


Onderzoekers tonen AI-chip met verminderde precisietraining
Op ISSCC presenteerde IBM Research een testchip die de hardware-manifestatie vertegenwoordigt van zijn jarenlange werk aan low-precision AI-training en inferentie-algoritmen. De 7nm-chip ondersteunt 16-bit en 8-bit training, evenals 4-bit en 2-bit inferentie (32-bit of 16-bit training en 8-bit inferentie zijn tegenwoordig de industriestandaard).
Het verminderen van precisie kan de hoeveelheid rekenkracht en kracht die nodig is voor AI-berekeningen verminderen, maar IBM heeft een paar andere architecturale trucs in petto die ook de efficiëntie ten goede komen. De uitdaging is om de precisie te verminderen zonder het resultaat van de berekening negatief te beïnvloeden, iets waar IBM al een aantal jaren aan werkt op algoritmeniveau.
IBM's AI Hardware Center werd in 2019 opgericht om de doelstelling van het bedrijf te ondersteunen om de AI-computerprestaties 2,5x per jaar te verhogen, met een ambitieus algemeen doel van 1000x prestatie-efficiëntie (FLOPS/W) verbetering tegen 2029. Ambitieuze prestatie- en vermogensdoelen zijn noodzakelijk sinds de omvang van AI-modellen en de hoeveelheid rekenkracht die nodig is om ze te trainen, groeit snel. Met name Natural Language Processing (NLP)-modellen zijn nu kolossen met biljoenen parameters, en de ecologische voetafdruk die gepaard gaat met het trainen van deze beesten is niet onopgemerkt gebleven.
Deze nieuwste testchip van IBM Research laat zien welke vooruitgang IBM tot nu toe heeft geboekt. Voor 8-bits training is de 4-core-chip in staat tot 25,6 TFLOPS, terwijl de inferentieprestaties 102,4 TOPS zijn voor 4-bits integerberekening (deze cijfers zijn voor een klokfrequentie van 1,6 GHz en een voedingsspanning van 0,75 V). Door de klokfrequentie te verlagen tot 1 GHz en de voedingsspanning tot 0,55 V te verlagen, wordt de energie-efficiëntie verhoogd tot 3,5 TFLOPS/W (FP8) of 16,5 TOPS/W (INT4).
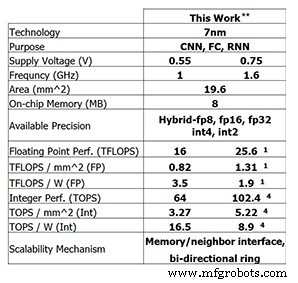
Prestaties van de testchip van IBM Research (Afbeelding:IBM Research) **Gerapporteerde prestaties bij 0% schaarste. (1) KP8. (4) INT4.
Lage precisietraining
Deze voorstelling bouwt voort op jarenlang algoritmisch werk aan lage-precisietraining en inferentietechnieken. De chip is de eerste die IBM's speciale 8-bit hybride drijvende-komma-indeling (hybride FP8) ondersteunt, die voor het eerst werd gepresenteerd op NeurIPS 2019. Dit nieuwe formaat is speciaal ontwikkeld om 8-bits training mogelijk te maken, waardoor de benodigde rekenkracht voor 16-bits wordt gehalveerd. training, zonder de resultaten negatief te beïnvloeden (lees hier meer over getalnotaties voor AI-verwerking).
