


Data Lake vs. Big Data voor industriële toepassingen
Data lake en big data zijn twee moderne termen die vaak verkeerd worden opgevat en verkeerd worden gebruikt. Vanwege de impliciete grote hoeveelheden gegevens worden deze termen soms door elkaar gebruikt. Data lake en big data zijn echter verschillend, hoewel hun huidige definities misschien nog niet volledig zijn vastgesteld.

Figuur 1. Moderne gegevens kunnen uit vele bronnen komen en van verschillende typen zijn. Afbeelding gebruikt met dank aan Analytics Vidhya
Laten we eerst kijken naar een korte historische context. In de late jaren 2000, met de explosieve groei van sociale-mediaplatforms, zoals Facebook en Twitter, begonnen veel datawetenschappers het potentieel van dergelijke platforms te beseffen voor het genereren van grote hoeveelheden waardevolle persoonlijke gegevens. Daarom werden nieuwe softwaretoepassingen ontwikkeld om de gegevensverwerking en -analyse te vergemakkelijken. Een prominent voorbeeld is Apache Hadoop, in wezen een toolkit van open source-applicaties die big data-informatieniveaus kunnen verwerken.
In het volgende decennium deed het Internet of Things (IoT) zijn intrede. Dit opende de deuren voor miljoenen meer gegevensbronnen die inzicht konden geven in de voorkeuren en patronen van een persoon, terwijl ze ook informatie over het product zelf konden verzenden.
Tegelijkertijd boekte machine learning belangrijke vooruitgang en vond meer praktische toepassingen in het industriële landschap. Dit resulteerde in een grotere behoefte om grote hoeveelheden gegevens in de industrie te verwerken, met name in geautomatiseerde processen.
Alle prognoses geven aan dat de totale hoeveelheid beschikbare gegevens in de wereld de komende jaren in versneld tempo zal blijven groeien. Ter referentie:in 2016 passeerde de wereld de mijlpaal van 1 Zettabyte aan jaarlijks gegenereerd internetverkeer. Eén Zettabyte is gelijk aan 1 biljoen Gigabytes.
Het jaarlijkse internetverkeer zal naar verwachting in 2021 meer dan 3 Zettabyte bedragen. Deze prognoses, samen met de uitgebreide mogelijkheden van cloud computing, geven aan dat de waarde en het gebruik van big data (en datameren) misschien nog maar net begonnen zijn.
Wat is big data?
Als we het simpelweg vanuit het perspectief van volume bekijken, is de definitie van big data een bewegend doel. Naarmate de hoeveelheid beschikbare gegevens en opslagruimte blijft groeien, groeit ook de maatstaf voor wat als grote hoeveelheden informatie wordt beschouwd.
Tegenwoordig wordt een datarepository van 100 terabyte of meer over het algemeen beschouwd als in het bereik van big data. Grote gegevensopslagplaatsen, zoals die van sociale-mediaplatforms, kunnen in het bereik van enkele Petabytes liggen.
Een andere referentie die wordt gebruikt om big data te definiëren, is wanneer de hoeveelheid informatie niet kan worden verwerkt door traditionele computerhulpmiddelen, zoals SQL. Tegenwoordig is het bijvoorbeeld niet ongebruikelijk dat databases jaarlijks 1 terabyte bereiken. Maar nu SQL-applicaties krachtiger worden, kan deze omvang van de database nog steeds worden beheerd; daarom worden ze doorgaans niet als big data beschouwd.
Big Data's 4V-model
Tot nu toe hebben we de definitie van big data bekeken vanuit het perspectief van volume. Er zijn nog drie andere belangrijke factoren waarmee u rekening moet houden:snelheid, variëteit en waarachtigheid. Deze vormen samen met het volume het 4V-model.
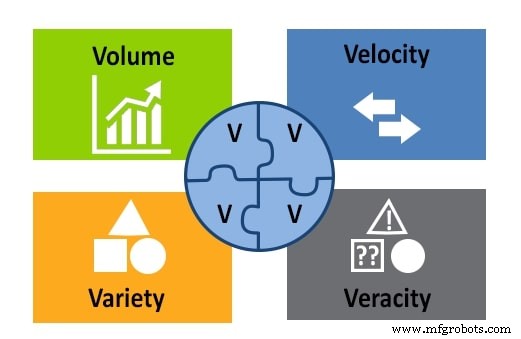
Figuur 2. Het 4V-model van big data:volume, snelheid, variëteit en waarachtigheid. Afbeelding gebruikt met dank aan APSense
Variety verwijst naar alle verschillende soorten gegevens die zijn opgeslagen in een big data-repository:tekst, afbeeldingen, geluid, video, enz. Het verwijst ook naar het feit dat gegevens uit meerdere bronnen kunnen komen.
