


Hoe fuzz-testen de beveiliging van IoT-apparaten versterken
Met de proliferatie van IoT-apparaten komen meer ingebouwde beveiligingsaanvallen. In het verleden hebben ingebedde systeemingenieurs de beveiliging op de apparaatlaag genegeerd, ondanks de vele gebieden van ingebedde apparaten die kwetsbaar zijn voor bugs. Seriële poorten, radio-interfaces en zelfs programmeer-/foutopsporingsinterfaces kunnen allemaal door hackers worden misbruikt. Fuzz-testen vormen een belangrijke locatie die beschikbaar is voor technici om zwakke punten in embedded apparaten te vinden, en zou moeten worden overwogen voor het versterken van IoT-apparaatinterfaces.
Wat is fuzz-testen?
Fuzz-testen is als de mythische miljoen apen die willekeurig typen om Shakespeare te schrijven. In de praktijk vereisen fictiewerken veel willekeurige combinaties om een eenvoudige zin te produceren, maar voor embedded systemen hoeven we slechts een paar letters van een bekende goede zin te veranderen.
Er zijn tal van commerciële en open source-tools beschikbaar voor het uitvoeren van fuzz-aanvallen. Deze tools genereren reeksen willekeurige bytes, ook wel fuzz-vectoren of aanvalsvectoren genoemd, en sturen deze naar de interface die wordt getest, waarbij ze het resulterende gedrag bijhouden dat op een bug zou kunnen duiden.
Fuzz-testen is een spel met getallen, maar we kunnen niet een oneindig aantal mogelijke inputs proberen. In plaats daarvan richten we ons op het optimaliseren van de testtijd door het maximaliseren van de snelheid van indiening van fuzz-vectoren, de effectiviteit van de fuzz-vectoren en de algoritmen voor het detecteren van fouten.
Fuzz-testconcepten
Omdat veel fuzz-testtools zijn ontworpen om pc-toepassingen te testen, is het gemakkelijker om ze aan te passen als u uw ingesloten code uitvoert als een native gecompileerde pc-toepassing. Het uitvoeren van embedded code op een pc levert een enorm prestatievoordeel op, maar heeft twee nadelen. Ten eerste reageren pc-microprocessors niet hetzelfde als embedded microcontrollers. Ten tweede moeten we elke code die hardware raakt opnieuw schrijven. In de praktijk wegen de voordelen van het draaien op een pc echter op tegen de nadelen. De echte barrière is de moeilijkheid bij het overzetten van code om native op de pc te compileren.
Hoe weten we wanneer een fuzz-vector een bug veroorzaakt? Een crash is gemakkelijk te herkennen, maar het is moeilijker om fuzz-vectoren te identificeren die een reset veroorzaken. Geheugenoverloop-bugs of verdwaalde pointer-writes (het type bugs dat het meest waardevol is voor hackers) zijn bijna niet te onderscheiden van buiten het systeem, omdat ze doorgaans niet leiden tot een crash of een reset.
Veel moderne compilers, zoals GCC en Clang, hebben een functie die geheugenopschoning wordt genoemd. Dit markeert geheugenblokken als schoon of vuil, afhankelijk van of ze in gebruik zijn, en markeert elke poging om toegang te krijgen tot vuil geheugen. Geheugenopschoning verbruikt echter flash-, RAM- en CPU-cycli, waardoor het moeilijk is om op embedded apparaten te draaien. In plaats daarvan kunnen we dus een subset code testen, een versie van het apparaat bouwen met meer bronnen of een pc gebruiken.
De effectiviteit van een test kan worden beoordeeld aan de hand van de hoeveelheid code die wordt uitgeoefend. Ook hier kunnen compilers het geheugengebruik volgen door gebruik te maken van breadcrumb-subroutine-aanroepen. De bibliotheek met codedekking houdt een tabel bij met gebruikswaarden voor elk codepad, en verhoogt deze wanneer de breadcrumb wordt uitgevoerd.
