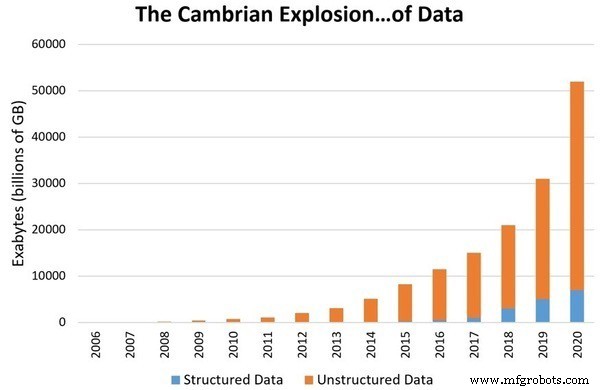
Datawetenschap om ons heen:
Bedrijven gebruiken datawetenschap om hun dataprocessen binnen het bedrijf te begrijpen en eenvoudig te sorteren. Google gebruikt bijvoorbeeld Data Science om de advertenties te personaliseren die aan gebruikers worden getoond op de websites die ze gebruiken. Dit wordt gedaan via hun programma AdSense waarmee uitgevers inhoud kunnen aanbieden aan getargete doelgroepen.
Op dezelfde manier berekent Uber hoeveel een klant in rekening moet worden gebracht, wanneer kortingen moeten worden gegeven en aan wie. Airbnb helpt mensen door met behulp van Data Science de prijs in te schatten waarvoor ze hun woning moeten huren. In eenvoudige bewoordingen kunnen we dit begrijpen door aan klanten en gebruikers te denken als onbewerkte gegevens en datawetenschap helpt bij het interpreteren van die gegevens. 
Datawetenschap in overheids- en niet-gouvernementele organisaties:
Gegevens zijn van cruciaal belang voor overheidsorganisaties. Er wordt elke dag een toenemende hoeveelheid data verzameld. Daarom hebben ze een manier nodig om al deze gegevens te sorteren en op te slaan, wat kan worden gedaan via Data Science. Evenzo maken ook niet-gouvernementele organisaties gebruik van datawetenschap. Het WWF gebruikt datawetenschappen om statistische informatie te tonen over problemen met dieren in het wild en zo hun doel effectief te maken.
Kansen in datawetenschap:
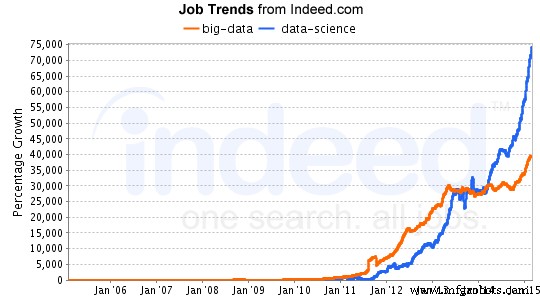
Terwijl het gebied van datawetenschap blijft groeien, nemen de kansen op werk op dit gebied ook exponentieel toe. Analyse uitgevoerd door LinkedIn over de banengroei in data science toonde een grote toename op het gebied van data science, vooral in de afgelopen 30 jaar. Als u geïnteresseerd bent in datawetenschap, kunt u gratis online cursussen volgen. Bekijk deze tutorial over een gemeenschappelijke lounge.
Belangrijkste onderdelen:
Nu zullen we u enig inzicht geven in data science en de verschillende componenten ervan.
1:Programmeren:
Data Science draait helemaal om data. Om deze gegevens te ordenen en te analyseren gebruiken we programmering. Programmeertalen zijn er in vele soorten. De twee meest voorkomende zijn Python en R.
Python: Python is de meest leesbare en flexibele programmeertaal, vandaar het wijdverbreide gebruik. Het heeft veel krachtige statistische en numerieke pakketten, waaronder NumPy en panda's, Matplotlib, Tensorflow, iPython enz. Python is veel sneller en gemakkelijker te leren.
R: R is een andere programmeertaal, maar het meeste is gericht op statistische en grafische technieken. R wordt veel gebruikt door statistici en dataminers voor het ontwikkelen van statistische software en data-analyse. Het is een open source taal.
2:Gegevens en zijn typen:
Het volgende belangrijke onderdeel zijn de gegevens zelf. Om gegevens te begrijpen, moeten we eerst de typen ervan begrijpen.
Gestructureerde gegevens: Gestructureerde data verwijst naar informatie met een hoge graad van organisatie. Het kan gemakkelijk in tabelvorm worden weergegeven, kan worden opgeslagen en verwerkt in databases.
Ongestructureerde gegevens: Ongestructureerde data is informatie die geen datamodel heeft of niet georganiseerd is. Het kan bestaan uit tekst of gegevens zoals datums, nummers, e-mails, PDF-bestanden, afbeeldingen, video's enz.
