


De uitdagingen van multicore-programmeren en debuggen aankunnen
In dit artikel zullen we verschillende aspecten van multicore-verwerking bespreken, inclusief een blik op verschillende soorten multicore-processors en waarom deze apparaten tegenwoordig gebruikelijk en populair worden. We zullen dan kijken naar enkele van de uitdagingen die worden geïntroduceerd door meer dan één core op een chip te hebben, en hoe moderne multicore-bewuste debuggers kunnen helpen om deze complexe taken beter beheersbaar te maken.
Systeemprestaties
Er zijn veel manieren om de prestaties van een embedded computersysteem te verbeteren, variërend van slimme compileralgoritmen tot efficiënte hardwareoplossingen. Compileroptimalisaties zijn belangrijk om de meest efficiënte instructieplanning te krijgen van taalcode op hoog niveau die gemakkelijk te lezen en te begrijpen is. Daarnaast kunnen systemen profiteren van parallellisme dat beschikbaar is in het project om meer dan één ding tegelijk te verwerken. En natuurlijk kan het schalen van de klokfrequentie een effectieve manier zijn om meer prestaties uit uw computersysteem te halen.
Helaas zijn de dagen voorbij dat kloksnelheden geometrisch zouden toenemen. En code-optimalisatie kan u alleen zoveel verbetering opleveren, vooral nu, na vele generaties ontwikkeling van compilertechnologie. Dit laat ons toe om naar parallellisme te kijken als de beste kans om onze systeemprestaties in de loop van de tijd te blijven schalen.
Parallelisme

Het graven van een put is een taak die moeilijk te evenaren is. Anderen kunnen helpen door het vuil weg te scheppen, maar het daadwerkelijke graven in het gat is meestal een eenpersoonstaak. Als gevolg hiervan zal het toevoegen van meer mensen in het gat de klus niet sneller klaren. In feite kunnen de anderen gewoon in de weg zitten en het proces vertragen. Sommige taken zijn niet geschikt voor parallellisatie.
Andere taken kunnen gemakkelijk parallel worden uitgevoerd. Het graven van een sloot is een taak die geschikt is voor parallellisatie. Veel mensen kunnen naast elkaar werken.

Deze afbeelding toont een vorm van parallellisme genaamd MIMD, Multiple Instruction Multiple Data. Elke graafmachine is een aparte eenheid en kan verschillende taken uitvoeren. In dit geval kun je je voorstellen dat vier gravers de klus kunnen klaren in ongeveer 1/4 de de tijd van een enkele graver.
Met SIMD, Single Instruction Multiple Data, kan een enkele graver een schop zoals deze gebruiken.
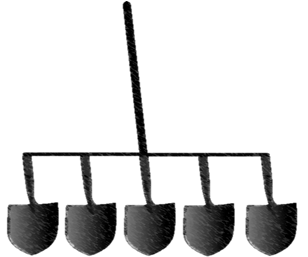
De SIMD-eenheid kan slechts één type berekening tegelijk uitvoeren, maar kan deze tegelijkertijd op verschillende gegevensbestanden uitvoeren. Dit soort instructies komt veel voor in vectorverwerkingseenheden in veel processors. Dit is handig als uw gegevens zeer regelmatig zijn en u dezelfde bewerkingen steeds opnieuw moet uitvoeren op een grote gegevensset, zoals bij beeldverwerking. Voor meer algemene computertaken is dit model echter niet flexibel en levert het geen prestatiewinst op.
Dit brengt ons bij de keuze om meerdere volledige CPU-subsystemen op één chip te plaatsen, waardoor multicore-processors ontstaan. Meerdere cores op één chip kunnen de prestaties schalen. Elke kern is een volledige CPU en kan onafhankelijk of samen met andere kernen werken.
Verschillende soorten multicore-verwerking
Er zijn verschillende combinaties van typen kernen die u op een processorchip kunt hebben en ook hoe het werk daartussen wordt verdeeld.
Homogene multicore-processors hebben twee of meer exemplaren van dezelfde processorcore. Elke kern werkt autonoom en kan communiceren en synchroniseren met andere kernen via een aantal mechanismen zoals gedeeld geheugen of mailboxsystemen. Elke processor heeft zijn eigen registers en functie-eenheden en kan zijn eigen lokale geheugen of cache hebben. Wat dit echter homogeen maakt, is het feit dat alle kernen waar we naar kijken van hetzelfde type zijn.