Codedekkingsnummers zijn echter lastig te interpreteren voor embedded fuzz-tests omdat veel van de code niet toegankelijk is voor de fuzz-vectoren; bijvoorbeeld een apparaatstuurprogramma voor een randapparaat dat onafhankelijk van de interface werkt. Daarom is het moeilijk om "volledige codedekking" voor embedded systemen te definiëren - misschien is slechts 20% van de embedded code toegankelijk. Codedekking verbruikt ook grote hoeveelheden flash-, RAM- en CPU-cycli en vereist gespecialiseerde hardware of een pc-doelwit om te draaien.
Bugrapportage
Wanneer de fuzz-test een vector vindt die ongewenst gedrag veroorzaakt, hebben we gedetailleerde informatie nodig. Waar is de fout opgetreden? Wat is de status van de call-stack? Wat is het specifieke type bug? Al deze informatie helpt bij het uitzoeken en uiteindelijk oplossen van de bug.
Bug-triage is cruciaal bij fuzz-testen. Nieuwe fuzz-projecten vinden vaak veel bugs en we hebben een automatische manier nodig om de ernst ervan te bepalen. Ook hebben fuzz-bugs de neiging om bugs te blokkeren, omdat ze vaak extra bugs maskeren verderop in het codepad. We hebben een snelle oplossing nodig voor problemen die zich voordoen tijdens het testen van fuzz.
Embedded clients zijn niet zo bereid om hun informatie te onthullen als pc's. Gewoonlijk zorgt een crash ervoor dat het apparaat wordt gereset en opnieuw wordt opgestart. Hoewel dit in het veld gewenst is, wist het de status van het apparaat, waardoor het moeilijk is om te achterhalen of een crash heeft plaatsgevonden, waar of waarom het is gebeurd, of welk codepad is genomen. De technicus moet een consistente reproductievector vinden en vervolgens een debugger gebruiken om het slechte gedrag op te sporen en de bug te vinden.
Bij fuzz-testen kan een test duizenden crashvectoren opleveren voor een paar bugs, waardoor de verkeerde indruk wordt gewekt van een systeem met fouten. Het is belangrijk om snel te bepalen welke vectoren met dezelfde onderliggende bug zijn geassocieerd. Voor embedded apparaten is de locatie van de crash zelf meestal uniek voor de bug en is het meestal niet vereist om de volledige call-stack-trace te vinden.
Continue fuzz-testen
Vanwege de stochastische aard van fuzz-tests, vergroot het uitvoeren van deze tests gedurende langere perioden hun kansen op het vinden van problemen. Maar geen enkel projectplan kon vertragingen opvangen van een lange testcyclus voor fuzz aan het einde van de ontwikkeling.
In de praktijk zou het fuzz-testen op zijn eigen branch beginnen na het releaseproces. Alle nieuw ontdekte bugs zouden worden opgelost in de lokale branch, zodat het testen kon doorgaan zonder dat de nieuwe bugs de ontdekking van extra bugs blokkeerden. Als onderdeel van de releasecyclus zouden bugs die zijn ontdekt bij het testen van eerdere releases, worden geëvalueerd voor opname in nieuwe releases. Ten slotte moeten fuzz-vectoren die een bug hebben ontdekt, worden toegevoegd aan de normale processen voor kwaliteitsborging om de fix te verifiëren en ervoor te zorgen dat deze bugs niet per ongeluk opnieuw in de code worden geïntroduceerd.
We zouden fuzz-tests van apparaten in verschillende scenario's moeten uitvoeren; een apparaat reageert bijvoorbeeld anders op verbindingsverzoeken als het is aangesloten op een netwerk. Het is onpraktisch om fuzz-tests uit te voeren op elk mogelijk scenario, maar we kunnen fuzz-tests opnemen voor elke waarde van mogelijke toestand. Voer bijvoorbeeld fuzz-tests uit met elk ander apparaattype terwijl andere variabelen hetzelfde blijven. Voer vervolgens verschillende waarden uit voor een andere variabele, zoals de status van de netwerkverbinding, voor één apparaattype.
