


De waarde uit data halen voor AI
Gegevens zijn alles - in veel opzichten het enige - voor verkopers van autonome voertuigen (AV's) die afhankelijk zijn van deep learning als de sleutel tot zelfrijdende auto's.
Gegevens zijn de reden waarom AV-bedrijven kilometerslange testervaring op de openbare weg verzamelen en petabytes aan verkeersinformatie vastleggen en opslaan. Waymo claimde bijvoorbeeld in juli meer dan 10 miljoen mijl in de echte wereld en 10 miljard mijl in simulatie.
Maar hier is nog een andere vraag die de industrie niet graag stelt:
Stel dat AV-bedrijven al petabytes of zelfs exabytes aan gegevens hebben verzameld op echte wegen. Hoeveel van die dataset is gelabeld? Misschien nog belangrijker:hoe nauwkeurig zijn de geannoteerde gegevens?
In een recent interview met EE Times beweerde Phil Koopman, mede-oprichter en CTO van Edge Case Research dat "niemand het zich kan veroorloven om alles te labelen."
Gegevens labelen:tijdrovend en kostbaar
Voor annotaties zijn doorgaans deskundige menselijke ogen nodig om een korte videoclip te bekijken en vervolgens dozen rond elke auto, voetganger, verkeersbord, verkeerslicht of elk ander item te tekenen en te labelen dat mogelijk relevant is voor een algoritme voor autonoom rijden. Het proces is niet alleen tijdrovend, maar ook erg kostbaar.
Een recent verhaal op Medium, getiteld "Data Annotation:The Billion Dollar Business Behind AI Breakthroughs" illustreert de snelle opkomst van "managed data labeling services" die zijn ontworpen om domeinspecifieke gelabelde gegevens te leveren met de nadruk op kwaliteitscontrole. Het verhaal merkte op:
Naast hun interne datalabelingteams, zijn technologiebedrijven en zelfrijdende startups ook sterk afhankelijk van deze beheerde labelservices... sommige zelfrijdende bedrijven betalen datalabelbedrijven tot miljoenen dollars per maand.
In een ander verhaal van IEEE Spectrum een paar jaar geleden werd Carol Reiley, medeoprichter en president van Drive.ai geciteerd:
Duizenden mensen labelen dozen rond dingen. Voor elk gereden uur kost het ongeveer 800 menselijke uren om te labelen. Deze teams zullen het allemaal moeilijk hebben. We zijn al enorm veel sneller en we optimaliseren voortdurend.
Sommige bedrijven, zoals Drive, gebruiken deep learning om de automatisering van het annoteren van gegevens te verbeteren, als een manier om het vervelende proces van het labelen van gegevens te versnellen.
Laten we niet-gelabelde gegevens gebruiken
Koopman gelooft echter dat er een andere manier is om "de waarde uit de verzamelde data te persen". Hoe zit het met het bereiken van dit "zonder de meeste petabytes aan opgenomen gegevens te labelen?"
