


Diepe duik in de levenscyclus van datawetenschap
Sinds de komst van big data heeft de moderne computerwetenschap nieuwe benchmarks voor mogelijkheden en verwerkingskracht bereikt. Tegenwoordig is het niet ongebruikelijk om applicaties te vinden die datasets van 100 terabyte of meer produceren, wat als big data wordt beschouwd.
Met zulke grote hoeveelheden informatie bij de hand, is het gemakkelijk om ongeorganiseerd te raken en tijd te verspillen met nutteloze inhoud. Dit zijn twee redenen waarom het erg belangrijk is om een methodologie te volgen die de doeltreffendheid en efficiëntie van een big data-project verhoogt.

Figuur 1. Moderne datawetenschap werkt met zeer grote datasets, ook wel big data genoemd.
De levenscyclus van datawetenschap biedt een raamwerk dat helpt bij het definiëren, verzamelen, organiseren, evalueren en implementeren van big data-projecten. Het is een iteratief proces dat bestaat uit een reeks stappen die in een logische volgorde zijn gerangschikt, waardoor feedback en kantelen wordt vergemakkelijkt.
Hoe ziet de volgorde van de levenscyclus eruit? Het antwoord is dat er niet één universeel model is dat iedereen volgt. Veel bedrijven die big data-projecten uitvoeren, passen de levenscyclus van datawetenschap aan hun bedrijfsprocessen aan, meestal met meer stappen. Toch hebben alle vele modellen en processtromen een gemeenschappelijke deler. In dit artikel wordt het CRISP-DM-procesmodel gebruikt, dat een van de eerste en meest populaire levenscyclusmodellen voor datawetenschap is.
Het CRISP-DM-model
CRISP-DM staat voor Cross Industry Standard Process for Data Mining. Het werd voor het eerst gepubliceerd in 1999 door ESPRIT, een Europees programma voor het stimuleren van onderzoek in informatietechnologie (IT). Het CRISP-DM-model bestaat uit zes stappen of fasen die het big data-project begeleiden. Het moedigt belanghebbenden aan om over het bedrijf na te denken door belangrijke vragen over het probleem te stellen en te beantwoorden.
Laten we de zes fasen van het CRISP-DM-model in detail bekijken.
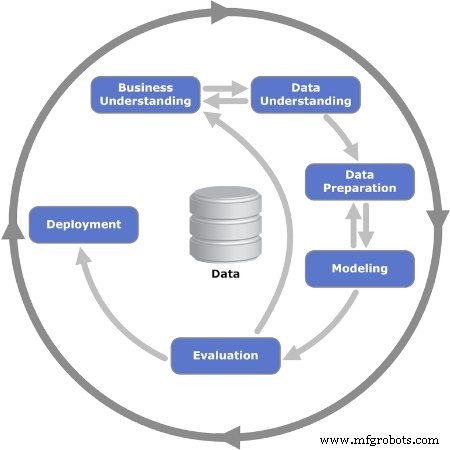
Figuur 2. De iteratieve zes fasen van het CRISP-DM-model worden getoond. Afbeelding gebruikt met dank aan Kenneth Jensen
Fase 1:Zakelijk inzicht
De eerste fase bestaat uit verschillende taken die het probleem definiëren en doelen stellen. Dit is wanneer de projectdoelstellingen worden bepaald met de focus op het bedrijf - of met andere woorden, de klant. Normaal gesproken moet het team dat is samengesteld om aan een big data-project te werken, een oplossing aan de klant leveren, wat een ander gebied of een andere afdeling binnen het bedrijf kan zijn.
Zodra de zakelijke behoefte of het probleem is vastgesteld, is de volgende stap het definiëren van succescriteria. Dit kunnen KPI's (Key Performance Indicators) of Service Level Agreements (SLA's) zijn, die objectieve middelen bieden om de voortgang en voltooiing te evalueren.
Vervolgens moet de bedrijfssituatie worden geanalyseerd om risico's, terugdraaiplannen, noodmaatregelen en, nog belangrijker, de beschikbaarheid van middelen te identificeren. Er wordt een projectplan opgesteld, inclusief hulpmiddelen voor mijlpalen.