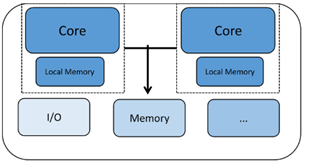
Een ander type meervoudige kernchip wordt heterogene multicore genoemd met twee of meer verschillende soorten CPU-kernen. Hier kunnen de kernen zeer verschillende kenmerken hebben, waardoor ze zeer geschikt zijn voor verschillende delen van de verwerkingsbehoeften van het systeem. Een voorbeeld kan een Bluetooth-communicatiechip zijn waarbij de ene kern is bedoeld voor het beheer van de Bluetooth-protocolstack, terwijl de andere kern externe communicatie, de verwerking van toepassingen, de menselijke interface enz. kan beheren. Dit soort meervoudige kernchip kan worden gebruikt voor toepassingen die beide nodig hebben realtime toegewijde prestaties op de ene kern en systeembeheermogelijkheden op de andere.
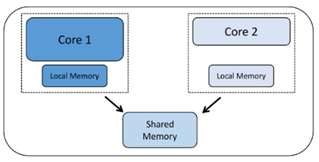
Nu zullen we kijken naar hoe de kernen worden gebruikt. Symmetrische multiprocessing (SMP) vindt plaats wanneer u meer dan één kern heeft en de kernen dezelfde projectcodebasis uitvoeren. Verschillende kernen kunnen tegelijkertijd verschillende delen van de code uitvoeren, maar de code is gebouwd als een enkel project en wordt naar de afzonderlijke kernen verzonden door een besturingsprogramma zoals een realtime besturingssysteem (RTOS). De cores die op deze manier werken, moeten noodzakelijkerwijs van hetzelfde type zijn, aangezien ze allemaal dezelfde projectcode gebruiken die voor één type processor is gecompileerd.
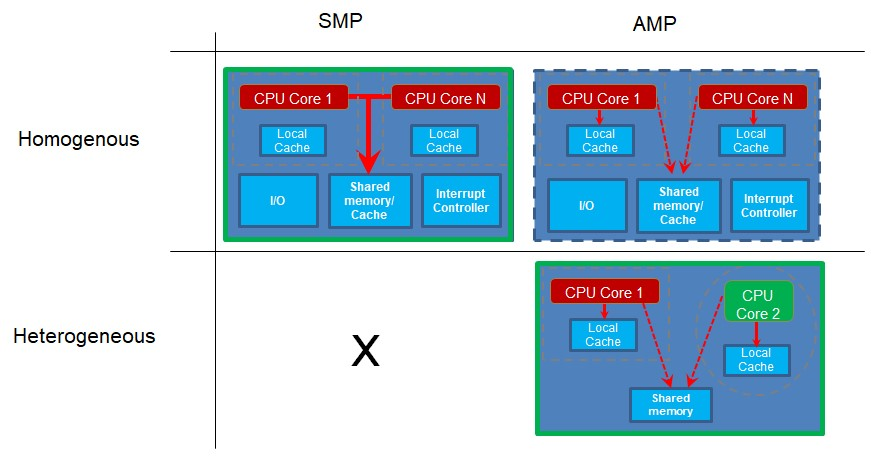
Asymmetrische multiprocessing (AMP) vindt plaats wanneer u meer dan één kern of processor hebt en elke processor zijn eigen projecttoepassing uitvoert. De afzonderlijke kernen kunnen van tijd tot tijd synchroniseren of communiceren, maar ze hebben elk hun eigen codebasis die ze uitvoeren. Omdat ze elk hun eigen project uitvoeren, kunnen deze kernen van verschillende typen zijn, of heterogene kernen. Dit is echter geen vereiste. Als twee of meer van hetzelfde type kernen verschillende projectcode uitvoeren, zijn het homogene kernen met AMP.
Merk op dat u voor SMP-werking meerdere homogene kernen moet hebben, omdat ze allemaal code uitvoeren vanuit dezelfde enkele projectcodebasis. Als u echter meerdere projecten heeft met verschillende codebases om de verschillende cores uit te voeren, kunnen dit verschillende cores zijn, zoals in een heterogeen systeem. Als de kernen echter hetzelfde zijn, werkt dat ook.