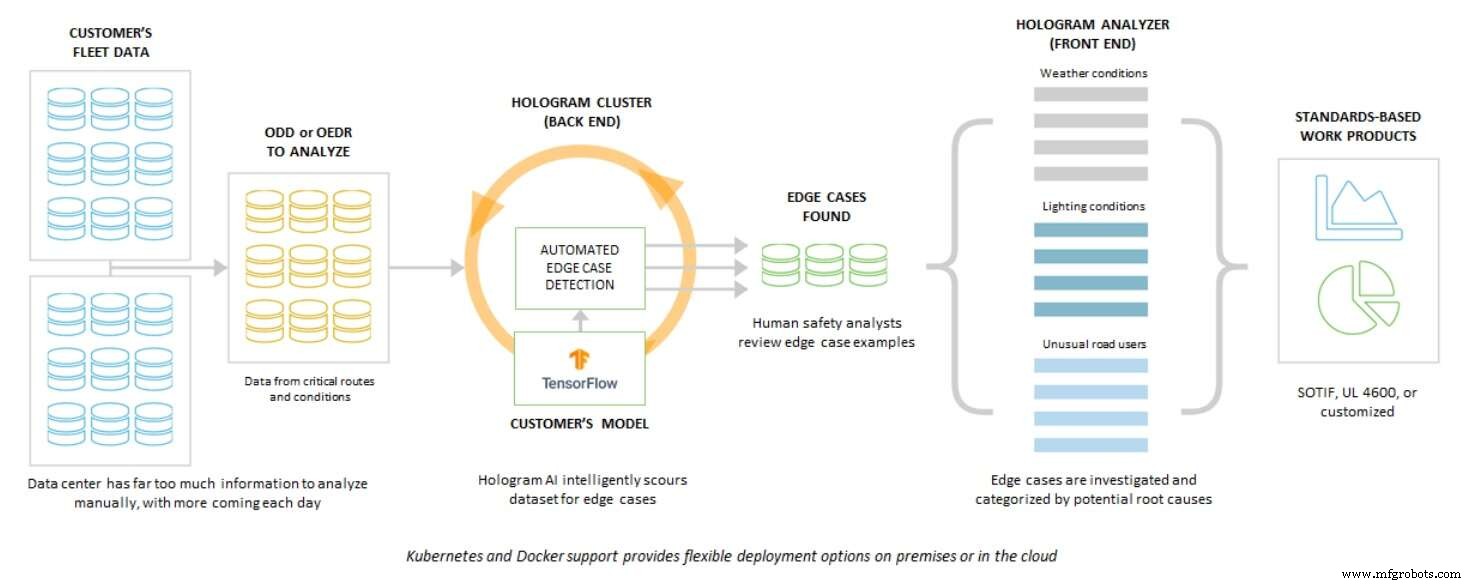
Hij legde uit dat Edge Case Research hier 'in terechtkwam' bij het bedenken van een manier om de AV-industrie in staat te stellen de ontwikkeling van veiliger waarnemingssoftware te versnellen. Edge Case Research noemt het 'Hologram', wat in wezen een 'AI-perceptie-stresstest- en risicoanalysesysteem' is dat is ontworpen voor AV's.
Meer specifiek, zoals Koopman uitlegde:"Hologram gebruikt niet-gelabelde gegevens", en het systeem voert dezelfde niet-gelabelde gegevens twee keer uit.
Ten eerste voert het baseline ongelabelde gegevens uit op een kant-en-klare, normale perceptie-engine. Vervolgens wordt met dezelfde niet-gelabelde gegevens Hologram toegepast, waardoor een zeer lichte verstoring wordt toegevoegd - ruis. Door het systeem onder druk te zetten, kan Hologram, zo blijkt, potentiële zwakte van de waarneming in AI-algoritmen blootleggen.
Als er bijvoorbeeld een beetje korrel aan een videoclip wordt toegevoegd, kan een mens waarnemen dat "er iets is, maar ik weet niet wat het is."
Maar een AI-gestuurd waarnemingssysteem, dat onder druk komt te staan, kan een onbekend object volledig missen, of het over de drempel schoppen en in een andere classificatiebak plaatsen.
Wanneer AI nog aan het leren is, is het handig om het vertrouwensniveau ervan te kennen (omdat het bepaalt wat het ziet). Maar wanneer AI in de wereld wordt toegepast, zegt het betrouwbaarheidsniveau ons niet veel. AI is vaak "gissen" of gewoon "aannemen".
Met andere woorden, AI doet alsof.
Hologram kan, door zijn ontwerp, de AI-gestuurde perceptiesoftware "porren". Het laat zien waar een AI-systeem faalde. Een gespannen systeem lost bijvoorbeeld zijn verwarring op door een object op mysterieuze wijze van het toneel te laten verdwijnen.
Misschien, interessanter, kan Hologram onder ruis ook identificeren waar AI "bijna faalde", maar goed geraden. Hologram onthult gebieden in een videoclip waar het AI-gestuurde systeem anders "ongelukkig had kunnen zijn", zei Koopman.
Zonder petabytes aan gegevens te labelen maar twee keer uit te voeren, kan Hologram een heads-up bieden waar dingen er "visachtig" uitzien, en gebieden waar "je beter terug kunt gaan en opnieuw kijken" door ofwel meer gegevens te verzamelen of meer te trainen, zei Koopman .