Fuzz-testarchitecturen
Twee prominente fuzz-testarchitecturen zijn gericht fuzzing, waarbij fuzz-vectoren vóór de test worden gespecificeerd door een ingenieur, en dekkingsgeleide fuzz-testen, waarbij de fuzz-tool begint met een eerste set testvectoren en deze automatisch muteert op basis van hoe goed pakketten doordringen. de code.
Bovendien zal niet alle code op een pc worden uitgevoerd en kan het ontwikkelen van een pc-simulator voor een embedded applicatie onpraktisch zijn, afhankelijk van wat er wordt getest.
Hieronder vindt u een samenvatting van vier fuzz-testarchitecturen:
- Direct testen van de interface op ingebedde hardware:het normale productiebeeld draaien op het ingebedde apparaat met fuzz-pakketten die via de interface worden geïnjecteerd
- Test voor pakketinjectie (stack) - aanroepen van inkomende pakketroutines rechtstreeks zonder de interface via de ether uit te voeren
- Geregisseerd fuzzen met een simulator - met behulp van pc-gebaseerde simulatietechnieken voor het ontwikkelen en testen van embedded code
- Door dekking begeleid fuzzen met een simulator (hieronder weergegeven als Libfuzz)
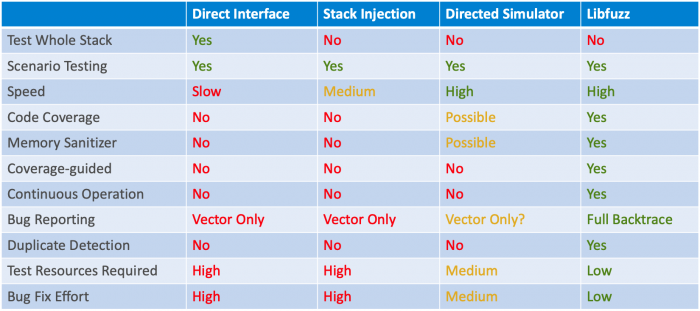
Meerdere fuzz-testers
Na het vergrendelen van een ingebed apparaat met debug-interfacevergrendeling en veilig opstarten, moeten we fuzz-testen van de interfaces van het apparaat overwegen. Veel van dezelfde tools en concepten die worden gebruikt om webservers te beveiligen, kunnen worden aangepast voor gebruik met embedded apparaten.
Gebruik het juiste gereedschap voor de klus. Dekking-geleide fuzzing is noodzakelijk voor continue fuzz-testen, maar als uw code alleen wordt uitgevoerd op embedded hardware, kunnen gerichte fuzzers een goede keuze zijn om een zekere mate van fuzz-testdekking te bieden.
Ten slotte moet u in zoveel mogelijk scenario's meerdere fuzz-testers gebruiken, omdat elk het apparaat iets anders zal testen, waardoor de dekking en dus de veiligheid van uw embedded apparaat wordt gemaximaliseerd.
>> Dit artikel is oorspronkelijk gepubliceerd op onze zustersite, EDN.
Internet of Things-technologie
- Hoe 5G het industriële IoT zal versnellen
- Hoe IoT de beveiligingsrisico's in olie en gas aanpakt
- De weg naar industriële IoT-beveiliging
- Hoe IoT werkplekken verbindt
- Het faciliteren van IoT-provisioning op schaal
- IoT-beveiliging – wie is verantwoordelijk?
- IoT-beveiliging – een belemmering voor implementatie?
- Hoe tweaks in de toeleveringsketen van IoT beveiligingslacunes kunnen dichten
- Internet of Warnings:hoe slimme technologie de beveiliging van uw bedrijf kan bedreigen
- IoT-beveiliging:hoe digitale transformatie te stimuleren en risico's te minimaliseren
- NIST publiceert concept-beveiligingsaanbevelingen voor IoT-fabrikanten