Redenen voor het gebruik van Multicore
In de afgelopen jaren lijkt de wet van Moore, bedacht in het midden van de jaren zestig, eindelijk op te raken, of op zijn minst te vertragen. De kloksnelheden van processors verdubbelen niet langer elke 2-3 jaar en in feite hebben de hoogste snelheids-CPU's al vele jaren een plafond bereikt in het lage eencijferige GHz-bereik.
Een manier om de prestatiegrenzen te blijven verhogen, is door meer CPU-kernen te laten samenwerken als u ze efficiënt kunt gebruiken.
Terwijl de snelheden zijn gedaald, is de grootte van de transistor blijven krimpen. Hoewel langzamer dan in het verleden, maken de kleine transistoren het mogelijk om meer logica op een enkele chip te plaatsen. Als gevolg hiervan kan het gebruik van deze transistors om meerdere CPU-kernen op een enkele chip te plaatsen profiteren van veel snellere en bredere busverbindingen tussen de verschillende CPU- en geheugensubsystemen.
Heterogene asymmetrische multiprocessing is erg handig wanneer een applicatie twee of meer workloads heeft met zeer verschillende kenmerken en vereisten. De ene kan afhankelijk zijn van realtime en onderbrekingslatentie, terwijl de andere meer afhankelijk kan zijn van doorvoer dan van responstijd. Dit model werkt heel goed:een apparaat kan bijvoorbeeld één kern toewijzen aan het beheer van een communicatieprotocolstack zoals Bluetooth of Zigbee, terwijl een andere kern fungeert als een applicatieprocessor die menselijke interacties en algemene systeembeheeractiviteiten uitvoert. De communicatieprocessor, die geïsoleerd is, kan een uitstekende realtime respons bieden die nodig is voor de protocolstack. Bovendien kan de communicatiesoftware worden gecertificeerd volgens een standaard waardoor het hele product eenvoudig te certificeren is door functionele wijzigingen gescheiden te houden van dit deel van het systeem.
Uitdagingen bij het gebruik van Multicore
Wat voor soort uitdagingen worden geïntroduceerd wanneer u meer dan één CPU-kern op een chip plaatst? Laten we er eens induiken.
Een monolithische applicatie of software is mogelijk niet in staat om de beschikbare computerbronnen efficiënt te gebruiken. U moet de toepassing indelen in parallelle taken die tegelijkertijd kunnen worden uitgevoerd om bronnen van meer dan één kern te gebruiken. Dit vereist mogelijk een onbekende manier voor software-engineers om te denken aan embedded design. Het migreren van bestaande single-loop-code is misschien niet zo eenvoudig. Te weinig threads of zelfs te veel threads kunnen prestatiebelemmeringen worden.
Toepassingen die datastructuren of I/O-apparaten delen over meerdere threads of processen, kunnen seriële knelpunten hebben. Om de gegevensintegriteit te behouden, moet de toegang tot deze gedeelde bronnen mogelijk worden geserialiseerd met behulp van vergrendelingstechnieken, bijvoorbeeld leesvergrendeling, lees-schrijfvergrendeling, schrijfvergrendeling, spinlock, mutex, enzovoort. Inefficiënt ontworpen vergrendelingen kunnen knelpunten veroorzaken als gevolg van hoge vergrendelingsconflicten tussen meerdere threads of processen die proberen de vergrendeling te verkrijgen om een gedeelde bron te gebruiken. Dit kan de prestaties van de applicatie of software mogelijk verslechteren. De prestaties van een applicatie kunnen zelfs afnemen naarmate het aantal cores of processors toeneemt als sommige cores vastlopen, andere wachten op gemeenschappelijke vergrendelingen waardoor twee cores slechter presteren dan één.
Een ongelijk verdeelde werklast kan inefficiënt zijn bij het gebruik van computerbronnen. Mogelijk moet u grote taken opsplitsen in kleinere die parallel kunnen worden uitgevoerd. Mogelijk moet u seriële algoritmen in parallelle algoritmen veranderen om de prestaties en schaalbaarheid te verbeteren. Als sommige taken echter zeer snel worden uitgevoerd en andere veel tijd in beslag nemen, kan het zijn dat de snelle taken een aanzienlijke hoeveelheid tijd besteden aan het wachten tot de lange taken zijn voltooid. Dit resulteert in het inactief zijn van waardevolle computerbronnen en slechte prestatieschaalbaarheid.
