


Cloudstoring:waarom en hoe gebeurt het?
Hoe meer IT afhankelijk is van cloudservices, hoe groter de kans dat u te maken krijgt met downtime en omzetverliezen als gevolg van een cloudstoring. Meer dan 60% van de organisaties die de openbare cloud gebruiken, meldt verliezen in 2022 als gevolg van deze incidenten, dus storingen zijn geen buitenissige gebeurtenissen waar bedrijven waarschijnlijk niet mee te maken zullen krijgen.
Maar zijn uitval voldoende reden om de cloud voorgoed te verlaten? Of moet u bij dit type infrastructuur blijven ondanks het risico van occasionele downtime?
In dit artikel wordt alles beschreven wat u moet weten over cloudstoringen . We schetsen hun belangrijkste oorzaken, onderzoeken eye-openende statistieken, laten zien hoe de impact van cloud-downtime kan worden geminimaliseerd en kijken naar de meest impactvolle storingen die zich de afgelopen jaren hebben voorgedaan.

Wat is een cloudstoring?
Een cloudstoring is een periode waarin de services van een cloudprovider niet beschikbaar zijn voor eindgebruikers. De infrastructuur van de leverancier valt uit (vanwege een bug, stroomstoring, enz.) en de klanten verliezen de toegang tot cloudgebaseerde activa totdat de provider het probleem heeft opgelost.
Wat de impact betreft, is er geen verschil tussen een datacenter op locatie dat uitvalt en een cloudstoring. In beide gevallen verliest u de toegang tot IT-middelen, maar de hands-off benadering van cloud computing voegt een paar unieke overwegingen toe:
- Cloudstoringen hebben weinig tot geen zichtbaarheid van storingen, dus gebruikers weten doorgaans niet wat er mis is gegaan.
- Het team van de provider is verantwoordelijk voor het oplossen van de fout, dus klanten nemen niet deel aan het herstelproces.
- Omdat je geen zicht hebt op of controle hebt over het probleem, is er geen manier om te weten wanneer services weer online gaan.
Net als bij lokale hardware zijn er twee soorten storing:
- Gepland (gebeurt meestal vanwege gepland onderhoud).
- Ongepland (gebeurt wanneer de provider een onverwachte fout tegenkomt en herstelmaatregelen moet uitvoeren).
Recente onderzoeken tonen aan dat ongeplande uitval 35% meer kost dan geplande downtime (zowel on-premise als in de cloud). Het prijsverschil bestaat omdat onverwachte incidenten meer tijd nodig hebben om te identificeren en op te lossen, en hoe langer een storing duurt, hoe groter de schade.
Vergeleken met hardware op locatie resulteert een cloudgebaseerde infrastructuur in meer frequente downtime, maar met minder ernst . Aangezien geen enkel hostingsysteem 100% uptime biedt, zijn klanten bereid om incidentele uitval te tolereren in ruil voor voordelen van cloudcomputing. Deze bereidheid blijkt ook uit de marktgroei:de cloud zal in 2024 14,2% van de totale wereldwijde IT-uitgaven uitmaken (tegen 9,1% in 2020).
Oorzaken cloudstoring
Cloudstoringen zijn het gevolg van een aantal oorzaken, zowel binnen als buiten de controle van de provider. Hier is een lijst met de meest voorkomende:
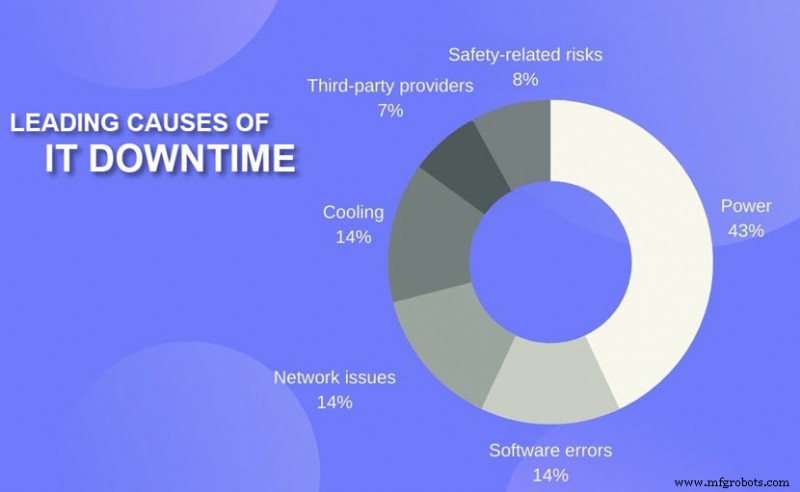
- Stroomuitval: Stroomgerelateerde problemen veroorzaken 43% van alle uitval van de cloud met aanzienlijke downtime en financieel verlies. Storingen in de ononderbroken stroomvoorziening (UPS) zijn de belangrijkste oorzaak van stroomstoringen.