Natuurlijke taal: Gegevens in de vorm van geschreven talen die worden gebruikt om te communiceren, zoals Engels, Spaans en Urdu enz. Het kan worden beschouwd als een subtype van ongestructureerde gegevens.
Beeld, Video, Audio: Afbeeldingen, video's en audio zijn ook ongestructureerd van vorm. Ze worden gegenereerd met behulp van camera's en microfoons. Het toenemende gebruik is te zien in smartphones waar dagelijks afbeeldingen en video's worden opgeslagen en verwerkt.
Grafische gegevens: Grafiek is een verzameling hoekpunten en randen. Het is een wiskundige structuur die wordt gebruikt om de relatie tussen twee entiteiten weer te geven.
Machine gegenereerd: Machinegegenereerde gegevens worden gecreëerd door computersystemen, applicaties of machines zonder tussenkomst van mensen.
3:Statistiek, waarschijnlijkheid en de relatie met datawetenschap:
Statistieken: Statistiek is een tak van de wiskunde die zich bezighoudt met het verzamelen, interpreteren, analyseren, presenteren en ordenen van gegevens. Het maakt gebruik van pro0gamming om gegevens te analyseren.
Kans: Waarschijnlijkheid is de maatstaf voor de waarschijnlijkheid dat een gebeurtenis zich voordoet. Het wordt gekwantificeerd als een getal tussen 0 en 1, waarbij 0 staat voor onmogelijkheid en 1 voor zekerheid.
Relatie tot gegevenswetenschap: Statistiek en waarschijnlijkheid zijn beide gerelateerd aan datawetenschap. Ze vormen de basis voor het verwerken en analyseren van gegevens. We gebruiken beide wetenschappen in relatie tot datawetenschap om gegevens correct te interpreteren.
4:Machine learning:
Machine learning is het gebied van de informatica dat voortkomt uit AI. Het maakt gebruik van statistische technieken om computers de mogelijkheid te geven om te leren zonder te worden geprogrammeerd. De machine verbetert geleidelijk zijn prestaties op een specifieke taak door de structuur of het programma te veranderen. Er zijn drie hoofddoelen van machine learning. Ten eerste om de veranderingen en de weergave van deze veranderingen te leren. Ten tweede, om de prestatie te generaliseren, zodat het niet effectief is voor een enkele taak, maar voor vergelijkbare taken. Derde. Om de prestaties van een machine te verbeteren en manieren te vinden om verslechterende prestaties te voorkomen. In de datawetenschap wordt machine learning gebruikt in algoritmen, regressie- en classificatiemethoden. Het wordt gebruikt om de uitkomst te voorspellen van gegevens die op verschillende manieren worden verwerkt.
5:Big data:
Big Data is de naam die gegeven wordt aan data is zo'n grote hoeveelheid dat het opslaan of verwerken van deze data een groot aantal computers vereist. Het wordt gekenmerkt door drie V's:
Volume: Gegevens in grote volumes variërend van terabytes tot zettabytes.
Verscheidenheid: Gegevens kunnen veel variatie en diversiteit laten zien. Het kan een combinatie zijn van twee of meer soorten gegevens, bijvoorbeeld zowel gestructureerd als ongestructureerd.
Snelheid: Gegevens worden in een constant groeiend tempo gegenereerd. In wezen is het de snelheid van gegevens. 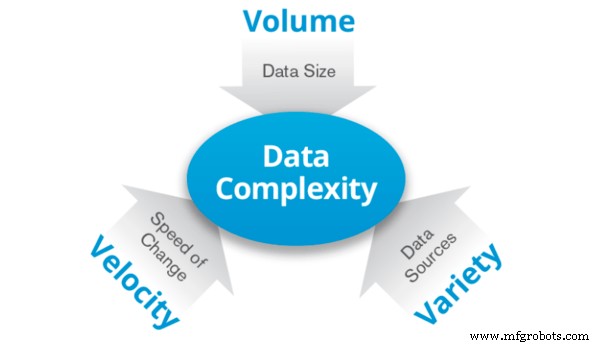
In datawetenschap worden gegevens gegroepeerd in vele vormen en typen. Big data kunnen worden aangeduid als gigantische hoeveelheden gegevens die niet kunnen worden verwerkt met traditionele applicaties. Datawetenschappers gebruiken verschillende tools om big data te bestuderen en te verwerken, bijvoorbeeld Hadoop, Spark, R en Java enz.
Industriële technologie
- termen en concepten voor digitaal geheugen
- C#-variabelen en (primitieve) gegevenstypen
- Python-gegevenstypen
- Een inleiding tot edge computing en voorbeelden van use-cases
- 5 verschillende soorten datacenters [met voorbeelden]
- C - Gegevenstypen
- MATLAB - Gegevenstypen
- C# - Gegevenstypen
- Typen en classificatie van bewerkingsprocessen | Productiewetenschap
- Freesmachines - Inleiding en soorten besproken
- Betekenis en typen productieproces