


Startup verpakt 1000 RISC-V-cores in AI-versnellerchip
Gelijktijdig met de Hot Chips-conferentie, kwam startup Esperanto deze week uit de stealth-modus met de best presterende commerciële RISC-V-chip tot nu toe - een duizend-core AI-versneller ontworpen voor hyperscale datacenters. Hoewel de chip kan worden gebruikt in een aantal spannings- en vermogensprofielen tussen 10 en 60 W, is zijn "sweet spot" 20 W vermogen per chip, een configuratie waarmee zes chips op een Glacier Point-versnellerkaart kunnen worden gemonteerd, totaal verbruik onder 120 W. Totale prestatie van zes chips is ongeveer 800 TOPS.
Esperanto's ET-SoC-1 wordt gefactureerd met de meeste RISC-V-cores ooit gebouwd op een enkele chip:1.093. De telling omvat 1.088 ET-Minion aangepaste RISC-V-kernen die dienen als energiezuinige AI-acceleratiemotoren. Ook inbegrepen zijn vier ET-Maxion RISC-V-cores en een RISC-V-serviceprocessor. Het hele ontwerp is gericht op energie-efficiëntie.
Vooruitlopend op Hot Chips, EE Times sprak met veteraan Dave Ditzel, de oprichter en uitvoerend voorzitter van Esperanto. (Ditzels geloofsbrieven omvatten co-auteurschap met David Patterson van het baanbrekende artikel "The Case for the Reduced Instruction Set Computer", gepubliceerd in 1980.)

Dave Ditzel (Bron:Esperanto)
"We zijn de eersten die duizend RISC-V-cores op één chip hebben gezet", zegt Ditzel. "Mensen hebben het al jaren over veel-core CPU's, maar daar hebben we niet veel van gezien. De meeste RISC-V-dingen die er zijn, zijn voor embedded.
"We zeiden:'Laten we ze laten zien dat RISC-V high-end kan doen... We zullen ze laten zien wat echt ervaren CPU-ontwerpers hier kunnen'."
Eisen van de klant
Het team van CPU-ontwerpers van Ditzel was in staat om details uit hyperscale datacenterbeheerders te plagen over hun vereisten.
"Ze wilden geen trainingschip, ze hebben geen probleem met trainen", zei Ditzel. AI-training is vaak een offline probleem en de enorme x86 CPU-capaciteit van hyperscalers staat niet altijd op piekbelasting. Daarom kan die capaciteit, indien beschikbaar, worden gebruikt voor training. "Hun echte probleem is gevolgtrekking", voegde Ditzel eraan toe. “Dat is wat hun reclame drijft. Ze hebben een antwoord nodig binnen 10 milliseconden of minder.”
Daarom werd het versnellen van de aanbevelingsinferentie-engine voor online adverteren een focus van de datacenterchip. De vereisten van hyperscalers voor het versnellen van dit type model waren vrij expliciet.
"Onze klanten wilden 100 megabyte geheugen op de chip - alle dingen die ze wilden doen met inferentie pasten in 100 megabyte", zei hij. Klanten wilden ook een externe interface voor off-chip geheugen. "Het echte probleem is hoeveel je op de acceleratiekaart kunt houden", legt Ditzel uit. “Zie de kaart als de rekeneenheid, niet als de chip. Als je eenmaal geheugen op de kaart kunt krijgen, heb je veel sneller toegang tot dingen dan over de PCIe-bus naar de host te gaan."
klik voor afbeelding op volledige grootte

In het Esperanto passen zes dubbele M.2-kaarten, elk met één chip, op een Glacier Point-versnellerkaart. (Bron:Esperanto)
Het on-chip geheugensysteem heeft L1-, L2- en L3-caches en een volledig hoofdgeheugensysteem met registerbestanden van in totaal iets meer dan 100 MB. Het geheugensysteem op de kaart kan de meeste gewichten en activeringen in het model van ongeveer 100 GB bevatten.
Aanbevelingsmodellen zijn notoir moeilijk te versnellen, wat een van de redenen is dat ze nog steeds op bestaande CPU-servers draaien.