Fase 2:Gegevens begrijpen
Zodra de fundamenten in de vorige fase zijn vastgesteld, is het tijd om je op de gegevens te concentreren. Deze fase begint met een eerste definitie van welke gegevens nodig worden geacht, en documenteert er vervolgens enkele details over:waar ze te vinden zijn, type gegevens, formaat, relaties tussen verschillende gegevensvelden, enz.
Nu de eerste documentatie gereed is, is de volgende stap het uitvoeren van de eerste dataverzamelingsrun. Dit biedt een bruikbare momentopname van hoe de structuur zich vormt. Deze momentopname van informatie wordt vervolgens beoordeeld op kwaliteit.
Fase 3:Gegevensvoorbereiding
De derde fase versterkt de vorige fase en bereidt de dataset voor op modellering. Gegevensvelden uit de eerste verzameling worden verder samengesteld en alle overbodige informatie wordt uit de set verwijderd:dit wordt het opschonen van de gegevens genoemd.
Ook kan het nodig zijn dat een specifiek stuk informatie wordt afgeleid uit andere beschikbare informatie; andere keren moet het worden gecombineerd. Met andere woorden, de gegevens moeten worden verwerkt om een definitief formaat te produceren.
Fase 4:Modelleren
De belangrijkste taak in deze fase is het selecteren van een algoritme om de verzamelde gegevens te verwerken. In deze context is een algoritme een reeks reeksstappen en regels die zijn geprogrammeerd in computersoftware die is ontworpen voor big data-projecten.
Er kunnen veel algoritmen worden gebruikt:lineaire regressies, beslissingsbomen en ondersteunende vectormachines zijn enkele voorbeelden. Het kiezen van het juiste algoritme om het probleem op te lossen vereist vaardigheden die ervaren datawetenschappers hebben.
Figuur 3. Lineaire regressie is een type algoritme dat wordt gebruikt bij het modelleren van big data.
De volgende stap is het coderen van het algoritme in de softwaretoepassing. Dit is ook wanneer de testfase wordt gepland, die bestaat uit het toewijzen van specifieke datasets voor testen en validatie.
Fase 5:Evaluatie
Soms is het moeilijk om vanaf het begin een algoritme te kiezen. Wanneer dit gebeurt, voeren wetenschappers verschillende algoritmen uit en analyseren ze de resultaten om tot een definitieve beslissing te komen. Zodra de testfase is voltooid, worden de resultaten beoordeeld op volledigheid en nauwkeurigheid.
Belangrijker is dat dit een kans is om te beoordelen of de resultaten leiden tot een oplossing. In het iteratieve model is dit een cruciaal kruispunt waar grote iteratiereeksen kunnen worden gelanceerd of kan worden besloten om naar de laatste fase te gaan.
Fase 6:implementatie
Dit is wanneer het project van een testomgeving naar een live productieomgeving gaat. Het plannen van het implementatieschema en de strategie is erg belangrijk om risico's en mogelijke systeemuitval te verminderen.
Hoewel het modeldiagram suggereert dat dit het einde van het project is, volgen er daarna nog tal van stappen:monitoring en onderhoud. Monitoring is een periode van nauwkeurige observatie, ook wel hypercare genoemd, direct na go-live. Onderhoud is een semi-permanent proces voor het onderhouden en upgraden van de geïmplementeerde oplossing.
Big data wordt niet voor niets zo genoemd:er is een enorme hoeveelheid gegevens om te analyseren. Het implementeren van een van de data science-levenscyclusmodellen helpt om te beslissen welke informatie het waard is om te bewaren en te gebruiken voor processen zoals voorspellend onderhoud.
Internet of Things-technologie
- Buiten de smartphone:data omzetten in geluid
- Uitbestede AI en deep learning in de zorgsector – loopt de gegevensprivacy gevaar?
- Onderhoud in de digitale wereld
- De levenscyclus van de simkaart stroomlijnen
- Het IoT democratiseren
- De waarde van IoT-gegevens maximaliseren
- Datawetenschap in handen geven van domeinexperts om waardevollere inzichten te leveren
- Waarom directe verbinding de volgende fase is van industrieel IoT
- De waarde van analoge meting
- Tableau, de gegevens achter de informatie
- Het podium voor succes in de industriële datawetenschap