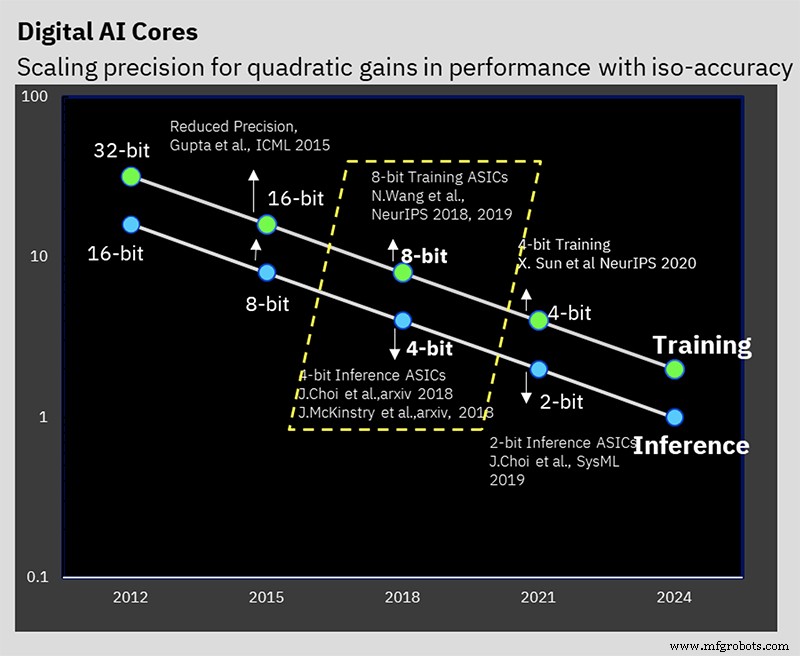
IBM Research heeft gewerkt aan het oplossen van het probleem van het handhaven van de nauwkeurigheid en het verminderen van de precisie (Afbeelding:IBM)
Kailash Gopalakrishnan, IBM Fellow en senior manager voor acceleratorarchitecturen en machine learning bij IBM Research vertelde EE Times . "Het begrijpen van de juiste numerieke formaten en deze op de juiste tensoren zetten in deep learning was een cruciaal onderdeel ervan."
Hybrid FP8 is eigenlijk een combinatie van twee verschillende formaten. Eén formaat wordt gebruikt voor gewichten en activeringen in de voorwaartse pas van diep leren, en een andere wordt gebruikt in de achterwaartse pas. Inference gebruikt alleen de voorwaartse pas, terwijl training zowel voorwaartse als achterwaartse fasen vereist.
"Wat we hebben geleerd, is dat je meer betrouwbaarheid en meer precisie nodig hebt in termen van de weergave van gewichten en activeringen in de voorwaartse pas van diep leren," zei Gopalakrishnan. "Aan de andere kant [de achterwaartse fase] hebben de gradiënten een hoog dynamisch bereik, en dat is waar we de noodzaak erkennen om een [grotere] exponent te hebben... dit is de wisselwerking tussen hoe sommige tensoren in diep leren nodig hebben meer nauwkeurigheid, een hogere getrouwheidsweergave, terwijl andere tensoren een groter dynamisch bereik nodig hebben. Dit is het ontstaan van het hybride FP8-formaat dat we eind 2019 presenteerden en dat zich nu heeft vertaald in hardware.”
IBM's werk stelde vast dat de beste manier om de 8 bits tussen de exponent en mantisse te splitsen 1-4-3 is (een tekenbit, een vier-bits exponent en een drie-bits mantisse) voor de voorwaartse fase, met een alternatief 5- bit exponent-versie voor de achterwaartse fase, die een dynamisch bereik van 2 32 . geeft . Hybride FP8-compatibele hardware is ontworpen om beide formaten te ondersteunen.
Hiërarchische accumulatie
Een innovatie die de onderzoekers 'hiërarchische accumulatie' noemen, maakt het mogelijk dat de accumulatie in precisie wordt verminderd naast de gewichten en activeringen. Typische FP16-trainingsschema's stapelen zich op in 32-bits rekenkunde om de precisie te behouden, maar IBM's 8-bits training kan zich ophopen in FP16. Het behouden van accumulatie in FP32 zou de voordelen van de overstap naar FP8 in de eerste plaats hebben beperkt.
"Wat er gebeurt in drijvende-kommaberekeningen, is dat als je een grote reeks getallen bij elkaar optelt, laten we zeggen dat het een vector met een lengte van 10.000 is en je alles bij elkaar optelt, de nauwkeurigheid van de drijvende-kommaweergave zelf de precisie van je som,” legde Gopalakrishnan uit. "We kwamen tot de conclusie dat de beste manier om dat te doen is om niet op een sequentiële manier op te tellen, maar we hebben de neiging om de lange accumulatie op te splitsen in groepen, wat we brokken noemen. En dan voegen we de brokken aan elkaar toe, en dat minimaliseert de kans op dit soort fouten.”
Inferentie met lage precisie
De meeste AI-inferenties gebruiken tegenwoordig het 8-bits integer-formaat (INT8). Het werk van IBM heeft aangetoond dat 4-bit integer de state-of-the-art is in termen van hoe lage precisie kan gaan zonder significante voorspellingsnauwkeurigheid te verliezen. Na kwantisatie (het proces van het converteren van het model naar lagere precisiegetallen), wordt kwantisatiebewuste training uitgevoerd. Dit is in feite een omscholingsschema dat eventuele fouten als gevolg van kwantisering vermindert. Deze hertraining kan nauwkeurigheidsverlies minimaliseren; IBM kan "gemakkelijk" kwantiseren tot 4-bits gehele rekenkunde met slechts een half procent verlies aan nauwkeurigheid, wat volgens Gopalakrishnan "zeer acceptabel" is voor de meeste toepassingen.
