


Inzicht in trainingsformules en backpropagation voor meerlaagse perceptrons
Dit artikel presenteert de vergelijkingen die we gebruiken bij het uitvoeren van berekeningen voor gewichtsupdates, en we zullen ook het concept van backpropagation bespreken.
Welkom bij AAC's serie over machine learning.
Bekijk de serie tot nu toe hier:
- Hoe classificatie uitvoeren met behulp van een neuraal netwerk:wat is de Perceptron?
- Een eenvoudig Perceptron neuraal netwerkvoorbeeld gebruiken om gegevens te classificeren
- Een basis Perceptron neuraal netwerk trainen
- Eenvoudige neurale netwerktraining begrijpen
- Een inleiding tot trainingstheorie voor neurale netwerken
- De leersnelheid in neurale netwerken begrijpen
- Geavanceerde machine learning met de meerlaagse Perceptron
- De Sigmoid-activeringsfunctie:activering in meerlaagse Perceptron neurale netwerken
- Een meerlagig Perceptron neuraal netwerk trainen
- Trainingsformules en backpropagation voor meerlaagse perceptrons begrijpen
- Neurale netwerkarchitectuur voor een Python-implementatie
- Hoe maak je een meerlaags Perceptron neuraal netwerk in Python
- Signaalverwerking met behulp van neurale netwerken:validatie in neuraal netwerkontwerp
- Trainingsdatasets voor neurale netwerken:een neuraal netwerk met Python trainen en valideren
We hebben het punt bereikt waarop we een fundamenteel onderwerp binnen de neurale-netwerktheorie zorgvuldig moeten overwegen:de computationele procedure waarmee we de gewichten van een meerlagige Perceptron (MLP) kunnen verfijnen, zodat deze invoermonsters nauwkeurig kan classificeren. Dit zal ons leiden naar het concept van 'backpropagation', wat een essentieel aspect is van het ontwerp van neurale netwerken.
Gewichten bijwerken
De informatie rondom opleiding voor MLP's is ingewikkeld. Om het nog erger te maken, gebruiken online bronnen verschillende terminologie en symbolen en lijken ze zelfs met verschillende resultaten te komen. Ik weet echter niet zeker of de resultaten echt verschillend zijn of dat ze dezelfde informatie op verschillende manieren presenteren.
De vergelijkingen in dit artikel zijn gebaseerd op de afleidingen en verklaringen van Dr. Dustin Stansbury in deze blogpost. Zijn behandeling is de beste die ik heb gevonden, en het is een geweldige plek om te beginnen als je je wilt verdiepen in de wiskundige en conceptuele details van gradiëntafdaling en backpropagation.
Het volgende diagram geeft de architectuur weer die we in software zullen implementeren, en de onderstaande vergelijkingen komen overeen met deze architectuur, die in het volgende artikel uitgebreider wordt besproken.
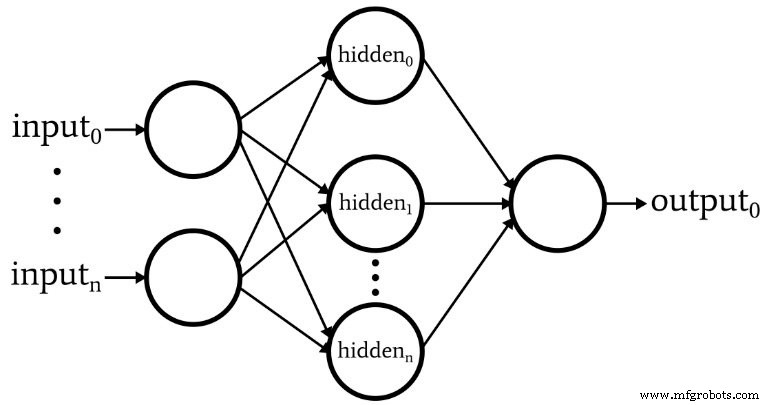
Terminologie
Dit onderwerp wordt al snel onhandelbaar als we geen duidelijke terminologie hanteren. Ik gebruik de volgende termen:
- Preactivering (afgekort \(S_{preA}\) ):Dit verwijst naar het signaal (eigenlijk slechts een getal in de context van één trainingsiteratie) dat dient als invoer voor de activeringsfunctie van een knooppunt. Het wordt berekend door het uitvoeren van een puntproduct van een array met gewichten en een array met de waarden die afkomstig zijn van knooppunten in de voorgaande laag. Het puntproduct is gelijk aan het uitvoeren van een elementgewijze vermenigvuldiging van de twee arrays en het optellen van de elementen in de array die het resultaat zijn van die vermenigvuldiging.
