


Wat is Hadoop? Hadoop Big Data-verwerking
De evolutie van big data heeft nieuwe uitdagingen opgeleverd die nieuwe oplossingen nodig hadden. Als nooit tevoren in de geschiedenis moeten servers enorme hoeveelheden gegevens in realtime verwerken, sorteren en opslaan.
Deze uitdaging heeft geleid tot de opkomst van nieuwe platforms, zoals Apache Hadoop, die met gemak grote datasets aankunnen.
In dit artikel leer je wat Hadoop is, wat de belangrijkste componenten zijn en hoe Apache Hadoop helpt bij het verwerken van big data.
Wat is Hadoop?
De Apache Hadoop-softwarebibliotheek is een open source-framework waarmee u big data efficiënt kunt beheren en verwerken in een gedistribueerde computeromgeving.
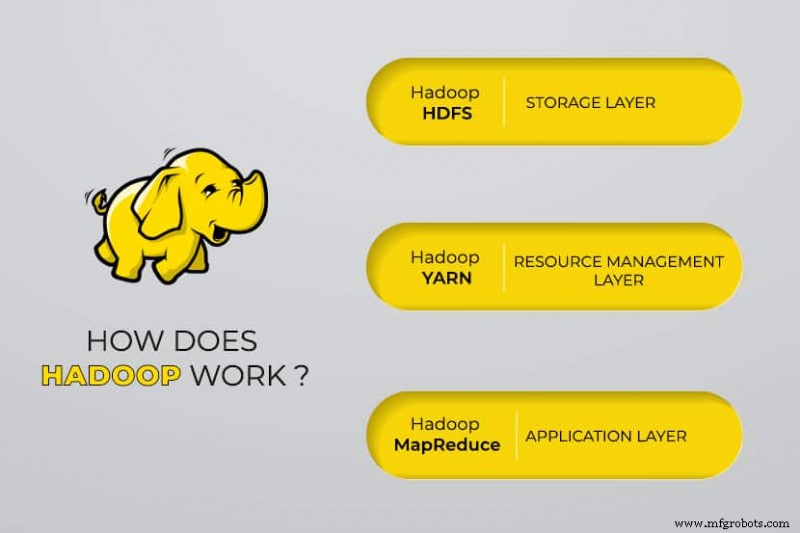
Apache Hadoop bestaat uit vier hoofdmodules :
Hadoop gedistribueerd bestandssysteem (HDFS)
Gegevens bevinden zich in het gedistribueerde bestandssysteem van Hadoop, dat vergelijkbaar is met dat van een lokaal bestandssysteem op een typische computer. HDFS biedt een betere gegevensdoorvoer in vergelijking met traditionele bestandssystemen.
Bovendien biedt HDFS uitstekende schaalbaarheid. U kunt eenvoudig en op basishardware van een enkele machine naar duizenden schalen.
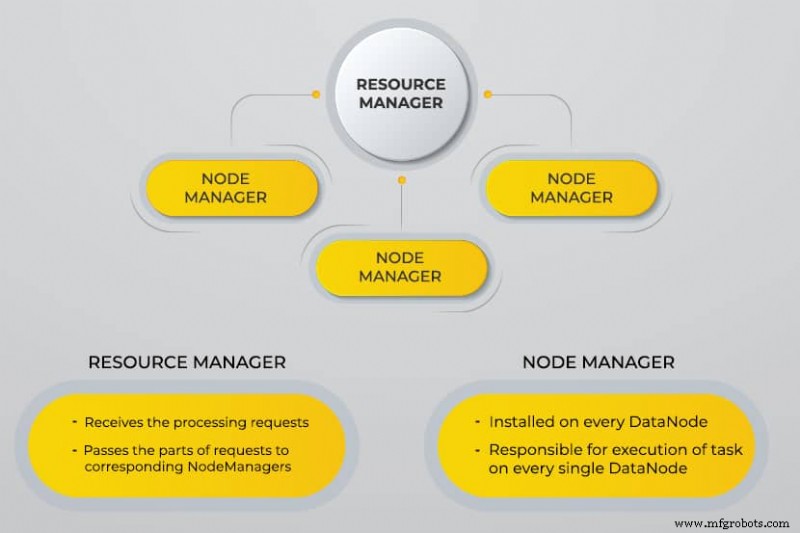
Nog een Resource Negotiator (YARN)
YARN faciliteert geplande taken, hele beheer en monitoring van clusterknooppunten en andere bronnen.
MapReduce
De Hadoop MapReduce-module helpt programma's om parallelle gegevensberekeningen uit te voeren. De kaarttaak van MapReduce zet de invoergegevens om in sleutel-waardeparen. Verminder taken die de input verbruiken, aggregeren en het resultaat opleveren.
Hadoop Common
Hadoop Common gebruikt standaard Java-bibliotheken in elke module.
Waarom is Hadoop ontwikkeld?
