


Deep learning versus machinaal leren
In de begindagen van computers gebruikten wetenschappers ze voornamelijk om eenvoudige wiskundige en logische bewerkingen uit te voeren. Daarna evolueerden computers langzaam om complexe berekeningen uit te voeren, problemen op te lossen en de informatieruggengraat van de wereld te vormen. Door verder te gaan dan het traditionele computergebruik, had de computer intelligentie nodig.
Onderzoekers en computeringenieurs gingen menselijke intelligentie nabootsen. Kunstmatige intelligentie (AI) is het gebied van de informatica dat zich toelegt op het creëren van computersystemen die net zo intelligent zijn als mensen. De eerste AI-modellen waren computersystemen die complexe logische bewerkingen uitvoerden. Later werden meer geavanceerde technieken ontwikkeld om slimmere of 'intelligente' taken uit te voeren.
Twee van de meest gebruikte termen in AI zijn machine learning en deep learning. Dit artikel gaat in op de oorsprong van deze twee technieken, de overeenkomsten ertussen en de verschillen.
Deep Learning en Machine Learning
Machine learning en deep learning zijn subsets van AI. Tussen hen is deep learning de subset van machine learning. Dit betekent dat alle deep learning machine learning is, maar niet alle machine learning deep learning. Om de verschillen tussen beide te begrijpen, sluit de term machine learning diep leren uit voor de rest van dit artikel.
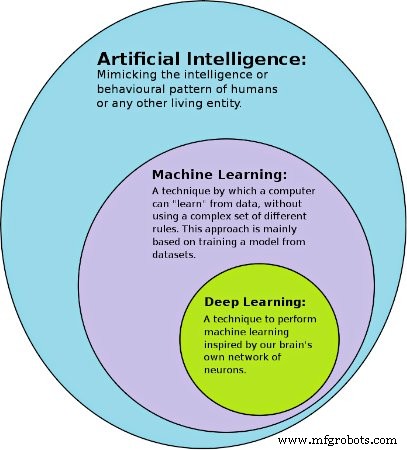
Figuur 1. Een afbeelding die laat zien hoe AI, machine learning en deep learning zich tot elkaar verhouden. Afbeelding gebruikt met dank aan Avimanyu786
Machineleren
Machine learning analyseert een grote hoeveelheid gegevens om de kenmerken van een trainingsdataset te begrijpen. Wat is geleerd van de trainingsdataset wordt toegepast op andere datasets om 'intelligente' beslissingen te nemen. De modellen die met de trainingsgegevensset zijn gemaakt, kunnen met andere vergelijkbare gegevenssets werken om de gewenste uitvoer te genereren.
De trainingsdataset voor machine learning-modellen moet worden gelabeld en de ontwikkelaars moeten het leerproces begeleiden en aanpassen terwijl het nieuwe model wordt getraind. Naast basiscomputergebruik worden statistische modellen veel gebruikt voor het trainen van machine learning-modellen.
Het onderscheid tussen katten en honden is een bekend voorbeeld in de kunstmatige leerruimte. Hieronder volgt een overzicht van hoe machine learning-modellen worden getraind met gegevens.
Het trainingsmodel wordt gevoed met duizenden afbeeldingen van katten en honden. Elk van die afbeeldingen heeft het label 'kat' of 'hond'. Het model in opleiding identificeert kenmerken uit de afbeeldingen die katten, honden en de rest van de objecten onderscheiden. De eigenschappen worden geïdentificeerd aan de hand van de afbeeldingen met behulp van statistische technieken. Nadat het model met voldoende gegevens is getraind, wordt het gevoed met ongelabelde afbeeldingen. Als het getrainde model met succes de beelden van katten en honden met de gewenste nauwkeurigheid kan onderscheiden, is het een succesvol machine learning-model.
Deep Learning
Deep learning is de evolutie van conventioneel machine learning. Mensen leren niet met duizenden gelabelde voorbeelden; ze leren automatisch zonder veel externe hulp of validatie. Deep learning brengt machine learning een stap dichter bij dit model van intelligent leren.
Deep learning-modellen moeten ook worden getraind met een grote hoeveelheid gegevens, maar modellen worden niet getraind met gelabelde gegevens. Alle gegevens die naar het deep learning-model worden gevoerd, zijn niet gelabeld. Het model identificeert verschillende elementen uit de gegevens om de vereiste output te geven.