- Na activering (afgekort \(S_{postA}\) ):Dit verwijst naar het signaal (nogmaals, alleen een getal in de context van een individuele iteratie) dat een knooppunt verlaat. Het wordt geproduceerd door de activeringsfunctie toe te passen op het preactiveringssignaal. Mijn voorkeursterm voor de activeringsfunctie, aangeduid met \(f_{A}()\) , is logistiek in plaats van sigmoid.
- In de Python-code ziet u gewichtsmatrices gelabeld met ItoH en HtoO . Ik gebruik deze identifiers omdat het dubbelzinnig is om zoiets als "verborgen laaggewichten" te zeggen - zouden dit de gewichten zijn die vóór worden toegepast de verborgen laag of na de verborgen laag? In mijn schema specificeert ItoH de gewichten die worden toegepast op waarden die worden overgedragen van de invoerknooppunten naar de verborgen knooppunten, en HtoO specificeert gewichten die worden toegepast op waarden die worden overgedragen van de verborgen knooppunten naar het uitvoerknooppunt.
- De juiste uitvoerwaarde voor een trainingsvoorbeeld wordt het doel genoemd en wordt aangegeven met T .
- Leerpercentage wordt afgekort als LR .
- Laatste fout is het verschil tussen het postactiveringssignaal van het uitgangsknooppunt (\(S_{postA,O}\) ) en het doel, berekend als \(FE =S_{postA,O} - T\) .
- Foutsignaal (\(S_{ERROR}\) ) is de laatste fout die terug naar de verborgen laag wordt gepropageerd via de activeringsfunctie van het uitvoerknooppunt.
- Verloop vertegenwoordigt de bijdrage van een bepaald gewicht aan het foutsignaal. We passen de gewichten aan door deze bijdrage af te trekken (indien nodig vermenigvuldigd met het leerpercentage).
Het volgende diagram situeert enkele van deze termen binnen de gevisualiseerde configuratie van het netwerk. Ik weet het - het ziet eruit als een veelkleurige puinhoop. Ik bied mijn excuses aan. Het is een informatie-dicht diagram, en hoewel het op het eerste gezicht misschien een beetje aanstootgevend is, denk ik dat als je het zorgvuldig bestudeert, je het erg nuttig zult vinden.
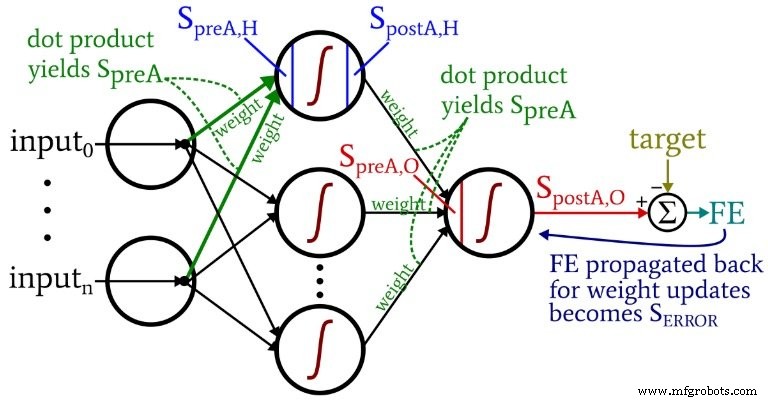
De vergelijkingen voor het bijwerken van het gewicht worden afgeleid door de partiële afgeleide van de foutfunctie te nemen (we gebruiken een gesommeerde kwadratische fout, zie deel 8 van de serie, die de activeringsfuncties behandelt) met betrekking tot het te wijzigen gewicht. Raadpleeg het bericht van Dr. Stansbury als je de wiskunde wilt zien; in dit artikel gaan we direct naar de resultaten. Voor de verborgen-naar-uitvoergewichten hebben we het volgende:
\[S_{ERROR} =FE \times {f_A}'(S_{preA,O})\]
\[gradient_{HtoO}=S_{ERROR}\times S_{postA,H}\]
\[weight_{HtoO} =weight_{HtoO}- (LR \times gradient_{HtoO})\]
We berekenen het foutsignaal l door de laatste fout . te vermenigvuldigen door de waarde die wordt geproduceerd wanneer we de afgeleide . toepassen van de activeringsfunctie naar het preactiveringssignaal geleverd aan het uitvoerknooppunt (let op het prime-symbool, dat de eerste afgeleide aangeeft, in \({f_A}'(S_{preA,O})\)). Het verloop wordt vervolgens berekend door het foutsignaal . te vermenigvuldigen door het postactiveringssignaal uit de verborgen laag. Ten slotte werken we het gewicht bij door deze gradiënt . af te trekken van de huidige gewichtswaarde, en we kunnen de gradiënt . vermenigvuldigen door het leertempo als we de stapgrootte willen wijzigen.
