


Edge AI daagt geheugentechnologie uit
Met de opkomst van AI aan de rand komen er een hele reeks nieuwe vereisten voor geheugensystemen. Kunnen de huidige geheugentechnologieën voldoen aan de strenge eisen van deze uitdagende nieuwe toepassing, en wat beloven opkomende geheugentechnologieën voor edge AI op de lange termijn?
Het eerste dat u moet beseffen, is dat er geen standaard "edge AI" -toepassing is; de edge in zijn breedste interpretatie omvat alle elektronische systemen met AI buiten de cloud. Dat kan 'near edge' zijn, dat over het algemeen enterprise datacenters en on-premise servers omvat.
Verderop zijn toepassingen zoals computer vision voor autonoom rijden. Gateway-apparatuur voor productie voert AI-inferentie uit om te controleren op gebreken in producten op de productielijn. 5G "edge boxes" op elektriciteitsmasten analyseren videostreams voor smart city-toepassingen zoals verkeersbeheer. En de 5G-infrastructuur gebruikt AI aan de rand voor complexe maar efficiënte bundelvormende algoritmen.
Aan de "verre kant" wordt AI ondersteund in apparaten zoals mobiele telefoons - denk aan Snapchat-filters - spraakbesturing van apparaten en IoT-sensorknooppunten in fabrieken die sensorfusie uitvoeren voordat de resultaten naar een ander gateway-apparaat worden verzonden.
De rol van geheugen in edge AI-systemen - om neurale netwerkgewichten, modelcode, invoergegevens en tussentijdse activeringen op te slaan - is hetzelfde voor de meeste AI-toepassingen. Workloads moeten worden versneld om de AI-computercapaciteit te maximaliseren om efficiënt te blijven, dus de eisen aan capaciteit en bandbreedte zijn over het algemeen hoog. Toepassingsspecifieke eisen zijn echter talrijk en gevarieerd, en kunnen betrekking hebben op grootte, stroomverbruik, laagspanningswerking, betrouwbaarheid, thermische/koelingsoverwegingen en kosten.
Edge-datacenters
Edge-datacenters zijn een belangrijke edge-markt. De use cases variëren van medische beeldvorming, onderzoek en complexe financiële algoritmen, waarbij privacy uploaden naar de cloud in de weg staat. Een andere is zelfrijdende voertuigen, waar latentie dit voorkomt.
Deze systemen gebruiken dezelfde geheugens als op servers in andere applicaties.
"Het is belangrijk om DRAM met lage latentie te gebruiken voor snel hoofdgeheugen op byteniveau in toepassingen waar AI-algoritmen worden ontwikkeld en getraind", zegt Pekon Gupta, solution architect bij Smart Modular Technologies, een ontwerper en ontwikkelaar van geheugenproducten. “Voor grote datasets zijn RDIMM's of LRDIMM's met hoge capaciteit nodig. NVDIMM's zijn nodig voor systeemversnelling - we gebruiken ze voor schrijfcaching en checkpointing in plaats van langzamere SSD's."

Pekon Gupta
Het lokaliseren van computerknooppunten in de buurt van eindgebruikers is de aanpak van telecommunicatiebedrijven.
"We zien een trend om deze [telco] edge-servers beter in staat te stellen om complexe algoritmen uit te voeren", zei Gupta. Vandaar dat "serviceproviders meer geheugen en verwerkingskracht aan deze edge-servers toevoegen met behulp van apparaten zoals RDIMM, LRDIMM en permanent geheugen met hoge beschikbaarheid zoals NVDIMM."
Gupta ziet Intel Optane, het niet-vluchtige 3D-Xpoint-geheugen van het bedrijf waarvan de eigenschappen tussen DRAM en Flash liggen, als een goede oplossing voor server-AI-toepassingen.
