


Hoe uitgebreide signaalverwerkingsketens ervoor zorgen dat spraakassistenten 'gewoon werken'
Slimme luidsprekers en spraakgestuurde apparaten worden steeds populairder, waarbij spraakassistenten zoals Alexa van Amazon en de assistent van Google onze verzoeken steeds beter begrijpen.
Een van de belangrijkste voordelen van dit soort interface is dat het 'gewoon werkt' - er is geen gebruikersinterface om te leren, en we kunnen steeds vaker in een natuurlijke taal met een gadget praten alsof het een persoon is, en een nuttig antwoord krijgen. Maar om deze mogelijkheid te bereiken, is er een enorme hoeveelheid geavanceerde verwerking gaande.
In dit artikel bekijken we de architectuur van spraakgestuurde oplossingen en bespreken we wat er onder de motorkap gebeurt en welke hardware en software daarvoor nodig zijn.
Signaalstroom en architectuur
Hoewel er veel soorten spraakgestuurde apparaten zijn, zijn de basisprincipes en signaalstroom vergelijkbaar. Laten we eens kijken naar een slimme luidspreker, zoals Amazon's Echo, en kijken naar de belangrijkste subsystemen en modules voor signaalverwerking.
Afbeelding 1 toont de algehele signaalketen in een slimme luidspreker.
klik voor grotere afbeelding
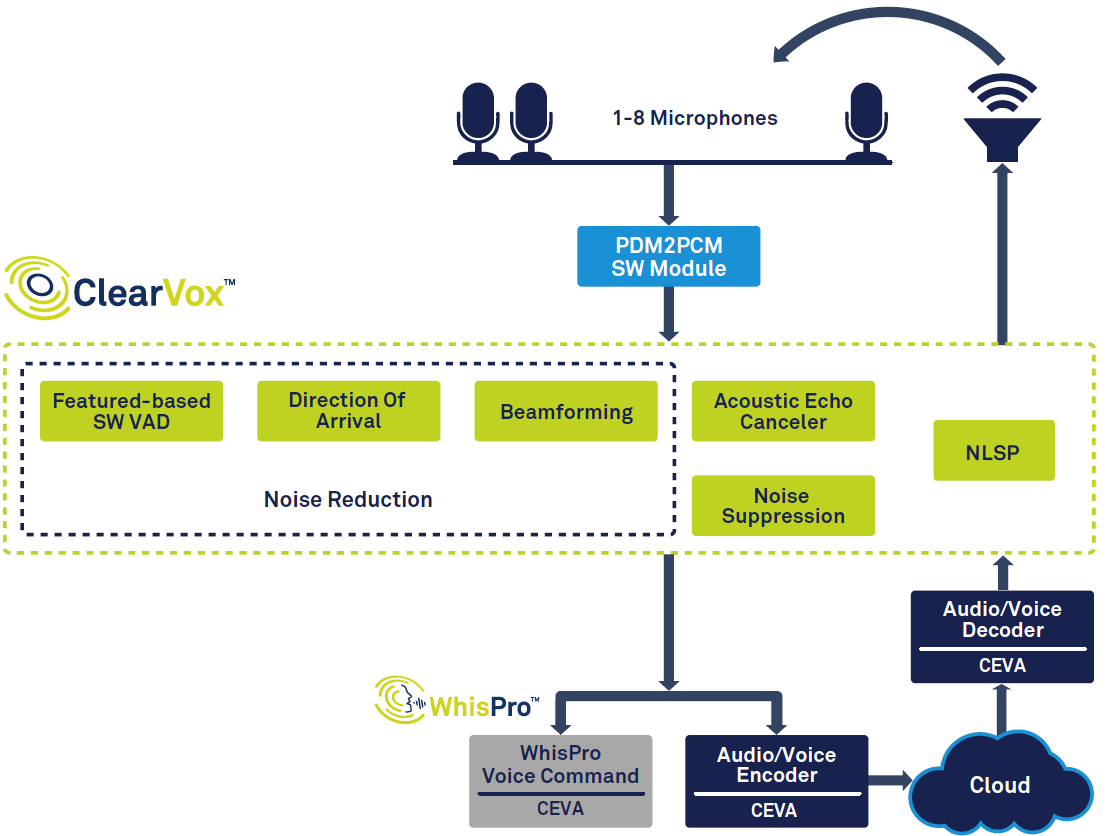
Figuur 1:Signaalketen voor stemassistent, gebaseerd op CEVA's ClearVox en WhisPro. (Bron:CEVA)
Aan de linkerkant van het diagram kunt u zien dat, zodra een stem is gedetecteerd met behulp van spraakactiviteitdetectie (VAD), deze wordt gedigitaliseerd en door meerdere signaalverwerkingsstadia gaat om de helderheid van de stem van de gewenste hoofdspreker te verbeteren richting van aankomst. De gedigitaliseerde, verwerkte spraakgegevens worden vervolgens doorgegeven aan back-end spraakverwerking, die deels aan de rand (op het apparaat) en deels in de cloud kan plaatsvinden. Ten slotte wordt er, indien nodig, een reactie gemaakt en uitgevoerd door de spreker, waarvoor decodering en conversie van digitaal naar analoog vereist is.
Voor andere toepassingen kunnen er enkele verschillen en variërende prioriteiten zijn - een spraakinterface in het voertuig zou bijvoorbeeld moeten worden geoptimaliseerd om typisch achtergrondgeluid in auto's aan te kunnen. Er is ook een algemene trend naar lager stroomverbruik en lagere kosten, gedreven door de vraag naar kleinere apparaten zoals in-ear 'hearables' en goedkope huishoudelijke apparaten.