"Als je 100 miljoen klanten kiest en wat ze recentelijk hebben gekocht, moet je toegang hebben tot dit ... geheugen op de kaart, en je doet allerlei willekeurige geheugentoegangen, dus caches niet het werk. Je hebt echt meer een klassieke computer nodig', zegt Ditzel. De "x86-servers kunnen grote hoeveelheden geheugen aan en ze hebben pre-fetching, en CPU's voor algemeen gebruik kunnen die werkbelasting heel goed aan. Daarom is het voor accelerators moeilijk geweest om door te breken in de aanbevelingsbusiness.”
Ook vereist is ondersteuning voor INT8 samen met FP16- en FP32-gegevenstypen. De vereiste voor drijvende-komma-wiskunde komt voort uit zowel de noodzaak om de hoogst mogelijke voorspellingsnauwkeurigheid te behouden als het gebrek aan neiging om programma's over te zetten of te herschrijven voor wiskunde met een lagere precisie. Ditzel zei dat toonaangevende fabrikanten van x86-serverchips pas onlangs 8-bit vectorextensies aan server-CPU's hebben toegevoegd.
"De meeste gevolgtrekkingen in [een hyperschaal datacenter] op hun miljoen x86-servers zijn nog steeds 32-bits float", zei hij.
Esperanto's chip op een dubbele M.2-kaart is ontworpen om te passen in acceleratorslots binnen de bestaande x86 CPU-serverinfrastructuur. Dat resulteert in een vermogenslimiet van 120 W, waarvoor luchtkoeling nodig is.
Ditzel zei dat het ontwerp van Esperanto niet rechtstreeks concurreert met interne inspanningen zoals Google TPU's of Inferentia van Amazon Web Services. Hyperscalers “proberen de hele gemeenschap zover te krijgen om acceleratorchips voor hen te bouwen. Veel van deze bedrijven geloven in open computing en het [Open Compute Project].” Vandaar dat "ze OCP-servers kopen en ze willen dat er gestandaardiseerde dingen in gaan. Als er concurrentie is, vinden ze het geweldig... ze proberen concurrentie aan te moedigen en mensen te laten zien wat er mogelijk is.”
Toch dringt de startup erop aan dat exploitanten van grote datacenters externe leveranciers nodig hebben voor versnellerchips. "Het is nog altijd een make-versus-buy-beslissing." Zo had een Esperanto-klant geen toegang tot intern ontwikkelde chips die door een andere divisie werden gebruikt. "Als je verslaat wat ze hebben, is toegang tot een van deze bedrijven mogelijk."
Nieuwe aanpak
Esperanto heeft de tegenovergestelde benadering gekozen van de gigantische stroomverslindende chipversnellers van concurrenten, door een chip met een lager vermogen aan te bieden die in veelvoud kan worden gebruikt. De aanpak richt zich op de vereisten voor geheugenbandbreedte, aangezien er meer pinnen kunnen worden gebruikt voor geheugen-I/O zonder een beroep te hoeven doen op dure HBM.
De hardware van Esperanto is ook ontworpen als een computer voor algemeen gebruik; ondanks de focus op aanbevelingsmodellen kan de chip volgens Ditzel de parallelle verwerking versnellen. Een versnellerkaart met zes chips bevat ongeveer 6000 parallelle kernen en elke kern kan twee threads uitvoeren, die "bij elk willekeurig probleem kunnen worden weggegooid".
Een andere truc in de mouw van Esperanto is een agressief, energiezuinig ontwerp. De eisen van de klant stellen het stroombudget op 120 W in totaal, terwijl de maximale ruimte op een Glacier Point-kaart zes chips was, of 20 W per chip. Ter vergelijking:AI-inferentieversnellers werken met meer dan tien keer zoveel.