"Zowel Optane DIMM's als NVDIMM's worden gebruikt als AI-versnellers", zei hij. “NVDIMM's bieden tiering met zeer lage latentie, caching, schrijfbuffering en metadataopslagmogelijkheden voor AI-toepassingsversnelling. Optane datacenter-DIMM's worden gebruikt voor in-memory databaseversnelling waarbij honderden gigabytes tot terabytes aan persistent geheugen worden gebruikt in combinatie met DRAM. Hoewel dit beide persistente geheugenoplossingen zijn voor AI/ML-acceleratietoepassingen, hebben ze verschillende en afzonderlijke gebruiksscenario's.”
Kristie Mann, Intel's directeur productmarketing voor Optane, vertelde EE Times Optane krijgt steeds meer toepassingen in het server-AI-segment.

Kristie Mann van Intel
"Onze klanten gebruiken momenteel al het persistente geheugen van Optane om hun AI-applicaties van stroom te voorzien", zei ze. “Ze sturen met succes e-commerce, video-aanbevelingsmotoren en realtime financiële analyses aan. We zien een verschuiving naar in-memory applicaties vanwege de toegenomen beschikbare capaciteit.”
De hoge prijzen van DRAM maken Optane steeds vaker een aantrekkelijk alternatief. Een server met twee Intel Xeon Scalable-processors plus Optane persistent geheugen kan tot 6 terabyte aan geheugen bevatten voor dataverslindende applicaties.
"DRAM is nog steeds het populairst, maar het heeft zijn beperkingen vanuit het oogpunt van kosten en capaciteit", zegt Mann. “Nieuwe geheugen- en opslagtechnologieën zoals Optane persistent geheugen en Optane SSD zijn [in opkomst] als alternatief voor DRAM vanwege hun kosten-, capaciteits- en prestatievoordeel. Optane SSD's zijn bijzonder krachtige cache-HDD- en NAND SSD-gegevens om continu AI-toepassingsgegevens te voeden."
Optane steekt ook gunstig af bij andere opkomende herinneringen die vandaag niet volledig volwassen of schaalbaar zijn, voegde ze eraan toe.

Een Intel Optane 200-serie module. Intel zegt dat Optane
al vandaag al wordt gebruikt om AI-applicaties aan te sturen. (Bron:Intel)
GPU-versnelling
Voor high-end edge-datacenter- en edge-servertoepassingen winnen AI-computerversnellers zoals GPU's aan kracht. Naast DRAM omvatten de geheugenkeuzes hier GDDR, een speciale DDR SDRAM die is ontworpen om GPU's met hoge bandbreedte te voeden, en HBM, een relatief nieuwe die-stacking-technologie die meerdere geheugenchips in hetzelfde pakket plaatst als de GPU zelf.
Beide zijn ontworpen voor de extreem hoge geheugenbandbreedte die vereist is voor AI-toepassingen.
Voor de meest veeleisende AI-modeltraining biedt HBM2E 3,6 Gbps en een geheugenbandbreedte van 460 GB/s (twee HBM2E-stacks bieden bijna 1 TB/s). Dat is een van de krachtigste beschikbare geheugens, in het kleinste gebied met het laagste stroomverbruik. HBM wordt gebruikt door GPU-leider Nvidia in al zijn datacenterproducten.
GDDR6 wordt ook gebruikt voor AI-inferentietoepassingen aan de edge, zegt Frank Ferro, senior director productmarketing voor IP Cores bij Rambus. Ferro zei dat GDDR6 kan voldoen aan de snelheids-, kosten- en stroomvereisten van edge AI-inferentiesystemen. Zo kan GDDR6 18 Gbps leveren en 72 GB/s. Het hebben van vier GDDR6 DRAM's biedt bijna 300 GB/s geheugenbandbreedte.
"GDDR6 wordt gebruikt voor AI-inferentie en ADAS-toepassingen, voegde Ferro toe.
Bij het vergelijken van GDDR6 met LPDDR, de benadering van Nvidia voor de meeste niet-datacenter edge-oplossingen van de Jetson AGX Xavier tot Jetson Nano, erkende Ferro dat LPDDR geschikt is voor goedkope AI-inferentie aan de edge of het eindpunt.