Dit is natuurlijk een zeer vereenvoudigde versie van Hologram, omdat de tool zelf in werkelijkheid "wordt geleverd met veel geheime sauzen ondersteund door een heleboel techniek", zei Koopman. Maar als Hologram gebruikers "alleen de goede delen" kan vertellen die menselijke beoordeling verdienen, kan dit resulteren in een zeer efficiënte manier om echte waarde te halen uit de momenteel vergrendelde gegevens.
"Machines zijn verbazingwekkend goed in het gamen van het systeem", merkte Koopman op. Of "dingen doen zoals 'p-hacking'." P-hacking is een soort vooringenomenheid die optreedt wanneer onderzoekers gegevens of statistische analyses verzamelen of selecteren totdat niet-significante resultaten significant worden. Machines kunnen bijvoorbeeld correlaties in gegevens vinden waar er geen zijn.
Open source dataset
Op de vraag of dit goed nieuws is voor Edge Case Research, zei Koopman:“Helaas worden deze datasets alleen beschikbaar gesteld voor de onderzoeksgemeenschap. Niet voor commercieel gebruik.”
Verder, zelfs als u een dergelijke dataset gebruikt om Hologram uit te voeren, moet u dezelfde perceptie-engine gebruiken die wordt gebruikt om gegevens te verzamelen, om zwakke punten in iemands AI-systeem te begrijpen.
Schermafbeelding van Hologram
Hieronder ziet u een schermafbeelding die laat zien hoe de nieuwste commerciële versie van Hologram werkt.
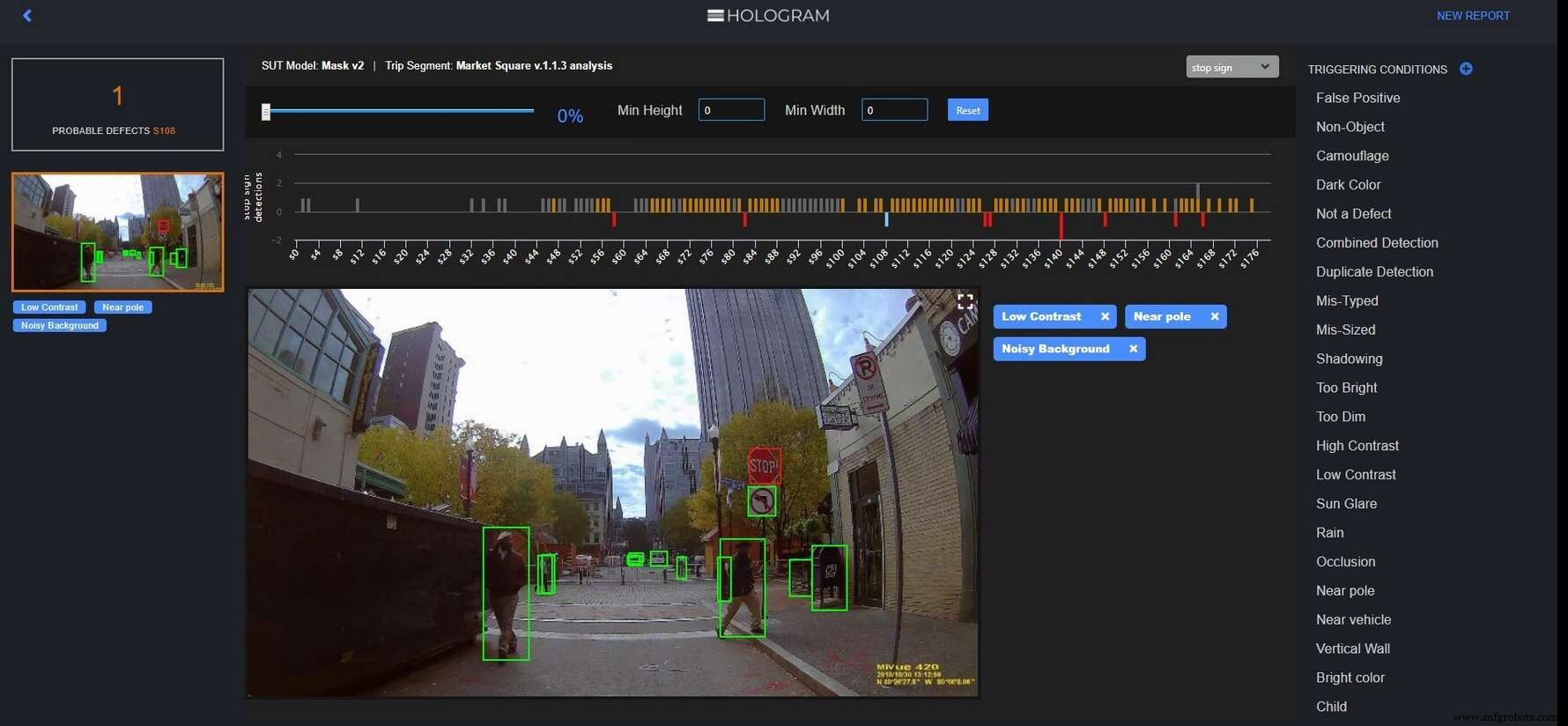
De Hologram Engine vindt gevallen waarin een waarnemingssysteem dit stopteken niet heeft geïdentificeerd en biedt analisten krachtige hulpmiddelen om triggerende omstandigheden zoals de lawaaierige achtergrond te ontdekken. (Bron:Edge Case Research)
Door ruis toe te voegen, zoekt Hologram naar triggerende omstandigheden waardoor een AI-systeem bijna een stopbord (oranje balken) miste of een stopbord volledig niet herkende (neerwaartse rode balken).