Front-end signaalverwerking
Zodra een stem is gedetecteerd en gedigitaliseerd, zijn meerdere signaalverwerkingstaken vereist. Naast externe ruis, moeten we ook rekening houden met geluiden die worden gegenereerd door het luisterapparaat, bijvoorbeeld een slimme luidspreker die muziek uitvoert of een gesprek met iemand aan de andere kant van de lijn. Om deze geluiden te onderdrukken, maakt het apparaat gebruik van akoestische echo-onderdrukking (AEC), zodat de gebruiker kan binnenvallen en een slimme luidspreker kan onderbreken, zelfs als deze al muziek afspeelt of praat. Zodra deze echo's zijn verwijderd, worden ruisonderdrukkingsalgoritmen gebruikt om externe ruis op te ruimen.
Hoewel er veel verschillende toepassingen zijn, kunnen we ze veralgemenen in twee groepen voor spraakgestuurde apparaten:near-field en far-field voice pick-up. Near-field-apparaten, zoals headsets, oordopjes, hearables en wearables, worden in de buurt van de mond van de gebruiker gehouden of gedragen, terwijl far-field-apparaten zoals slimme luidsprekers en tv's zijn ontworpen om te luisteren naar de stem van een gebruiker vanuit een andere kamer.
Near-field-apparaten gebruiken meestal één of twee microfoons, maar far-field-apparaten gebruiken vaak ergens tussen de drie en acht. De reden hiervoor is dat het far-field-apparaat met meer uitdagingen te maken heeft dan het near-field-apparaat:naarmate de gebruiker verder weg beweegt, wordt zijn stem die de microfoons bereikt steeds stiller, terwijl het achtergrondgeluid op hetzelfde niveau blijft. Tegelijkertijd moet het apparaat ook het directe spraaksignaal scheiden van reflecties van muren en andere oppervlakken, oftewel galm.
Om deze problemen aan te pakken, gebruiken verre-veldapparaten een techniek die beamforming wordt genoemd. Deze gebruikt meerdere microfoons en berekent de richting van de geluidsbron op basis van de tijdsverschillen tussen de geluidssignalen die bij elke microfoon aankomen. Hierdoor kan het apparaat reflecties en andere geluiden negeren en gewoon naar de gebruiker luisteren, zijn bewegingen volgen en inzoomen op de juiste stem als er meerdere mensen praten.