- Cyberbeveiliging: Cyberaanvallen zoals de Distributed Denial of Service (DDoS) overladen datacenters met inkomend verkeer. In dat geval hebben eindgebruikers geen toegang tot de dienst via dezelfde netwerkinfrastructuur. Andere bedreigingen (zoals ransomware of een SQL-injectie) kunnen de provider dwingen om services af te sluiten en het probleem offline op te lossen.
- Menselijke fout: Een enkele foutieve opdracht of een fout in de bekabeling kan de hele IT-infrastructuur platleggen. Menselijke fouten veroorzaken zowel fysieke als softwareproblemen die tot storingen leiden.
- Technische problemen: Cloudservices zijn afhankelijk van een complex systeem van hardwaretechnologie, dus een fout die lang genoeg onder de radar blijft, kan leiden tot een cloudstoring.
- Softwarefouten: Glitches en bugs komen veel voor in clouddatacenters. De gebruikelijke boosdoeners achter problemen zijn bugs in de gegevensindeling, foutgerelateerde bugs, timingbugs en bugs met constante waarde.
- Netwerkproblemen: Problemen in verband met netwerkcommunicatie en externe telco-partners zijn een andere veelvoorkomende oorzaak van cloudstoringen.
- Onderhoud: Gepland onderhoud en systeemupgrades leiden soms tot een storing, hoewel eindgebruikers doorgaans van tevoren op de hoogte zijn van deze gebeurtenissen.
- Milieu-oorzaken: Gebeurtenissen zoals orkanen, branden, bliksemstormen en aardbevingen veroorzaken ook uitval van de wolken, hetzij door de faciliteit in gevaar te brengen of door het elektriciteitsnet in de regio te beschadigen.
- Meer complexe implementaties: Meer ingewikkelde implementatiemodellen (zoals hybride, gedistribueerde en multi-cloud) compliceren datacenteractiviteiten, waardoor er meer kansen op fouten ontstaan.
Wat gebeurt er als de cloud wegvalt?
In het beste geval duurt een storing in de cloud slechts enkele minuten en treft een klein aantal gebruikers of services. In het ergste geval legt een storing het bedrijf van een klant een halve dag of langer lam. Een bedrijf verliest de toegang tot alle cloudgebaseerde activa en blijft afgesloten tot de storing voorbij is.
Hoewel bedreigend, waren fouten door externe providers de oorzaak van "slechts" 7% van de ernstige storingen in 2021 . Een ernstige storing moet gepaard gaan met een (of meerdere) van de volgende zaken:
- Aanzienlijke financiële verliezen.
- Reputatieschade.
- Inbreuken op de naleving.
- Verlies van mensenlevens.
Hoewel er meer dringende zorgen zijn (zoals weergegeven in de donutgrafiek hieronder), moet u er rekening mee houden dat een gemiddelde minuut downtime $ 5.600 kost (dit cijfer per minuut gaat naar $ 9.000 voor ondernemingen). Als je niet voorbereid bent (d.w.z. je hebt geen gegevensback-ups, noodherstel, enz.), kan een cloudstoring je service tot stilstand brengen en enorme klappen veroorzaken.
Een bedrijf dat een klein deel van zijn activiteiten in de cloud houdt, is minder kwetsbaar voor storingen. Als u bijvoorbeeld alleen e-mails in de cloud host, is zelfs een storing van een dag niet catastrofaal. Je kunt het incident afwachten of apps draaien met verminderde functionaliteit, een strategie die niet werkt als je de cloud gebruikt om een IoT-platform te draaien of betalingsverwerking uit te voeren.
In sommige gevallen leidt uitval van de cloud tot permanent gegevensverlies (de hoeveelheid verloren gegevens hangt af van de frequentie van back-ups). Klanten in strikte sectoren zijn ook aansprakelijk voor juridische boetes als een storing leidt tot een datalek of lekkage, dus wees voorzichtig bij het beslissen wat u in cloudopslag bewaart.
Wat kunnen gebruikers doen?