"De bandbreedte van LPDDR is beperkt tot 4,2 Gbps voor LPDDR4 en 6,4 Gbps voor LPDDR5", zei hij. "Naarmate de geheugenbandbreedte toeneemt, zullen we een toenemend aantal ontwerpen zien die GDDR6 gebruiken. Deze kloof in geheugenbandbreedte helpt de vraag naar GDDR6 te stimuleren.”

Frank Ferro van Rambus
Ondanks dat ze zijn ontworpen om naast GPU's te passen, kunnen andere verwerkingsversnellers profiteren van de bandbreedte van GDDR. Ferro benadrukte de Achronix Speedster7t, een FPGA-gebaseerde AI-versneller die wordt gebruikt voor inferentie en wat low-end training.
"Er is ruimte voor zowel HBM- als GDDR-geheugens in edge AI-toepassingen", zegt Ferro. HBM “blijft gebruikt worden in edge-toepassingen. Ondanks alle voordelen van HBM, zijn de kosten nog steeds hoog vanwege de 3D-technologie en 2.5D-productie. Daarom is GDDR6 een goede afweging tussen kosten en prestaties, vooral voor AI-inferentie in het netwerk."
HBM wordt gebruikt in high-performance datacenter AI ASIC's zoals de Graphcore IPU. Hoewel het geweldige prestaties biedt, kan het prijskaartje voor sommige toepassingen hoog zijn.
Qualcomm is een van degenen die deze aanpak gebruiken. De Cloud AI 100 is gericht op AI-inferentieversnelling in edge-datacenters, 5G "edge boxes", ADAS/autonoom rijden en 5G-infrastructuur.
"Het was belangrijk voor ons om standaard DRAM te gebruiken in plaats van iets als HBM, omdat we de stuklijst laag willen houden", zegt Keith Kressin, algemeen directeur van de Computing- en Edge Cloud-eenheid van Qualcomm. “We wilden gebruik maken van standaard componenten die je bij meerdere leveranciers kunt kopen. We hebben klanten die alles on-chip willen doen, en we hebben klanten die cross-card willen. Maar ze wilden allemaal de kosten redelijk houden en niet voor HBM of zelfs een exotischer geheugen gaan.
"Tijdens de training," vervolgde hij, "heb je echt grote modellen die over [meerdere chips] zouden gaan, maar voor de conclusie [de Cloud AI 100-markt] zijn veel van de modellen meer gelokaliseerd."
De verre rand
Buiten het datacenter richten edge-AI-systemen zich over het algemeen op inferentie, met een paar opmerkelijke uitzonderingen zoals federated learning en andere incrementele trainingstechnieken.
Sommige AI-versnellers voor energiegevoelige toepassingen gebruiken geheugen voor AI-verwerking. Inferentie, dat is gebaseerd op multidimensionale matrixvermenigvuldiging, leent zich voor analoge rekentechnieken met een reeks geheugencellen die worden gebruikt om berekeningen uit te voeren. Met behulp van deze techniek zijn de apparaten van Syntiant ontworpen voor spraakbesturing van consumentenelektronica, en de apparaten van Gyrfalcon zijn ontworpen voor een smartphone waar ze inferentie voor camera-effecten kunnen afhandelen.
In een ander voorbeeld gebruikt Mythic, specialist in intelligente verwerkingseenheden, analoge werking van flash-geheugencellen om een 8-bits integerwaarde (één gewichtsparameter) op te slaan op een enkele flashtransistor, waardoor deze veel dichter is dan andere compute-in-memory-technologieën. De geprogrammeerde flitstransistor functioneert als een variabele weerstand; ingangen worden geleverd als spanningen en uitgangen worden verzameld als stromen. In combinatie met ADC's en DAC's is het resultaat een efficiënte matrixvermenigvuldigingsengine.
Het IP-adres van Mythic zit in de compensatie- en kalibratietechnieken die ruis opheffen en betrouwbare 8-bits berekeningen mogelijk maken.