Oranje balken waarschuwen AI-ontwerpers voor specifieke gebieden die omscholing van het AL-algoritme vereisen, door meer gegevens te verzamelen. Rode balken stellen AI-ontwerpers in staat triggerende omstandigheden te verkennen en te speculeren:waardoor heeft AI het stopteken gemist? Stond het bord te dicht bij een paal? Was er een lawaaierige achtergrond of was er niet genoeg zichtbaar contrast? Als er genoeg voorbeelden van triggerende omstandigheden zijn, kan het mogelijk zijn om specifieke triggers te identificeren, legt Eben Myers, productmanager van Edge Case Research, uit.
 Hologram helpt AV-ontwerpers de randgevallen te vinden waar hun waarnemingssoftware vreemd, mogelijk onveilig gedrag vertoont. (Bron:Edge Case Research)
Hologram helpt AV-ontwerpers de randgevallen te vinden waar hun waarnemingssoftware vreemd, mogelijk onveilig gedrag vertoont. (Bron:Edge Case Research)
Samenwerking met Ansys
Eerder deze week kondigde Ansys een samenwerkingsovereenkomst aan met Edge Case Research. Ansys is van plan Hologram te integreren in zijn simulatiesoftware. Ansys ziet de integratie als een essentieel onderliggend onderdeel voor het ontwerpen van "de eerste holistische simulatietoolketen in de branche voor het ontwikkelen van AV's." Ansys werkt samen met BMW, dat heeft beloofd zijn eerste AV in 2021 te leveren.

ANSYS en BMW creëren een simulatietoolketen voor autonoom rijden (Bron:Ansys)
— Junko Yoshida, Global Co-In-Chief, AspenCore Media, Chief International Correspondent, EE Times
>> Dit artikel is oorspronkelijk gepubliceerd op onze zustersite, EE Times:"Gebruik niet-gelabelde gegevens om te zien of AI het gewoon doet alsof."
Internet of Things-technologie
- Wat moet ik doen met de gegevens?!
- Vooruitzichten voor de ontwikkeling van industrieel IoT
- Het potentieel voor het integreren van visuele data met het IoT
- Het IoT democratiseren
- De waarde van IoT-gegevens maximaliseren
- Het is tijd voor verandering:een nieuw tijdperk aan de rand
- De waarde van analoge meting
- Het podium voor succes in de industriële datawetenschap
- Trends blijven de verwerking tot het uiterste pushen voor AI
- De waarde van ondersteuning op afstand voor geautomatiseerde werkcellen
- De toekomst van datacenters