Het World Wide Web is de afgelopen tien jaar exponentieel gegroeid en bestaat nu uit miljarden pagina's. Het online zoeken naar informatie werd moeilijk vanwege de grote hoeveelheid. Deze gegevens werden big data en bestaan uit twee hoofdproblemen:
- Moeite om al deze gegevens op een efficiënte en gemakkelijk te vinden manier op te slaan
- Moeilijkheden bij het verwerken van de opgeslagen gegevens
Ontwikkelaars hebben aan veel open-sourceprojecten gewerkt om zoekresultaten op het web sneller en efficiënter te retourneren door de bovenstaande problemen aan te pakken. Hun oplossing was om gegevens en berekeningen over een cluster van servers te distribueren om gelijktijdige verwerking te bereiken.
Uiteindelijk werd Hadoop een oplossing voor deze problemen en bracht het vele andere voordelen met zich mee, waaronder de verlaging van de kosten voor serverimplementatie.
Hoe werkt Hadoop Big Data-verwerking?
Met Hadoop benutten we de opslag- en verwerkingscapaciteit van clusters en implementeren we gedistribueerde verwerking voor big data. In wezen biedt Hadoop een basis waarop u andere applicaties kunt bouwen om big data te verwerken.
Applicaties die gegevens in verschillende formaten verzamelen, slaan deze op in het Hadoop-cluster via de API van Hadoop, die verbinding maakt met de NameNode. De NameNode legt de structuur van de bestandsdirectory vast en de plaatsing van "chunks" voor elk gemaakt bestand. Hadoop repliceert deze chunks over DataNodes voor parallelle verwerking.
MapReduce voert gegevensquery's uit. Het brengt alle DataNodes in kaart en vermindert de taken met betrekking tot de gegevens in HDFS. De naam "MapReduce" zelf beschrijft wat het doet. Kaarttaken worden uitgevoerd op elk knooppunt voor de aangeleverde invoerbestanden, terwijl verkleiners worden uitgevoerd om de gegevens te koppelen en de uiteindelijke uitvoer te organiseren.
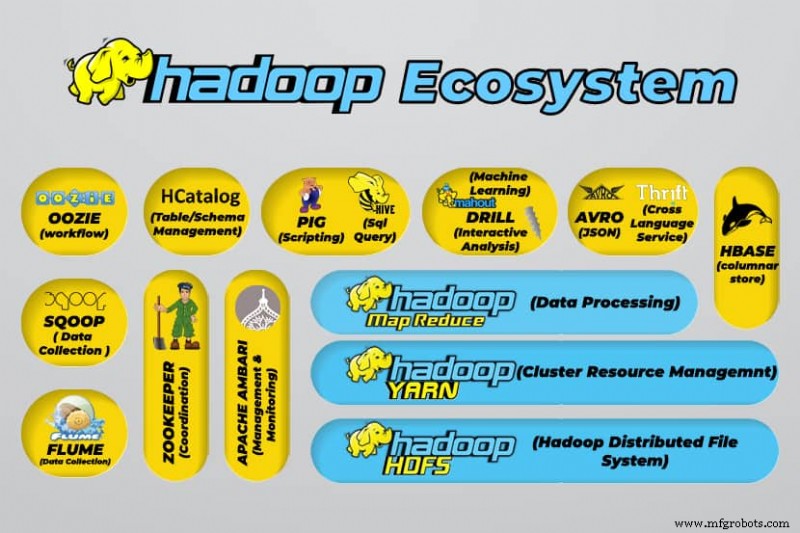
Hadoop Big Data-tools
Het ecosysteem van Hadoop ondersteunt een verscheidenheid aan open-source big data-tools. Deze tools vormen een aanvulling op de kerncomponenten van Hadoop en verbeteren het vermogen om big data te verwerken.
De handigste tools voor het verwerken van big data zijn:
- Apache Hive
Apache Hive is een datawarehouse voor het verwerken van grote hoeveelheden gegevens die zijn opgeslagen in het bestandssysteem van Hadoop.
- Apache Dierenverzorger
Apache Zookeeper automatiseert failovers en vermindert de impact van een mislukte NameNode.
- Apache HBase
Apache HBase is een open-source niet-relatiedatabase voor Hadoop.
- Apache Flume
Apache Flume is een gedistribueerde service voor het streamen van grote hoeveelheden loggegevens.
- Apache Sqoop
Apache Sqoop is een opdrachtregelprogramma voor het migreren van gegevens tussen Hadoop en relationele databases.
- Apache Varken
Apache Pig is het ontwikkelplatform van Apache voor het ontwikkelen van jobs die op Hadoop draaien. De gebruikte softwaretaal is Varkenslatijn.
- Apache Oozie
Apache Oozie is een planningssysteem dat het beheer van Hadoop-taken vergemakkelijkt.
- Apache HCatalog
Apache HCatalog is een opslag- en tabelbeheertool voor het sorteren van gegevens uit verschillende gegevensverwerkingstools.