Op-chip ring
Afgezien van de focus op rekenen met lage precisie, zijn er andere hardware-innovaties die bijdragen aan de efficiëntie van de chip.
Een daarvan is on-chip ringcommunicatie, een netwerk-op-chip dat is geoptimaliseerd voor deep learning en waarmee elk van de kernen gegevens naar de andere kan multicasten. Multicast-communicatie is van cruciaal belang voor deep learning, omdat de kernen gewichten moeten delen en resultaten moeten communiceren naar andere kernen. Het maakt het ook mogelijk om gegevens die zijn geladen uit off-chip geheugen naar meerdere kernen te verzenden. Dit vermindert het aantal keren dat het geheugen moet worden gelezen en de totale hoeveelheid gegevens die wordt verzonden, waardoor de vereiste geheugenbandbreedte wordt geminimaliseerd.
"We realiseerden ons dat we de kernen sneller konden laten lopen dan de ringen, omdat de ringen veel lange draden bevatten", zegt Ankur Agrawal, onderzoeksmedewerker in machine learning en accelerator-architecturen bij IBM Research. "We hebben de werkingsfrequentie van de ring losgekoppeld van de werkingsfrequentie van de kernen... waardoor we onafhankelijk de prestaties van de ring ten opzichte van de kernen kunnen optimaliseren."
Energiebeheer
Een andere innovatie van IBM was de introductie van een frequentieschaalschema om de efficiëntie te maximaliseren.
"Deep learning-workloads zijn een beetje speciaal, omdat je zelfs tijdens de compilatiefase weet welke rekenfasen je tegenkomt in deze zeer grote workload", zegt Agrawal. "We kunnen wat voorconfiguratie doen om erachter te komen hoe het vermogensprofiel eruit zal zien in verschillende delen van de berekening."
Het krachtprofiel van deep learning heeft doorgaans grote pieken (voor rekenintensieve bewerkingen zoals convolutie) en dalen (misschien voor activeringsfuncties).
Het schema van IBM stelt de initiële bedrijfsspanning en -frequentie van de chip behoorlijk agressief in, zodat zelfs voor de laagste vermogensmodi de chip bijna aan de limiet van zijn vermogensbereik zit. Als er dan meer vermogen nodig is, wordt de werkfrequentie verlaagd.
"Het nettoresultaat is een chip die tijdens de hele berekening op bijna het piekvermogen werkt, zelfs tijdens de verschillende fasen", legt Agrawal uit. “Over het algemeen kun je alles sneller doen door deze fasen van laag stroomverbruik niet te hebben. Je hebt eventuele dalingen in het stroomverbruik vertaald in prestatieverbeteringen door je stroomverbruik bijna op het piekstroomverbruik te houden voor alle bedrijfsfasen."
Spanningsschaling wordt niet gebruikt omdat het moeilijker is om on-the-fly te doen; de tijd die nodig is om te stabiliseren op de nieuwe spanning is te lang voor deep learning-berekeningen. IBM kiest er daarom over het algemeen voor om de chip op de laagst mogelijke voedingsspanning voor dat procesknooppunt te laten draaien.
Testchip
De testchip van IBM heeft vier kernen, deels om alle verschillende functies te kunnen testen. Gopalakrishnan beschreef hoe de kerngrootte bewust als een optimum is gekozen; een architectuur van duizenden kleine kernen is complex om met elkaar te verbinden, terwijl het verdelen van het probleem over grote kernen ook moeilijk kan zijn. Deze tussenliggende kern is ontworpen om te voldoen aan de behoeften van IBM en zijn partners in het AI Hardware Center en vonden een goede plek in termen van grootte.