Een RTOS zal u waarschijnlijk helpen, maar lost mogelijk niet alles op. In een SMP-systeem is dit vrijwel een must om taken over een aantal vergelijkbare kernen te plannen. Het uit te voeren werk kan worden onderverdeeld naar gegevens of naar functie. Als je de dingen opdeelt in gegevensblokken, kan elke thread alle stappen in een verwerkingspijplijn uitvoeren. Als alternatief kunt u de ene thread één stap in de functie laten uitvoeren, terwijl een andere de volgende stap doet, enz. De voordelen van de ene techniek boven de andere hangen af van de kenmerken van het uit te voeren werk.
Foutopsporing in multicore-omgevingen
Het eerste dat handig is bij het debuggen van een multicore-systeem, is de zichtbaarheid van alle kernen. In het ideale geval zouden we kernen tegelijkertijd of afzonderlijk moeten kunnen starten en stoppen, dat wil zeggen, een enkele stap één kern terwijl andere worden uitgevoerd of gestopt. Multicore-onderbrekingspunten kunnen erg handig zijn om de werking van de ene kern te controleren op basis van de status van een andere.
Multicore-tracering kan erg moeilijk te implementeren zijn. Het beheren van de hoge bandbreedte van traceerinformatie van verschillende kernen, evenals het omgaan met mogelijk verschillende soorten traceringsgegevens van verschillende soorten kernen, is een echte uitdaging.
(Bron:IAR Systems, diagram met dank aan Arm Ltd.)
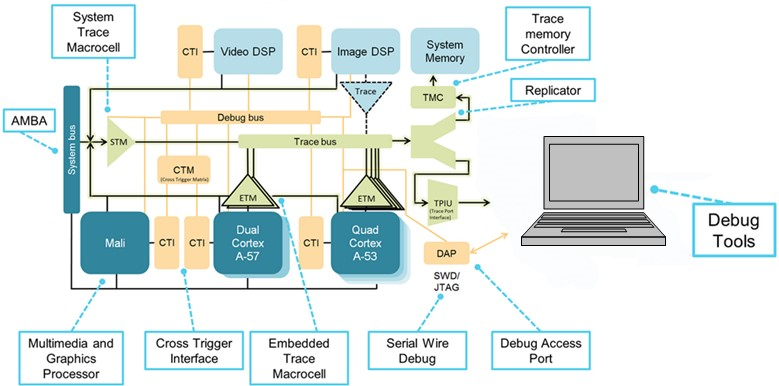
Hier is een voorbeeld van een processor met zowel heterogene als homogene multicore-implementaties. Er zijn twee homogene kerngroepen, één gebaseerd op een dual Arm Cortex-A57 en de andere op een quad Cortex-A53. Deze groepen zijn homogeen binnen zichzelf, maar heterogeen tussen de twee groepen.
De CoreSight-debug-architectuur biedt protocollen en mechanismen voor communicatie met de debug-bronnen op alle kernen en het is aan de debugger om al deze informatie te beheren en berichten van verschillende kernen te ontleden. De cross-trigger-interfaces en matrix (CTI, CTM) maken gelijktijdige stopzetting van beide kernen, triggering van trace en meer mogelijk. De traceringsinfrastructuur omvat de seriële (SWD) en parallelle (TPIU) traceerpoorten die worden gebruikt voor het afvlakken van de traceringsstroom, en de traceringtrechters die de tracering van elke bron in een enkele stroom combineren. Vergeleken met het dual-core deel, vertegenwoordigt het getoonde diagram een veel complexere chip om te besturen.