Esperanto pakte de kwestie vanuit verschillende hoeken aan. De klokfrequentie werd teruggebracht tot een optimaal niveau van ongeveer 1 GHz. De voedingsspanning werd teruggebracht tot ongeveer 0,4 V, buiten de limiet van SRAM's. Schakelcapaciteit werd geholpen door gebruik te maken van magere RISC-V-kernen met de kleinste commercieel haalbare instructieset om het aantal transistors te verminderen. Er werd gekozen voor een geavanceerde maar stabiele procestechnologie, TSMC 7nm.
klik voor afbeelding op volledige grootte
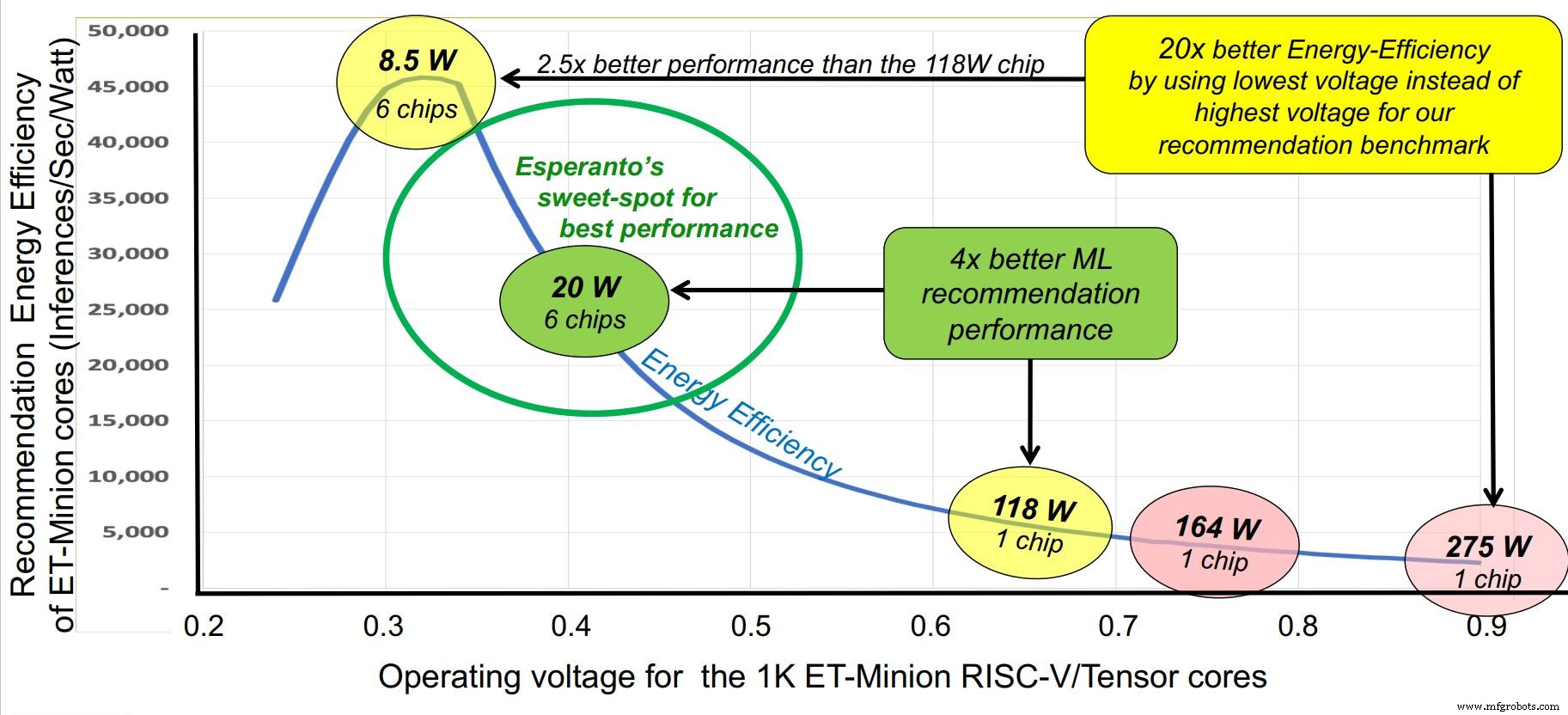
Esperanto identificeerde een "sweet spot" voor werking op ongeveer 1 GHz. (Bron:Esperanto)
Kernontwerp
De chip van Esperanto bevat 1.088 ET-Minion-kernen, die de AI-werklast verwerken. De kernen zijn 64-bits, in orde RISC-V-processors met Esperanto's eigen AI-geoptimaliseerde vector- en tensoreenheid die een groot deel van het chipvastgoed in beslag nemen. Floating-point MAC's domineren de configuratie. Ongebruikelijk hebben integere MAC's tweemaal de verwerkingsbreedte van drijvende komma (volgens de eisen van de klant, merkte Ditzel op). Ook worden vector transcendentale instructies ondersteund, zoals sigmoid-functies die veel voorkomen in deep learning-modellen. Omdat de kernen in een enkel laagspanningsdomein draaien, werden er meer transistors gebruikt met SRAM in de kleine L1-cache om robuuste prestaties te garanderen.