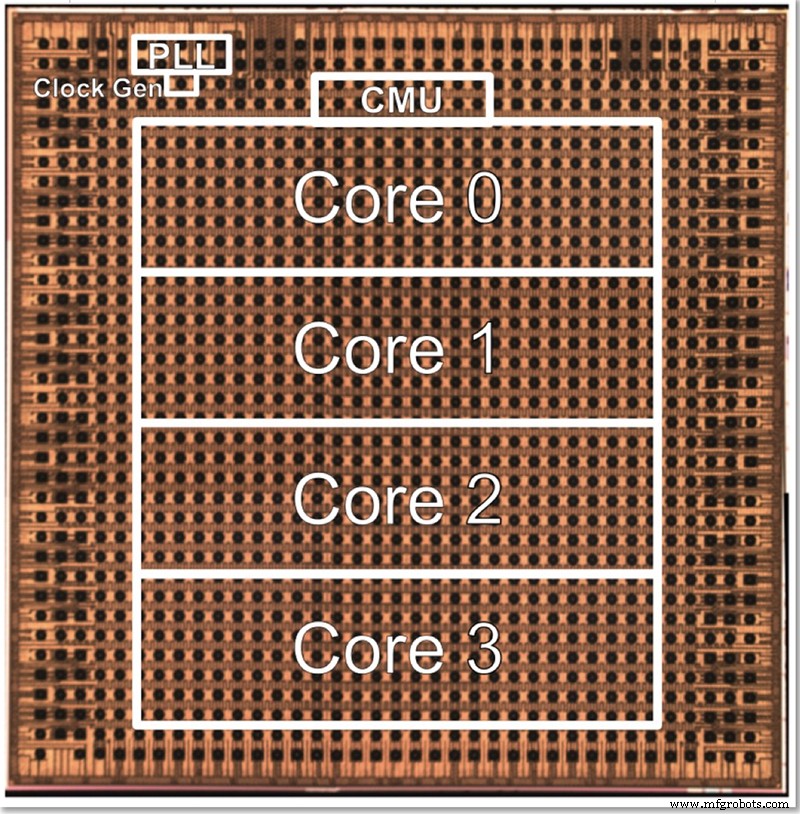
Een matrijsfoto voor IBM's 4-core low-precision testchip (Afbeelding:IBM)
De architectuur kan omhoog of omlaag worden geschaald door het aantal cores te wijzigen. Uiteindelijk stelt Gopalakrishnan zich voor dat 1-2 core-chips geschikt zouden zijn voor edge-apparaten, terwijl 32-64 core-chips zouden kunnen werken in het datacenter. Het feit dat het meerdere formaten ondersteunt (FP16, hybride FP8, INT4 en INT2) maakt het ook veelzijdig genoeg voor de meeste toepassingen, zei hij.
"Verschillende [toepassings]-domeinen zouden verschillende vereisten hebben voor energie-efficiëntie en precisie, enzovoort, enzovoort", zei hij. "Ons Zwitsers zakmes van precisie, elk afzonderlijk geoptimaliseerd, stelt ons in staat om deze kernen in verschillende domeinen te richten zonder noodzakelijkerwijs energie-efficiëntie op te geven in dat proces."
Naast de hardware heeft IBM Research ook een tool-stack ("Deep Tools") ontwikkeld waarvan de compiler een hoog gebruik van de chip mogelijk maakt (60-90%).
EE Times ' Uit een vorig interview met IBM Research bleek dat low-precision AI-training en inferentiechips op basis van deze architectuur over ongeveer twee jaar op de markt zouden moeten komen.
>> Dit artikel is oorspronkelijk gepubliceerd op onze zustersite, EE Times.
Verwante inhoud:
- AI-chips behouden nauwkeurigheid met modelreductie
- AI-modellen trainen op het randje
- De race is begonnen voor AI aan de rand
- Edge AI daagt geheugentechnologie uit
- Technische groep probeert 1mW AI naar de rand te duwen
- Neurale netwerktoepassing voor kleinschalige taken
- AI IC-onderzoek verkent alternatieve architecturen
Abonneer u voor meer Embedded op de wekelijkse e-mailnieuwsbrief van Embedded.
Ingebed
- Ontwerpen met Bluetooth Mesh:chip of module?
- Onderzoekers bouwen kleine authenticatie-ID-tag
- Omgaan met minder onderhoudspersoneel
- Rockwell alliantie met Minnesota College breidt toegang tot automatiseringstraining uit
- Onderzoekers laten zien hoe Bluetooth Classic-beveiligingsfouten kunnen worden misbruikt
- Hoe IBM Watson elk ander bedrijf voorziet van AI
- Verhoog uw marketinginspanningen om te presteren met bureauprecisie
- Verhoog uw marketinginspanningen om te presteren met bureauprecisie
- IBM:proactief zorgen voor betrouwbaarheid en veiligheid met EAM
- Superieure hydraulische systemen bouwen met precisiebewerking
- 10 precisiecomponenten vervaardigd met CNC-bewerkingsmachines