Velocity is een belangrijke overweging bij big data omdat de informatie constant binnenstroomt. Velocity houdt zich bezig met de snelheid waarmee gegevens worden verzameld, gegenereerd en gedistribueerd.
Waarachtigheid meet de nauwkeurigheid en kwaliteit van de gegevens om te evalueren of een datawetenschapper deze kan gebruiken voor analyse en om er conclusies uit te trekken.
Laten we, nu we big data begrijpen, eens kijken naar data lakes voordat we ons verdiepen in het gebruik ervan in een besturingssysteem.
Wat is een datameer?
Datameren zijn gecentraliseerde opslagplaatsen van grote hoeveelheden ruwe data, informatie die in de toekomst al dan niet waardevol kan zijn en waarvan het doel nog niet 100% bekend is. Datameren kunnen relationele en niet-relationele databases opslaan, samen met andere soorten bestanden en entiteiten.
Hoewel de informatie in een data lake niet wordt verwerkt of georganiseerd, is deze zo gestructureerd dat alle input en output worden beschouwd als een goede architectuur.
Data Lake versus Big Data
Een data lake is een instantie van een big data-toepassing. Ze volgen de criteria beschreven in het 4V-model, met enkele extra bijzonderheden. Qua volume bevinden datameren zich gemiddeld aan de onderkant van wat als big data wordt beschouwd.
Informatie in datameren kent variatie, maar de voorwaarde is dat het alleen onbewerkte ruwe data is. Invoer- en uitvoersnelheden zijn net zo relevant als bij elk modern systeem en evaluaties van de gegevenskwaliteit worden uitgevoerd in een goed ontworpen datameer.
Industriële toepassingen voor gegevens
Geavanceerde automatisering zorgt voor een snelle toename van de hoeveelheid informatie die op de fabrieksvloer wordt verwerkt. Hierdoor betreden productie- en andere industriële processen nu het domein van big data, waarbij verschillende bedrijfsactiviteiten nu gebruikmaken van tools zoals data lakes.
Een prominent voorbeeld is predictief onderhoud. Het vermogen om een mechanische of elektrische storing te voorspellen is zeer waardevol en kan aanzienlijke besparingen op reparatiekosten opleveren. Datameren zijn handige tools die informatie kunnen verzamelen die afkomstig is van logbestanden, meerdere sensoren en invoerapparaten, die kunnen worden gebruikt om trends te begrijpen en problemen te voorspellen.
Machine learning is een concept waarbij robots worden voorzien van informatie die hen kan helpen zich aan te passen aan veranderende externe omstandigheden. Het vastleggen van informatie is vergelijkbaar met voorspellend onderhoud, met als extra stap dat evaluaties en wijzigingen in het proces automatisch worden doorgegeven aan de systeemcontroller. Machine learning-gegevens kunnen worden opgeslagen in een gestructureerd datameer.
Figuur 3. Machine learning heeft verschillende strategieën die elk grote hoeveelheden gegevens vereisen. Afbeelding gebruikt met dank aan WordStream
Kortom, een data lake is een voorbeeld van een big data-toepassing. Deze twee manieren om gegevens te bekijken, kunnen samenwerken. Door gebruik te maken van zowel big data als data lake, kan een regeltechnicus storingen voorspellen, onderhoudsroutines creëren, de digitale transformatie van de faciliteit laten groeien en nog veel meer.
Waarvoor gebruikt u big data en datameren in uw werk?
Internet of Things-technologie
- Sensoren en processors komen samen voor industriële toepassingen
- Cervoz:de juiste flash-opslag kiezen voor industriële toepassingen
- GE introduceert cloudservice voor industriële data, analyse
- Vooruitzichten voor de ontwikkeling van industrieel IoT
- Vier grote uitdagingen voor het industriële Internet of Things
- Zes essentiële zaken voor succesvolle sensorgeïnformeerde toepassingen
- Big data begrijpen:RTU's en procescontroletoepassingen
- Het podium voor succes in de industriële datawetenschap
- Voor echt industrieel internetinzicht:niet alleen data vastleggen, maar ook gebruiken
- Zal big data een oplossing bieden voor noodlijdende gezondheidsbudgetten?
- 7 Industriële IoT-toepassingen