Voor de invoer-naar-verborgen gewichten hebben we dit:
\[gradient_{ItoH} =FE \times {f_A}'(S_{preA,O})\times weight_{HtoO} \times {f_A}'(S_{preA ,H}) \times input\]
\[\Rightarrow gradient_{ItoH} =S_{ERROR} \times weight_{HtoO} \times {f_A}'(S_{preA,H})\times input\]
\[weight_{ItoH} =weight_{ItoH} - (LR \times gradient_{ItoH})\]
Met de input-to-hidden-gewichten moet de fout worden teruggevoerd via een extra laag, en dat doen we door het foutsignaal te vermenigvuldigen door het verborgen-naar-uitvoergewicht verbonden met het verborgen knooppunt van belang. Dus als we een input-to-hidden-gewicht . bijwerken die naar de eerste verborgen knoop leidt, vermenigvuldigen we het foutsignaal door het gewicht dat het eerste verborgen knooppunt verbindt met het uitvoerknooppunt. Vervolgens voltooien we de berekening door vermenigvuldigingen uit te voeren analoog aan die van de gewichtsupdates van verborgen naar uitvoer:we passen de afgeleide toe van de activeringsfunctie naar het preactiveringssignaal . van het verborgen knooppunt , en de "invoer" -waarde kan worden gezien als het postactiveringssignaal van het invoerknooppunt.
Terugpropagatie
De bovenstaande uitleg heeft het concept van backpropagation al aangeroerd. Ik wil dit concept even kort versterken en er ook voor zorgen dat je expliciet bekend bent met deze term, die vaak voorkomt in discussies over neurale netwerken.
Backpropagation stelt ons in staat om het dilemma met verborgen knooppunten dat in deel 8 is besproken te overwinnen. We moeten de gewichten van input naar verborgen bijwerken op basis van het verschil tussen de gegenereerde output van het netwerk en de doeloutputwaarden geleverd door de trainingsgegevens, maar deze gewichten beïnvloeden de gegenereerde output indirect.
Backpropagation verwijst naar de techniek waarbij we een foutsignaal terugsturen naar een of meer verborgen lagen en dat foutsignaal schalen met behulp van zowel de gewichten die uit een verborgen knooppunt komen als de afgeleide van de activeringsfunctie van het verborgen knooppunt. De algemene procedure dient als een manier om een gewicht bij te werken op basis van de bijdrage van het gewicht aan de uitvoerfout, ook al wordt die bijdrage verdoezeld door de indirecte relatie tussen een invoer-naar-verborgen gewicht en de gegenereerde uitvoerwaarde.
Conclusie
We hebben veel belangrijk materiaal behandeld. Ik denk dat we in dit artikel echt waardevolle informatie over neurale netwerktraining hebben, en ik hoop dat u het daarmee eens bent. De serie wordt nog spannender, dus kom terug voor nieuwe afleveringen.
Industriële robot
- 1G bidirectionele transceivers voor serviceproviders en IoT-toepassingen
- CEVA:tweede generatie AI-processor voor diepe neurale netwerkworkloads
- Ontgrendel smart core network slicing voor het internet der dingen en MVNO's
- De vijf belangrijkste problemen en uitdagingen voor 5G
- Hoe u uw draadloze sensornetwerken kunt voeden en onderhouden
- Gids voor inzicht in Lean en Six Sigma voor productie
- BECKER'S vacuümpomptraining voor jou en mij
- Senet en SimplyCity werken samen voor LoRaWAN-uitbreiding en IoT
- De voordelen en uitdagingen voor hybride productie begrijpen
- Schokbestendig gereedschapsstaal begrijpen voor het maken van ponsen en matrijzen
- Hoe u de trainingstijd voor robotlassen kunt verkorten?