Voor slimme luidsprekers is een andere belangrijke taak het herkennen van het 'trigger'-woord, zoals 'Alexa'. Omdat de spreker altijd luistert, roept deze triggerherkenning privacyproblemen op - als de audio van de gebruiker altijd naar de cloud wordt geüpload, zelfs als ze het triggerwoord niet zeggen, voelen ze zich dan op hun gemak als Amazon of Google al hun gesprekken hoort? In plaats daarvan kan het de voorkeur hebben om de triggerherkenning af te handelen, evenals veel populaire commando's zoals "volume omhoog" lokaal op de slimme luidspreker zelf, waarbij audio pas naar de cloud wordt verzonden nadat de gebruiker een complexere opdracht heeft gestart.
Ten slotte moet het schone stemvoorbeeld worden gecodeerd voordat het uiteindelijk naar de cloud-back-end wordt gestuurd voor verdere verwerking.
Gespecialiseerde oplossingen
Uit de bovenstaande beschrijving blijkt duidelijk dat de front-end spraakverwerking veel taken aan moet kunnen. Het moet dit snel en nauwkeurig doen, en voor apparaten die op batterijen werken, moet het stroomverbruik tot een minimum worden beperkt - zelfs wanneer het apparaat altijd naar een triggerwoord luistert.
Om aan deze eisen te voldoen, is het onwaarschijnlijk dat digitale-signaalprocessors (DSP's) of microprocessors voor algemeen gebruik aan hun taak voldoen - in termen van kosten, verwerkingsprestaties, grootte en stroomverbruik. In plaats daarvan is een toepassingsspecifieke DSP waarschijnlijk een betere oplossing, met speciale audioverwerkingsfuncties en geoptimaliseerde software. Het kiezen van een hardware-/softwareoplossing die al is geoptimaliseerd voor de spraakinvoertaken, zal ook de ontwikkelingskosten verlagen en de time-to-market aanzienlijk verkorten, evenals de totale kosten verlagen.
ClearVox van CEVA is bijvoorbeeld een softwaresuite van algoritmen voor het verwerken van spraakinvoer, die verschillende akoestische scenario's en microfoonconfiguraties aankunnen, waaronder de stemrichting van de spreker bij aankomst, multi-mic beamforming, ruisonderdrukking en akoestische echo-onderdrukking. ClearVox is geoptimaliseerd om efficiënt te werken op CEVA-geluids-DSP's, om een kosteneffectieve, energiezuinige oplossing te bieden.
Naast spraakverwerking heeft het edge-apparaat de mogelijkheid nodig om triggerwoorddetectie te verwerken. Een gespecialiseerde oplossing, zoals WhisPro van CEVA, is een uitstekende manier om de benodigde nauwkeurigheid en een laag stroomverbruik te bereiken (zie afbeelding 2). WhisPro is een neuraal netwerkgebaseerd softwarepakket voor spraakherkenning, exclusief beschikbaar voor CEVA's DSP's, waarmee OEM's spraakactivering kunnen toevoegen aan hun spraakgestuurde producten. Het kan het vereiste altijd-aan luisteren aan, terwijl een hoofdprocessor in slaap blijft totdat het nodig is, waardoor het totale stroomverbruik van het systeem aanzienlijk wordt verminderd.