Figuur 2. Een visuele weergave van neurale netwerken die in de landbouw worden gebruikt.
Deep learning-modellen gebruiken complexe wiskundige systemen die neurale netwerken worden genoemd om van gegevens te leren. Het bevat meerdere lagen wiskundige functies met verschillende gewichten. Het 'diepe' in de term deep learning komt van deze verwerkingslagen.
Laten we eens kijken hoe deep learning-modellen het onderscheiden van katten en honden aanpakken. Een neuraal netwerk wordt gevoed met talloze ongelabelde afbeeldingen van katten en honden. Het neurale netwerk moet uitzoeken dat er twee sets dieren op de foto's staan en vervolgens bepalen hoe de twee dieren van elkaar kunnen worden onderscheiden. Er zijn geen gelabelde gegevens vereist of toezicht van ontwikkelaars.
Zodra een model met succes is getraind, kan het een willekeurig aantal afbeeldingen van katten en honden onderscheiden.
Machine learning en deep learning vergelijken
De volgende tabel is een snelle vergelijking van de verschillen tussen machine learning en deep learning. Houd er rekening mee dat deep learning voor deze vergelijking is uitgesloten van de term machine learning, ook al is deep learning een subset van machine learning.
| Machineleren | Deep Learning | |
| Trainingsgegevens | Gelabelde gegevens | Niet-gelabelde gegevens |
| Toezicht | Begeleid leren | Leren zonder toezicht |
| Technieken | Meestal statistische technieken | Geavanceerde wiskundige functies |
| Gegevensvolume | Relatief minder trainingsgegevens nodig | Er is een zeer grote hoeveelheid gegevens vereist |
| Nauwkeurigheid | Relatief lage nauwkeurigheid | Hogere nauwkeurigheid met groot datavolume |
| Trainingstijd | Relatief minder | Zeer hoge trainingstijd |
Figuur 3. Een tabel waarin machine learning en deep learning worden vergeleken.
Industriële toepassingen voor diep leren
Zowel machine learning als deep learning hebben industriële toepassingen. Deep learning kan worden gebruikt in alle toepassingen die kunnen worden bereikt door machine learning. Maar deep learning vereist meer expertise, een veel groter datavolume, meer rekenkracht en tijd. Vanwege deze factoren moet bij de keuze tussen beide technieken rekening worden gehouden met een groot aantal factoren.
Wanneer een hogere nauwkeurigheid vereist is, hebben deep learning-modellen de voorkeur. Om echter een hogere nauwkeurigheid te bereiken met deep learning-modellen, moet een zeer grote hoeveelheid gegevens worden verwerkt, waardoor een veel langere trainingsperiode nodig is. Algoritmen voor machinaal leren kunnen in de meeste gevallen routinematig worden gebruikt.
Een ander algemeen kenmerk waarmee rekening moet worden gehouden, is de complexiteit van het probleem. Naarmate de complexiteit toeneemt, werken deep learning-modellen beter dan machine learning-modellen. Er is echter geen pasklare regel over waar de technieken moeten worden gebruikt. Machine learning is bijvoorbeeld voldoende om het energieverbruik in een installatie te analyseren en te voorspellen. Het is echter onvoldoende om een geautomatiseerd kwaliteitscontrolesysteem te bouwen - in dergelijke scenario's zijn deep learning-algoritmen nodig.
Tegenwoordig is machine learning veel toegankelijker dan deep learning, zelfs in de branche. Maar te zijner tijd zullen deep learning-modellen verbeteren, de implementatiekosten en toegangsdrempels verminderen, wat betekent dat er meer rekenkracht beschikbaar zal zijn tegen een lagere prijs. De acceptatie van deep learning in de branche zal in de loop van de tijd toenemen.
Internet of Things-technologie
- Machine learning op AWS; Weet het allemaal
- De toeleveringsketen en machine learning
- Gegevensbeheer stimuleert machine learning en A.I. in IIOT
- Hoe kunstmatige intelligentie en machinaal leren het bijhouden van activa vormen
- Machine learning gebruiken in de hedendaagse zakelijke omgeving
- Kunstmatige intelligentie versus machinaal leren versus diep leren | Het verschil
- Machine learning in het veld
- Machine learning in voorspellend onderhoud
- Voorspel de levensduur van de batterij met machine learning
- Het leven als AI-onderzoeker en machine learning-ingenieur
- Machine learning gedemystificeerd