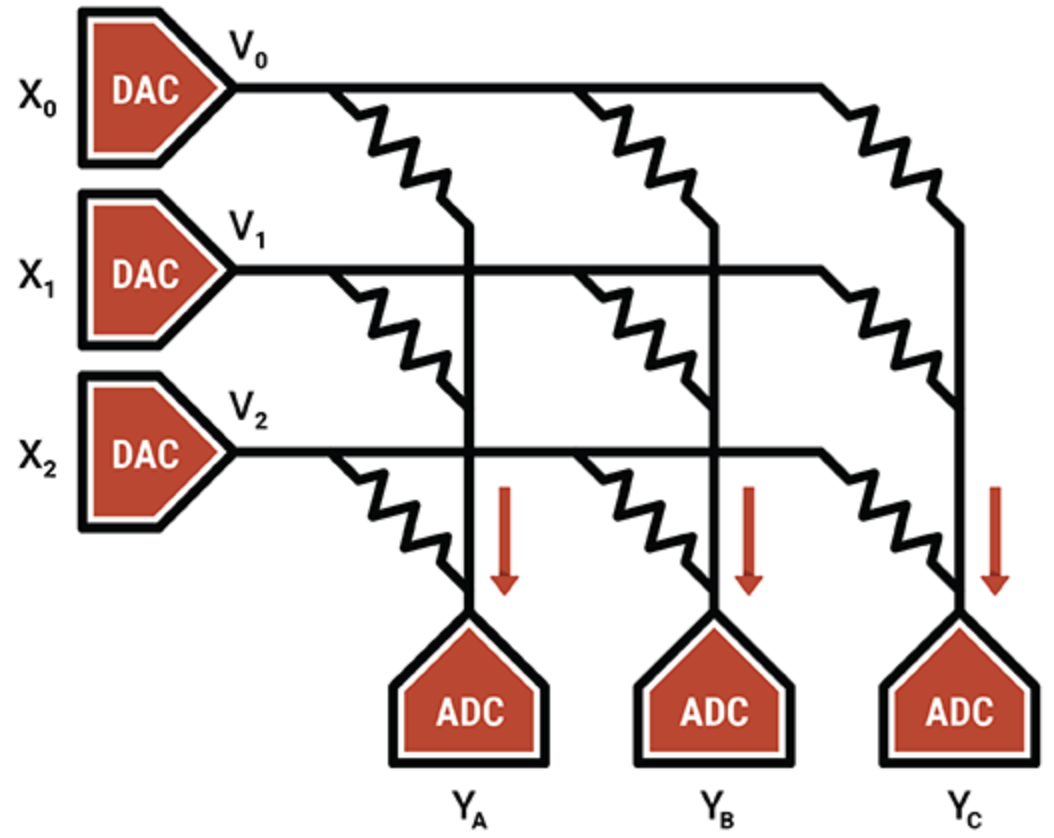
Mythic gebruikt een reeks Flash-geheugentransistors om dichte multi-accumulerende engines te maken (Bron:Mythic)
Afgezien van compute-in-memory-apparaten, zijn ASIC's populair voor specifieke edge-niches, met name voor systemen met een laag en ultralaag vermogen. Geheugensystemen voor ASIC's gebruiken een combinatie van verschillende geheugentypen. Gedistribueerde lokale SRAM is de snelste, meest energiezuinige, maar niet erg gebiedsefficiënt. Het hebben van een enkele bulk SRAM op de chip is meer ruimtebesparend, maar introduceert prestatieknelpunten. Off-chip DRAM is goedkoper, maar verbruikt veel meer stroom.
Geoff Tate, CEO van Flex Logix, zei dat het vinden van de juiste balans tussen gedistribueerd SRAM, bulk SRAM en off-chip DRAM voor zijn InferX X1 een reeks prestatiesimulaties vereiste. Het doel was om de inferentiedoorvoer per dollar te maximaliseren - een functie van de grootte van de matrijs, de pakketkosten en het aantal gebruikte DRAM's.