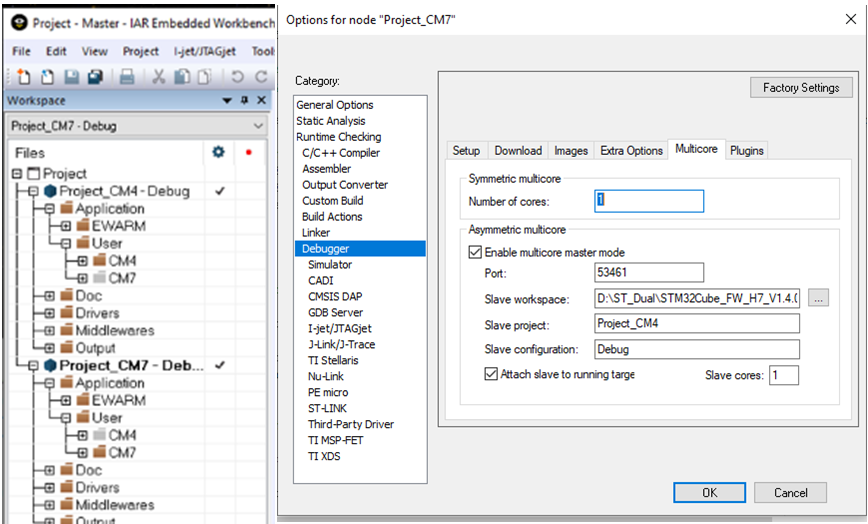
De C-SPY Debugger in IAR Embedded Workbench biedt ondersteuning voor zowel symmetrische als asymmetrische multicore-foutopsporing. Dit wordt ingeschakeld via de debugger-opties op het multicore-tabblad. Om symmetrische multicore-foutopsporing mogelijk te maken, hoeft u alleen het aantal kernen in te voeren om de debugger te laten weten met hoeveel verschillende processors hij moet communiceren. Andere IDE's hebben mogelijk vergelijkbare opties.
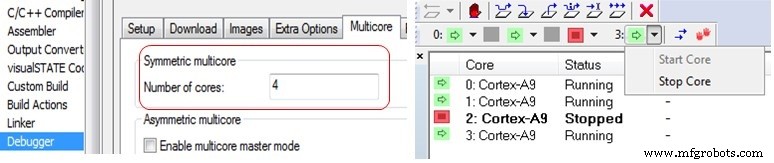
Aan de rechterkant (hierboven) ziet u een weergave in de debugger waar een 4-core Cortex-A9 SMP-cluster de cores-status heeft weergegeven met core nummer 2 gestopt terwijl de andere drie cores worden uitgevoerd.
Een asymmetrisch multicore-systeem kan een heterogeen multicore-onderdeel gebruiken, zoals de ST STM32H745/755 die één Cortex-M7-kern en een afzonderlijke Cortex-M4 heeft. In dit geval gebruikt de debugger twee instanties van de IDE (Master en Node). Eén voor elke kern, aangezien de twee kernen verschillende projectcode uitvoeren.
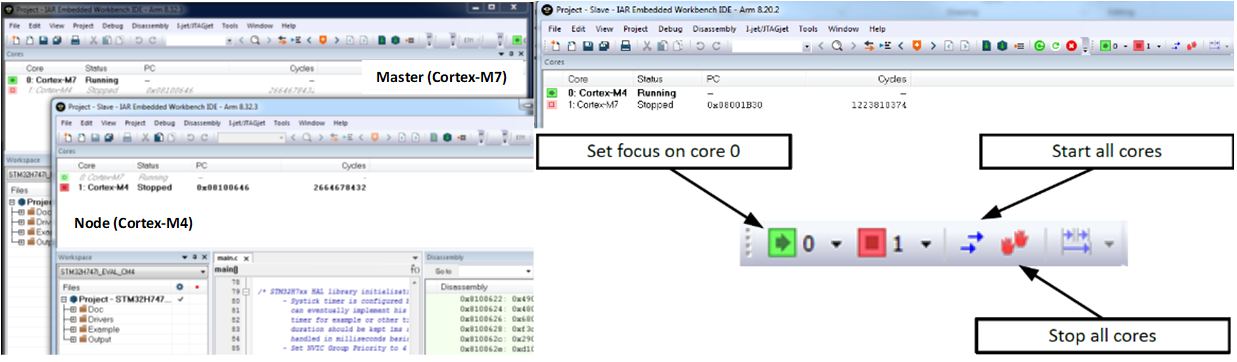
In elk exemplaar van de IDE is er statusinformatie over de kern die wordt beheerd en de andere kern die wordt beheerd in het andere venster. Er zijn opties die kunnen worden geselecteerd om het gedrag van de debugger te regelen, zodat het starten en stoppen van de kernen samen of afzonderlijk onder de controle van de ontwikkelaar valt.