klik voor grotere afbeelding
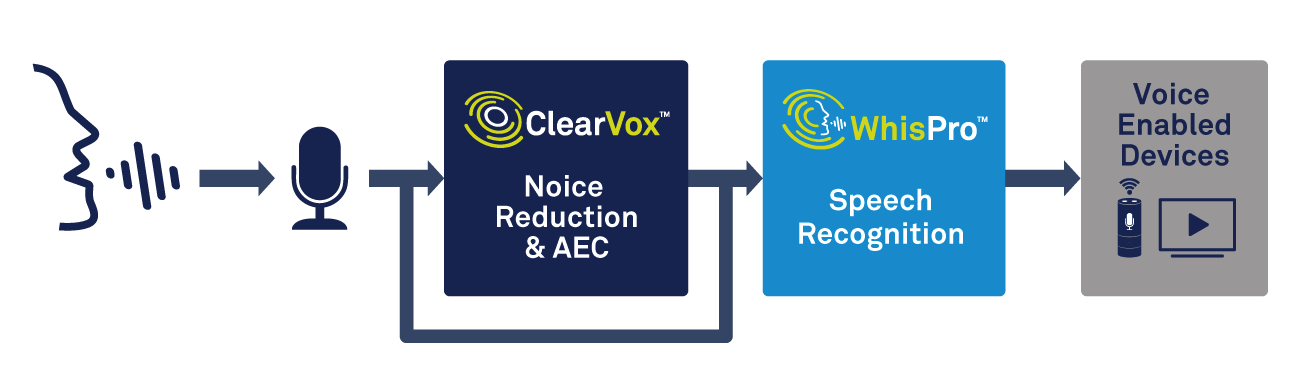
Figuur 2:stemverwerking en spraakherkenning gebruiken voor stemactivering. (Bron:CEVA)
WhisPro kan een herkenningsgraad van meer dan 95% bereiken en kan meerdere trigger-frases ondersteunen, evenals aangepaste trigger-woorden. Zoals iedereen die een slimme luidspreker heeft gebruikt kan getuigen, kan het soms een frustrerende ervaring zijn om deze betrouwbaar op het wekwoord te laten reageren, zelfs in een lawaaierige omgeving. Als u deze functie goed gebruikt, kan dit een enorm verschil maken in hoe consumenten de kwaliteit van een spraakgestuurd product ervaren.
Spraakherkenning:lokaal of cloud
Als de stem eenmaal is gedigitaliseerd en verwerkt, hebben we een soort automatische spraakherkenning (ASR) nodig. Er is een breed scala aan ASR-technologieën, variërend van eenvoudige trefwoorddetectie waarbij een gebruiker specifieke trefwoorden moet zeggen, tot geavanceerde natuurlijke taalverwerking (NLP), waarbij een gebruiker normaal kan praten alsof hij een andere persoon aanspreekt.
Zoekwoorddetectie heeft veel toepassingen, zelfs als de woordenschat extreem beperkt is. Een eenvoudig smart home-apparaat, zoals een lichtschakelaar of thermostaat, reageert bijvoorbeeld misschien maar op een paar commando's, zoals 'aan', 'uit', 'helderder', 'dimmer' enzovoort. Dit ASR-niveau kan eenvoudig lokaal, aan de rand, zonder internetverbinding worden afgehandeld, waardoor de kosten laag blijven, een snelle reactie wordt gegarandeerd en zorgen over beveiliging en privacy worden vermeden.
Een ander voorbeeld is dat aan veel Android-smartphones kan worden verteld dat ze een foto moeten maken door 'cheese' of 'smile' te zeggen, terwijl het verzenden van de opdracht naar de cloud simpelweg te lang zou duren. En dat in de veronderstelling dat er een internetverbinding beschikbaar is, wat niet altijd het geval zal zijn voor een apparaat zoals een smartwatch of hearable.
Aan de andere kant vereisen veel toepassingen NLP. Als u uw Echo-spreker wilt vragen naar het weer of een hotel voor vanavond wilt vinden, kunt u uw vraag op veel verschillende manieren formuleren. Het apparaat moet de mogelijke nuances en spreektaal in de opdracht kunnen begrijpen en betrouwbaar kunnen uitwerken wat er wordt gevraagd. Simpel gezegd, het moet in staat zijn om spraak om te zetten in betekenis, in plaats van alleen spraak in tekst.