“Het optimale punt was een enkele x32 LPDDR4 DRAM; 4K MAC's (7,5 TOPS bij 933 MHz); en ongeveer 10 MB SRAM, "zei hij. “SRAM is snel, maar het is duur in vergelijking met DRAM. Met behulp van de 16-nm-procestechnologie van TSMC kost 1 MB SRAM ongeveer 1,1 mm 2 . “Onze InferX X1 is slechts 54 mm 2 en vanwege onze architectuur overlappen DRAM-toegangen grotendeels met berekeningen, dus er is geen prestatie inbegrepen. Voor grote modellen is het hebben van één DRAM de juiste afweging, in ieder geval met onze architectuur,” zei Tate.
De Flex Logix-chip zal worden gebruikt in edge AI-inferentietoepassingen die real-time operatie vereisen, inclusief het analyseren van streaming video met lage latentie. Dit omvat ADAS-systemen, analyse van beveiligingsbeelden, medische beeldvorming en toepassingen voor kwaliteitsborging/inspectie.
Wat voor soort DRAM komt er naast de InferX X1 in deze toepassingen?
"We denken dat LPDDR het populairst zal zijn:een enkele DRAM geeft meer dan 10 GB/sec aan bandbreedte... maar heeft toch genoeg bits om de gewichten/tussentijdse activeringen op te slaan", aldus Tate. "Elke andere DRAM zou meer chips en interfaces vereisen en er zouden meer bits moeten worden gekocht die niet worden gebruikt."
Is er hier ruimte voor opkomende geheugentechnologieën?
"De waferkosten stijgen dramatisch bij het gebruik van opkomend geheugen, terwijl SRAM 'gratis' is, behalve voor het siliciumgebied," voegde hij eraan toe. "Als de economie verandert, kan het omslagpunt ook veranderen, maar het zal verder op de weg liggen."
Opkomende herinneringen
Ondanks de schaalvoordelen bieden andere geheugentypes toekomstige mogelijkheden voor AI-toepassingen.
MRAM (magneto-resistive RAM) slaat elk gegevensbit op via de oriëntatie van magneten die worden bestuurd door een aangelegde elektrische spanning. Als de spanning lager is dan nodig is om de bit te flippen, is er slechts een kans dat een bit zal flippen. Deze willekeur is ongewenst, dus wordt MRAM met hogere spanningen aangestuurd om dit te voorkomen. Toch kunnen sommige AI-toepassingen profiteren van deze inherente stochasiteit (die kan worden gezien als het proces van het willekeurig selecteren of genereren van gegevens).
Experimenten hebben de stochasiteitscapaciteiten van zijn MRAM toegepast op de apparaten van Gyrfalcon, een techniek waarbij de precisie van alle gewichten en activeringen wordt teruggebracht tot 1-bit. Dit wordt gebruikt om de computer- en stroomvereisten voor geavanceerde toepassingen drastisch te verminderen. Afwegingen met nauwkeurigheid zijn waarschijnlijk, afhankelijk van hoe het netwerk opnieuw wordt opgeleid. Over het algemeen kunnen neurale netwerken betrouwbaar worden gemaakt ondanks de verminderde precisie.
"Gebinariseerde neurale netwerken zijn uniek omdat ze betrouwbaar kunnen functioneren, zelfs als de zekerheid dat een getal -1 of +1 is, wordt verminderd", zegt Andy Walker, product vice president bij Spin Memory. "We hebben ontdekt dat dergelijke BNN's nog steeds met een hoge mate van nauwkeurigheid kunnen functioneren, omdat deze zekerheid wordt verminderd [door] de invoering van de zogenaamde 'bitfoutfrequentie' van de geheugenbits die onjuist worden geschreven."

Andy Walker van Spin Memory
MRAM kan natuurlijk op een gecontroleerde manier bitfoutpercentages introduceren bij lage spanningsniveaus, waarbij de nauwkeurigheid behouden blijft en de stroomvereisten nog verder worden verlaagd. De sleutel is het bepalen van de optimale nauwkeurigheid bij de laagste spanning en de kortste tijd. Dat vertaalt zich in de hoogste energie-efficiëntie, zei Walker.
Hoewel deze techniek ook van toepassing is op neurale netwerken met een hogere precisie, is hij vooral geschikt voor BNN's omdat de MRAM-cel twee toestanden heeft, die overeenkomen met de binaire toestanden in een BNN.