Dit is wat bedrijven doen om de impact van cloudstoringen te beperken:
- Verwijder enkele faalpunten: Maak een back-up van elk bedrijfskritisch IT-onderdeel, hetzij in een on-site serverruimte of bij een secundaire provider. Als de cloud uitvalt, voer je een failover uit (het proces van overschakelen naar een standby-server, hardwarecomponent, netwerk, enz.) om de bedrijfscontinuïteit te waarborgen.
- Heb een noodplan: Een noodherstelplan schetst een stapsgewijze strategie voor wat het team doet in geval van een storing. Dit plan bevat instructies voor het beschermen van gegevens, het uitvoeren van een failover, het waarborgen van de bedrijfscontinuïteit en het herstellen van bewerkingen. Tijdige planning voor een cloudstoring voorkomt tijdverspilling bij het beoordelen van de beste manier van handelen tijdens downtime.
- Investeer in een SLA met hogere beschikbaarheid: Als uw bedrijfskritieke taken zich geen langdurige uitval van de cloud kunnen veroorloven, zoek dan naar een Service Level Agreement (SLA) met een hogere beschikbaarheid, zoals die welke 99,999% uptime garandeert (maximaal 5,25 minuten downtime per jaar). Deze contracten zijn duurder, maar het online houden van uw diensten wordt een grotere prioriteit voor de cloudprovider.
- Voer regelmatig gegevensback-ups uit: Een back-up zorgt ervoor dat uw team een recente versie van bestanden kan herstellen als een cloudstoring een database corrumpeert of verwijdert. Idealiter zouden back-ups automatisch moeten plaatsvinden en ergens tussen één keer per uur en één keer per dag (afhankelijk van de missiekritiek).
- Storing zo snel mogelijk detecteren: Alle aanvullende cloudbewakingsmogelijkheden die uw team instelt, helpen bij het in realtime identificeren van een storing in plaats van te wachten op de melding van de provider. Hier is een lijst met de beste tools voor cloudbewaking om de detectie van downtime te verbeteren en een tijdige failover te garanderen.
Grootste recente cloudstoringen
Cloudstoringen zijn onvermijdelijk bij het gebruik van de cloud, en zelfs de meest populaire providers (zoals Azure, AWS en Google Cloud) zijn niet immuun voor downtime. Laten we eens kijken naar enkele van de meest significante cloudstoringen in de recente geschiedenis.
Azure-storing (oktober 2021)
In oktober 2021 kreeg Microsoft Azure te maken met een storing die de services van virtuele machines zes uur . uitschakelde . Tijdens de storing waren veel gebruikers niet in staat om nieuwe VM's te implementeren of extensies bij te werken. Basishandelingen voor servicebeheer (zoals starten, maken en verwijderen) leidden ook tot fouten.
De oorzaak van de cloudstoring was het onvermogen van VM-query's om de vereiste versiegegevens van een artefact op te halen. Een post-recovery rapport onthulde dat de software-gebaseerde fout optrad toen Microsoft een van zijn VM-architecturen migreerde.
Google Cloud-storing (november 2021)
Google Cloud lag ongeveer twee uur medio november vorig jaar, met gevolgen voor onder meer:
- Home Depot.
- Snapchat.
- Etsy.
- Onenigheid.
- Spotify.
Getroffen websites vertoonden 404-fouten wanneer bezoekers ze probeerden te openen. Google meldde dat de oorzaak van de storing in de cloud een storing was in een netwerkconfiguratie die verantwoordelijk is voor taakverdeling.
AWS-storing (december 2021)
Een grote toename van verbindingsactiviteiten overspoelde netwerkapparaten in een van de vlaggenschipfaciliteiten van AWS, met gevolgen voor verschillende websites en apps. Enkele van de meest opvallende "slachtoffers" waren:
- Amazon's website.
- Primaire video.
- Netflix.
- IMDb.
- PlayStation Network.
Het datacenterprobleem veroorzaakte ernstige latentie binnen interne AWS-netwerken. Klanten-apps voelden de rimpeleffecten, ondervonden verkeersvertragingen of totale afsluitingen gedurende ongeveer zeven uur .
Twee opeenvolgende IBM-storingen (januari 2022)
Een probleem met de infrastructuur van IBM had meer dan vijf uur invloed op cloudservices in de regio van Dallas . Het interne team loste het probleem op, maar veroorzaakte per ongeluk een extra uur lang probleem met virtual private cloud. Het secundaire probleem trof gebruikers over de hele wereld, waaronder de VS, Japan, Canada en Duitsland.