Deze volledige controle is mogelijk dankzij de cross trigger interfaces (CTI) en cross trigger matrix (CTM) die samen de Arm embedded cross trigger-functie vormen. Er zijn drie CTI-componenten, een op systeemniveau, een voor de Cortex-M7 en een voor de Cortex-M4. De drie CTI's zijn met elkaar verbonden via de CTM zoals weergegeven in onderstaande figuur. Het systeemniveau en de Cortex-M4 CTI's zijn toegankelijk voor de debugger via de systeemtoegangspoort en de bijbehorende APB-D. De Cortex-M7 CTI is fysiek geïntegreerd in de Cortex-M7 core en is toegankelijk via de Cortex-M7 toegangspoort.
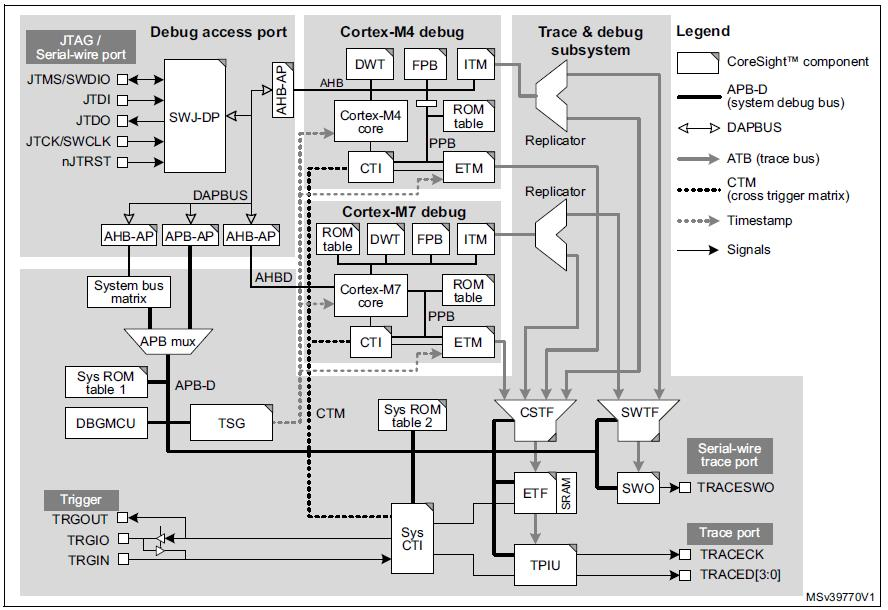
(Bron:IAR Systems, diagram met dank aan STMicroelectronics uit M0399 Reference manual)
Met de CTI's kunnen gebeurtenissen uit verschillende bronnen debug- en traceeractiviteit activeren. Een breekpunt dat in een van de processorkernen wordt bereikt, kan bijvoorbeeld de andere processor stoppen, of een gedetecteerde overgang op een externe triggeringang kan worden ingesteld om codetracering te starten.
In dit voorbeeld met een heterogene multicore-processor met een Cortex-M7-kern en een Cortex-M4-kern op een enkele chip, worden twee afzonderlijke programma's gebruikt:een om op de Cortex-M4 te draaien en de andere op de Cortex-M7. Elk project gebruikt FreeRTOS om de software op de processors te beheren. De twee kernen communiceren via een gedeelde geheugeninterface. De applicaties gebruiken echter beide de FreeRTOS-mechanisme voor het doorgeven van berichten om met de andere processor te communiceren en de complexiteit van de onderliggende mechanismen te verbergen. Dus vanuit het perspectief van de ene CPU is het gewoon berichten verzenden of ontvangen met een andere taak. Het is duidelijk dat de andere taak toevallig op een andere CPU-kern draait.
De afbeelding hieronder is de weduwe van de werkruimteverkenner in de IDE. Het overzicht van twee projecten wordt hier weergegeven, zodat u de inhoud van zowel de Cortex-M7- als de Cortex-M4-projecten kunt zien.
Door een van de andere tabbladen onder aan het venster te selecteren, kunt u de focus overschakelen naar het M4-project of het M7-project.
Het Cortex-M7-project heeft een taak die berichten verzendt naar taken die op de Cortex-M4 worden uitgevoerd. De Cortex-M4 heeft twee exemplaren van een ontvangsttaak. De Cortex-M7 heeft een "controle"-taak die periodiek wordt uitgevoerd om te zien of alles nog goed werkt.
Ten slotte laadt de debugger beide projecten. Dit betekent dat een extra exemplaar van Embedded Workbench voor de tweede debugger wordt gestart.