klik voor afbeelding op volledige grootte
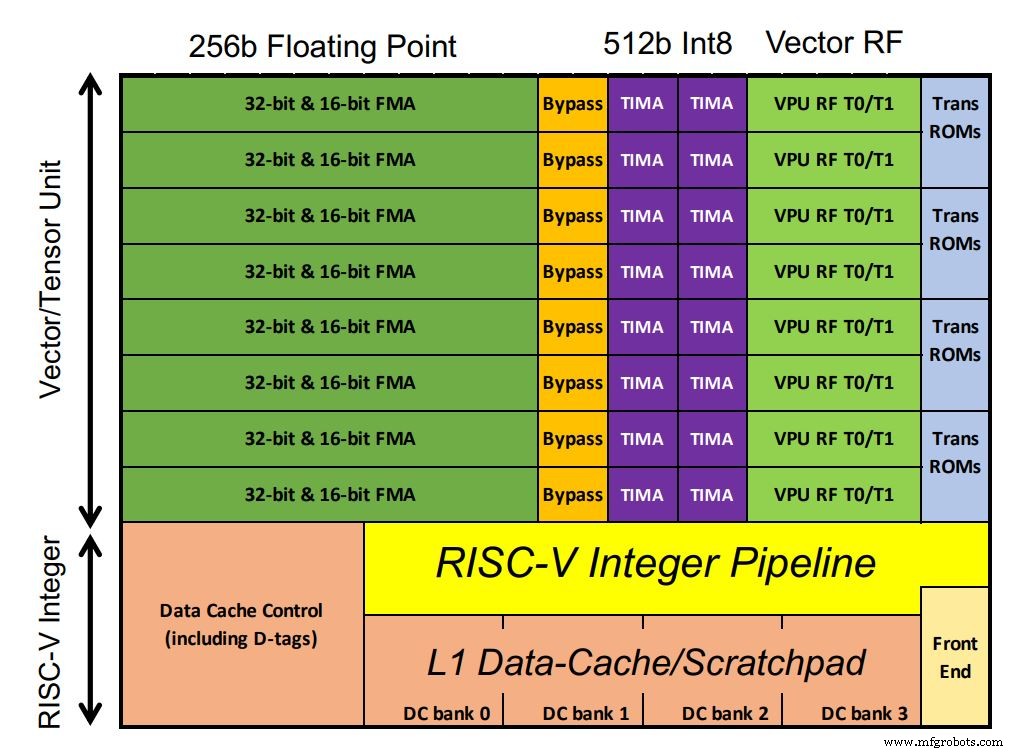
Esperanto's chip bevat 1.088 ET-Minion-kernen (klik op afbeelding om te vergroten) (Bron:Esperanto)
Elke kern is in staat tot 128 GOPS per GHz. Een aangepaste multi-cycle tensor-instructie voert grote matrixvermenigvuldigingen uit waarbij een afzonderlijke controller tot 512 cycli overneemt en uitvoert met behulp van de volledige 512-bits breedte. Hierdoor kan de enkele tensor-instructie meer dan 64.000 rekenkundige bewerkingen uitvoeren voordat de controller de volgende RISC-V-instructie ophaalt. Dat vermindert de instructiebandbreedte, aangezien het grootste deel van de werklast de tensorinstructie gebruikt. Er is dus slechts één instructie per 512 klokcycli nodig.