Om ons hotelonderzoek als voorbeeld te nemen, is er een enorm scala aan mogelijke factoren waar u naar zou willen vragen:prijs, locatie, beoordelingen en vele andere. Het NLP-systeem moet al deze complexiteit interpreteren, evenals de vele verschillende manieren waarop een vraag kan worden geformuleerd, en een gebrek aan duidelijkheid van het verzoek - zeggen 'vind me een goede prijs, centraal hotel' zal verschillende dingen voor verschillende mensen betekenen mensen. Om nauwkeurige resultaten te verkrijgen, moet het apparaat ook rekening houden met de context van de vraag en herkennen wanneer de gebruiker aansluitende vervolgvragen stelt of meerdere stukjes informatie vraagt binnen één zoekopdracht.
Dit kan een enorme hoeveelheid verwerking vergen, meestal met behulp van kunstmatige intelligentie (AI) en neurale netwerken, wat meestal niet praktisch is voor verwerking alleen aan de rand. Een goedkoop apparaat met een ingebouwde processor heeft niet genoeg kracht om de vereiste taken uit te voeren. In dit geval is de juiste optie om de gedigitaliseerde spraak voor verwerking in de cloud te verzenden. Daar kan het worden geïnterpreteerd en een passend antwoord worden teruggestuurd naar het spraakgestuurde apparaat.
U kunt zien dat er compromissen zijn tussen edge-verwerking op het apparaat en verwerking op afstand in de cloud. Alles lokaal afhandelen kan sneller en is niet afhankelijk van een internetverbinding, maar zal moeite hebben met een breder scala aan vragen en het ophalen van informatie. Dit betekent dat het voor een apparaat voor algemeen gebruik, zoals een slimme luidspreker in huis, nodig is om op zijn minst enige verwerking naar de cloud te pushen.
Om de nadelen van cloudverwerking aan te pakken, zijn er ontwikkelingen in de mogelijkheden van lokale processors, en in de nabije toekomst kunnen we grote verbeteringen verwachten in NLP en AI in edge-apparaten. Door nieuwe technieken is er minder geheugen nodig en worden processors steeds sneller en minder energieverslindend.
CEVA's NeuPro-familie van low-power AI-processors biedt bijvoorbeeld geavanceerde mogelijkheden voor de edge. Voortbouwend op CEVA's ervaring met neurale netwerken voor computervisie, levert deze familie een flexibele, schaalbare oplossing voor spraakverwerking op het apparaat.
Conclusies
Spraakgestuurde interfaces worden snel een belangrijk onderdeel van ons dagelijks leven en zullen in de nabije toekomst aan steeds meer producten worden toegevoegd. Verbeteringen worden aangedreven door betere signaalverwerking en spraakherkenningsmogelijkheden, evenals krachtigere computerbronnen, zowel lokaal als in de cloud.
Om aan de eisen van OEM's te voldoen, moeten de componenten die worden gebruikt voor audioverwerking en spraakherkenning een aantal zware uitdagingen aangaan op het gebied van prestaties, kosten en vermogen. Voor veel ontwerpers zijn oplossingen die specifiek zijn geoptimaliseerd voor de taken die voorhanden zijn misschien wel de beste aanpak:voldoen aan de eisen van de eindklant en de time-to-market verkorten.
Op welke technologie ze ook gebaseerd zijn, spraakinterfaces zullen nauwkeuriger en gemakkelijker te spreken zijn in alledaagse taal, terwijl hun dalende kosten ze aantrekkelijker maken voor fabrikanten. Het wordt een interessante reis om te zien waarvoor ze de volgende keer worden gebruikt.
Ingebed
- Hoe zwenkwielen werken
- Verbeterde technologieën zullen de acceptatie van spraakassistenten versnellen
- Hoe maak je glasvezel
- Hoe u nu het beste uit uw toeleveringsketen haalt
- Hoe werken SCADA-systemen?
- Hoe maak je een kompas met Arduino en Processing IDE?
- Hoe maak je een prototype?
- Hoe werken luchtdrogers?
- Hoe de elektronica van morgen te maken met inkjet-geprint grafeen
- Hoe elektrische remmen werken
- Hoe u een uitgebreid veiligheidsprogramma kunt laten werken