Om de debugger in te stellen voor asymmetrische multiprocessing-ondersteuning, moeten we het ene project aanwijzen als het "Master" en het andere als het "Node" -project. In feite is de selectie willekeurig en bepaalt alleen welk project de mogelijkheid heeft om het andere te starten bij het opstarten.
Het "Node"-project heeft geen speciale instellingen en weet niet dat het als een "Node" naar een ander project wordt uitgevoerd.
Op deze manier, wanneer de debugger van het "Master"-project is gestart, wordt automatisch een andere instantie van de IDE gestart om plaats te bieden aan een tweede debugger-sessie waarin het tweede project zal worden uitgevoerd.
Samenvatting
Multicore maakt prestatiewinst mogelijk wanneer de wet van Moore opraakt. Multicore biedt echter uitdagingen op het gebied van foutopsporing en vereist specifieke ontwikkelingsbenaderingen, zodat de toepassing maximaal kan profiteren van de multicore-architectuur.
Zodra de debug-setup is geconfigureerd, is multicore-foutopsporing nog nooit zo eenvoudig geweest. Als je al eerder tools voor het debuggen van monocores hebt gebruikt, zul je alles herkennen wat hierin zit en je zult waarschijnlijk nooit begrijpen dat andere mensen praten over hoe moeilijk multicore debugging voor hen is.
Moderne hardware- en softwaretools helpen u bij het overwinnen van multicore-foutopsporingsuitdagingen.
Opmerking:afbeeldingsafbeeldingen zijn van IAR Systems, tenzij anders vermeld.
 Aaron Bauch is een Senior Field Application Engineer bij IAR Systems en werkt met klanten in het oosten van de Verenigde Staten en Canada. Aaron heeft gewerkt met embedded systemen en software voor bedrijven als Intel, Analog Devices en Digital Equipment Corporation. Zijn ontwerpen bestrijken een breed scala aan toepassingen, waaronder medische instrumentatie, navigatie en banksystemen. Aaron heeft ook een aantal cursussen op universitair niveau gegeven, waaronder Embedded System Design als professor aan de Southern NH University. De heer Bauch heeft een bachelor in elektrotechniek van The Cooper Union en een master in elektrotechniek van Columbia University, beide in New York, NY.
Aaron Bauch is een Senior Field Application Engineer bij IAR Systems en werkt met klanten in het oosten van de Verenigde Staten en Canada. Aaron heeft gewerkt met embedded systemen en software voor bedrijven als Intel, Analog Devices en Digital Equipment Corporation. Zijn ontwerpen bestrijken een breed scala aan toepassingen, waaronder medische instrumentatie, navigatie en banksystemen. Aaron heeft ook een aantal cursussen op universitair niveau gegeven, waaronder Embedded System Design als professor aan de Southern NH University. De heer Bauch heeft een bachelor in elektrotechniek van The Cooper Union en een master in elektrotechniek van Columbia University, beide in New York, NY. Verwante inhoud:
- Zorgen voor het timinggedrag van software in kritieke op multicore gebaseerde embedded systemen
- Multicore-systemen, hypervisors en multicore-frameworks
- High-performance embedded computing – Parallellisme en compiler-optimalisatie
- Denk je dat je software werkt? Bewijs het!
- Softwaretracering in in het veld geïmplementeerde apparaten
- Compilers in de buitenaardse wereld van functionele veiligheid
Abonneer u voor meer Embedded op de wekelijkse e-mailnieuwsbrief van Embedded.
Ingebed
- WiFi-netwerken, SaaS-providers en de uitdagingen die ze met zich meebrengen voor IT
- Boards – Breakout the Pi – I2C, UART, GPIO en meer
- De vijf belangrijkste problemen en uitdagingen voor 5G
- De complexe risicofactoren voor ruimtevaart en defensie
- 5G, IoT en de nieuwe supply-chain-uitdagingen
- Voldoe aan de ETL-uitdagingen van IoT-gegevens en maximaliseer de ROI
- De uitdagingen van hard draaien de baas worden
- De 4 grote uitdagingen waarmee de OEM-industrie voor lucht- en ruimtevaart en defensie wordt geconfronteerd
- Het belang en de uitdagingen van up-to-date documentatie
- De voordelen en uitdagingen voor hybride productie begrijpen
- Het ontwerp- en implementatieproces voor fabrieksautomatisering