Acht ET-Minion-kernen vormen een 'buurt' en aangepaste instructies maken gebruik van hun fysieke nabijheid. Een andere functie die "coöperatieve belastingen" wordt genoemd, stelt kernen in staat om gegevens rechtstreeks van elkaar over te dragen zonder cache-ophaalactie. Die configuratie bespaart stroom. De acht cores delen ook een grote L2-cache voor energie-efficiëntie.
Weer uitzoomen, vier 8-core buurten vormen een "Minion Shire", met 34 shires op elke chip, in totaal 1.088 cores. (Berekening met slechts 1024 cores om de opbrengst te verbeteren is ook mogelijk, zei Ditzel). Vier ET-Maxion-kernen, elk met prestaties die ongeveer vergelijkbaar zijn met die van een Arm A-72, zijn bedoeld voor toekomstige stand-alone werking, in plaats van de huidige acceleratieconfiguratie.
Drempelspanningsvariaties worden beperkt door elke Shire zijn eigen voedingsspanning te geven, zodat individuele spanningen nauwkeurig kunnen worden afgesteld.
Geheugensysteem
Elke chip heeft vier 64-bits DDR-interfaces - eigenlijk vertegenwoordigt elke interface vier 16-bits kanalen - voor een totaal van 96x 16-bits kanalen. Het ontwerp maakt gebruik van LPDDR4x ontwikkeld als low-power geheugen voor smartphones. De energie per bit is ongeveer gelijk aan HBM, maar het handhaven van het totaal op 1.536 bits over de geheugeninterface voor de zes-chip-versnellerkaart levert een hogere totale geheugenbandbreedte op.
Esperanto monteerde zijn chips op dual-socket M.2-kaarten; zes passen op een OCP Glacier Point v2-versnellerkaart (drie voor, drie achter). Dat levert zo'n 800 TOPS op met de chips op 1 GHz. Ze kunnen ook worden gemonteerd op PCIe-kaarten met een laag profiel (halve hoogte, halve lengte) die het stroombudget van elke chip verhogen tot ongeveer 60 W. De chips kunnen werken tussen 300 MHz en 2 GHz, afhankelijk van de toepassing.
Op basis van hardware-emulatieresultaten beweerde Ditzel dat zes Esperanto-chips op een Glacier Point-kaart beter kunnen presteren dan concurrenten. Het voordeel van de startup wordt uitgesproken voor aanbevelingsbenchmarks wanneer rekening wordt gehouden met het ontwerp van het geheugensysteem en de prestaties per watt, een gevolg van de focus op een laagspanningsontwerp.
Toekomstige versies kunnen een verkleinde versie van ET-SoC-1 bevatten voor edge-toepassingen. Ditzel zei dat de huidige versie binnen "de komende paar maanden" zou moeten verschijnen.
>> Dit artikel is oorspronkelijk gepubliceerd op onze zustersite, EE Tijden.
Verwante inhoud:
- AI-compatibele SoC's verwerken meerdere videostreams
- Xilinx richt zich op de offload van datacenters met 'composable' hardware
- Reduced Operation Set Computing (ROSC) voor NNA functionele dekking
- Hybride architectuur versnelt AI, vision-workloads
- Hardwareversnellers dienen voor AI-toepassingen
Abonneer u voor meer Embedded op de wekelijkse e-mailnieuwsbrief van Embedded.
Ingebed
- Revolver
- Een helder vooruitzicht voor EDA in de cloud
- RISC-V Summit:hoogtepunten op de agenda
- Arm maakt aangepaste instructies voor Cortex-M-kernen mogelijk
- Als een DSP een hardwareversneller verslaat
- Ontwerpen met Bluetooth Mesh:chip of module?
- AI-chiparchitectuur richt zich op grafiekverwerking
- Kleine Bluetooth 5.0-module integreert chipantenne
- Onderzoekers bouwen kleine authenticatie-ID-tag
- 30 fps automotive imaging radarprocessor debuteert
- Low-power radarchip maakt gebruik van spiking neurale netwerken