Volgens Walker is het gebruik van MRAM aan de rand een andere mogelijke toepassing.
"Voor edge AI heeft MRAM de mogelijkheid om op lagere spanningen te werken in toepassingen waar hoge prestatienauwkeurigheid geen vereiste is, maar verbeteringen in energie-efficiëntie en geheugenuithoudingsvermogen zijn erg belangrijk", zei hij. "Bovendien zorgt de inherente niet-vluchtigheid van MRAM voor gegevensbehoud zonder stroom.
Eén toepassing is als een zogenaamd verenigd geheugen "waar dit opkomende geheugen kan fungeren als zowel een ingebouwde flitser als SRAM-vervanging, waardoor ruimte op de matrijs wordt bespaard en de statische vermogensdissipatie die inherent is aan SRAM wordt vermeden."
Hoewel Spin Memory's MRAM op het punt staat commercieel te worden toegepast, zou een specifieke implementatie van de BNN het beste werken op een variant van de basis-MRAM-cel. Daarom blijft het in de onderzoeksfase.
Neuromorfe ReRAM
Een ander opkomend geheugen voor edge AI-toepassingen is ReRAM. Recent onderzoek door Politecnico Milan met behulp van Weebit Nano's siliciumoxide (SiOx) ReRAM-technologie toonde veelbelovend voor neuromorfisch computergebruik. ReRAM voegde een dimensie van plasticiteit toe aan neurale netwerkhardware; dat wil zeggen, het zou kunnen evolueren naarmate de omstandigheden veranderen - een nuttige kwaliteit in neuromorfisch computergebruik.
Huidige neurale netwerken kunnen niet leren zonder taken te vergeten waarop ze zijn getraind, terwijl de hersenen dit vrij gemakkelijk kunnen doen. In AI-termen is dit "unsupervised learning", waarbij het algoritme inferenties uitvoert op datasets zonder labels, op zoek naar zijn eigen patronen in data. Het uiteindelijke resultaat kunnen ReRAM-enabled edge AI-systemen zijn die nieuwe taken in-situ kunnen leren en zich kunnen aanpassen aan de omgeving om hen heen.
Over het algemeen introduceren geheugenmakers technologieën die snelheid en bandbreedte bieden die nodig zijn voor AI-toepassingen. Er zijn verschillende geheugens beschikbaar, of ze nu op dezelfde chip zitten als de AI-computing, in hetzelfde pakket of op afzonderlijke modules, voor veel edge-AI-toepassingen.
Hoewel de exacte aard van geheugensystemen voor edge AI afhankelijk is van de toepassing, blijken GDDR, HBM en Optane populair te zijn voor datacenters, terwijl LPDDR concurreert met on-chip SRAM voor eindpunttoepassingen.
Opkomende herinneringen lenen hun nieuwe eigenschappen aan onderzoek dat is ontworpen om neurale netwerken verder te ontwikkelen dan de mogelijkheden van de huidige hardware om toekomstige, energie-efficiënte, op de hersenen geïnspireerde systemen mogelijk te maken.
>> Dit artikel is oorspronkelijk gepubliceerd op onze zustersite, EE Times.
Ingebed
- Alleen-lezen geheugen (ROM)
- Microprocessors
- Big data, niet zo gemakkelijk:nieuwe uitdagingen in fabrieksonderhoudstechnologie overwinnen
- ST sampling ingebed Phase-Change Memory voor automotive microcontrollers
- Siemens neemt Edge-technologie over van Pixeom
- Edge-toepassingstechnologie biedt voordelen voor alle industrieën
- 5G en Edge zorgen voor nieuwe uitdagingen op het gebied van cyberbeveiliging voor 2021
- 4 tips en uitdagingen voor beter IIoT-activabeheer
- 3 uitstekende voorbeelden van geavanceerde geavanceerde productietechnologie
- Lineaire bewegingstechnologie
- Hoe geconnecteerde technologie kan helpen bij het oplossen van de supply chain-uitdagingen