AWS/Slack-storing (februari 2022)
Slack had in februari een storing in zijn AWS-cloudbronnen, waardoor het normale gebruik van het communicatieplatform vijf uur niet mogelijk was. . Meer dan 11.000 gerapporteerde gebruikers waren niet in staat:
- Berichten verzenden of ontvangen.
- Bestanden uploaden.
- Deelnemen aan kanalen.
- Start de desktop-app.
Het team van Slack heeft nooit de reden achter de uitval van de cloud gedeeld en heeft alle betrokken gebruikers verzocht de app opnieuw te starten en hun cachegeheugen te wissen na het herstel.
iCloud-storing (maart 2022)
Vijftien belangrijke Apple-services waren vier uur in maart als gevolg van een storing in de cloud, waaronder:
- App Store.
- Apple Maps.
- Apple TV.
De bedrijfs- en winkelsystemen van Apple vielen ook uit. Het bedrijf onthulde later dat de hoofdoorzaak een probleem was met betrekking tot het domeinnaamsysteem (DNS) van het bedrijf.
Google Cloud-storing (maart 2022)
Op 8 maart 2022 leden gebruikers van Google Cloud twee en een half uur met servicefouten . Spotify en Discord behoorden tot de getroffenen door de storing.
Een wijziging in de Traffic Director-code voor verwerkingsconfiguraties heeft de fout veroorzaakt. Volgens het post-recovery-rapport negeerden slechte codewijzigingen migraties van configuratiegegevensformaten, zodat het platform onbedoeld de programmering van de gebruiker verwijderde.
Atlassian storing (april 2022)
De grootste storing in Atlassian van het jaar begon op 5 april en eindigde op 18 april (hoewel sommige gebruikers op 8 april begonnen met het herstellen van services). Het bedrijf legde uit dat de storing het gevolg was van gebrekkige teamcommunicatie en een slecht gepland incidentresponsplan.
Hoewel deze storing in de cloud bijna twee weken duurde voor sommige gebruikers waren er geen meldingen van significante verliezen van klantgegevens. Gebruikers van beide vlaggenschipproducten van Atlassian, Trello en Jira, werden echter getroffen door het probleem.
Microsoft Azure-storing (juni 2022)
Op 7 juni konden Azure-klanten geen verbinding maken met resources die werden gehost in de regio VS-Oost 2 (voornamelijk Virginia). De storing duurde ongeveer twaalf uur en had geen invloed op consumenten die afhankelijk waren van zone-redundante infrastructuur. Gecompromitteerde services inbegrepen:
- Toepassingsinzichten.
- Loganalyse.
- Beheerde identiteitsservice.
- Mediadiensten.
- NetApp-bestanden.
De boosdoener was een plotselinge stroomstoring in een van de lokale datacenters, waardoor Air Handling Units (AHU's) werden uitgeschakeld.
Uitval Cloudflare (juni 2022)
In juni veroorzaakte een accidentele storing bij Cloudflare grote verstoringen die anderhalf uur duurden , het verwijderen van populaire sites zoals:
- Onenigheid.
- Shopify.
- Fitbit.
- Peloton.
De in San Francisco gevestigde leverancier legde uit dat de ongeplande downtime het gevolg was van een wijziging in de netwerkconfiguratie in 19 van zijn datacenters.
Overzie de waarde van het plannen van uitval in de cloud niet
Voorbeelden van cloudstoringen in de afgelopen jaren geven een duidelijke boodschap af:ook al is de cloud een IT-game-changer, de technologie is niet onfeilbaar . Bedrijven die om eindgebruikers en app-beschikbaarheid geven, moeten voorbereid zijn op incidentele downtime, waardoor back-up en noodherstel (BDR) een integraal onderdeel is van het gebruik van cloudgebaseerde bronnen.
Cloud computing
- Wat is transfer molding en hoe werkt het?
- Hoe (en waarom) uw openbare cloudprestaties benchmarken
- Wat is cloudbeveiliging en waarom is het vereist?
- Cloud en hoe het de IT-wereld verandert
- Agentloze versus agentgebaseerde architecturen:waarom is het belangrijk?
- Wat is een verduisterde VPN-server en hoe werkt het
- Hoe werkt Google Cloud Storage?
- Wat is een transmissie en hoe werkt het?
- Waarom en hoe een vacuümaudit uit te voeren?
- Wat is een industriële koppeling en hoe werkt het?
- Kraaninspecties:wanneer, waarom en hoe?