Voordelen van Hadoop
Hadoop is een robuuste oplossing voor de verwerking van big data en een essentieel hulpmiddel voor bedrijven die met big data te maken hebben.
De belangrijkste kenmerken en voordelen van Hadoop worden hieronder beschreven:
- Snelle opslag en verwerking van grote hoeveelheden gegevens
Met de komst van sociale media en het Internet of Things (IoT) is de hoeveelheid data die moet worden opgeslagen enorm toegenomen. Opslag en verwerking van deze datasets zijn van cruciaal belang voor de bedrijven die ze bezitten. - Flexibiliteit
Dankzij de flexibiliteit van Hadoop kunt u ongestructureerde gegevenstypen opslaan, zoals tekst, symbolen, afbeeldingen en video's. In traditionele relationele databases zoals RDBMS moet u de gegevens verwerken voordat u ze opslaat. Met Hadoop is het voorbewerken van gegevens echter niet nodig, omdat u gegevens kunt opslaan zoals ze zijn en kunt beslissen hoe u deze later wilt verwerken. Met andere woorden, het gedraagt zich als een NoSQL-database. - Verwerkingskracht
Hadoop verwerkt big data via een gedistribueerd computermodel. Het efficiënte gebruik van verwerkingskracht maakt het zowel snel als efficiënt. - Verlaagde kosten
Veel teams verlieten hun projecten voor de komst van frameworks zoals Hadoop, vanwege de hoge kosten die ze maakten. Hadoop is een open-source framework, het is gratis te gebruiken en het gebruikt goedkope standaardhardware om gegevens op te slaan. - Schaalbaarheid
Met Hadoop kunt u uw systeem snel schalen zonder veel administratie, gewoon door het aantal knooppunten in een cluster te wijzigen. - Fouttolerantie
Een van de vele voordelen van het gebruik van een gedistribueerd datamodel is het vermogen om fouten te tolereren. Hadoop is niet afhankelijk van hardware om de beschikbaarheid te behouden. Als een apparaat uitvalt, stuurt het systeem de taak automatisch door naar een ander apparaat. Fouttolerantie is mogelijk omdat redundante gegevens worden gehandhaafd door meerdere kopieën van gegevens in het cluster op te slaan. Met andere woorden, hoge beschikbaarheid wordt gehandhaafd op de softwarelaag.
De drie belangrijkste gebruiksscenario's
Big data verwerken
We raden Hadoop aan voor grote hoeveelheden gegevens, meestal in het bereik van petabytes of meer. Het is beter geschikt voor enorme hoeveelheden gegevens die een enorme verwerkingskracht vereisen. Hadoop is misschien niet de beste optie voor een organisatie die kleinere hoeveelheden gegevens verwerkt, in het bereik van enkele honderden gigabytes.
Een diverse set gegevens opslaan
Een van de vele voordelen van het gebruik van Hadoop is dat het flexibel is en verschillende datatypes ondersteunt. Of gegevens nu uit tekst, afbeeldingen of videogegevens bestaan, Hadoop kan ze efficiënt opslaan. Organisaties kunnen kiezen hoe ze gegevens verwerken, afhankelijk van hun behoefte. Hadoop heeft de kenmerken van een data lake omdat het flexibiliteit biedt over de opgeslagen data.
Parallelle gegevensverwerking
Het MapReduce-algoritme dat in Hadoop wordt gebruikt, orkestreert parallelle verwerking van opgeslagen gegevens, wat betekent dat u meerdere taken tegelijkertijd kunt uitvoeren. Gezamenlijke operaties zijn echter niet toegestaan, omdat dit de standaardmethodologie in Hadoop verwart. Het bevat parallellisme zolang de gegevens onafhankelijk van elkaar zijn.
Waar wordt Hadoop in de echte wereld voor gebruikt
Bedrijven van over de hele wereld gebruiken Hadoop big data-verwerkingssystemen. Een paar van de vele praktische toepassingen van Hadoop worden hieronder opgesomd:
- Klantvereisten begrijpen
Tegenwoordig heeft Hadoop bewezen zeer nuttig te zijn bij het begrijpen van de eisen van de klant. Grote bedrijven in de financiële sector en sociale media gebruiken deze technologie om de behoeften van klanten te begrijpen door big data met betrekking tot hun activiteiten te analyseren.
Bedrijven gebruiken die gegevens om klanten gepersonaliseerde aanbiedingen te doen. Je hebt dit misschien ervaren door advertenties die op sociale media en e-commercesites zijn getoond op basis van onze interesses en internetactiviteit. - Bedrijfsprocessen optimaliseren
Hadoop helpt de prestaties van bedrijven te optimaliseren door hun transactie- en klantgegevens beter te analyseren. Trendanalyse en voorspellende analyse kunnen bedrijven helpen hun producten en voorraden aan te passen om de verkoop te verhogen. Een dergelijke analyse zal een betere besluitvorming vergemakkelijken en tot hogere winsten leiden.
Bovendien gebruiken bedrijven Hadoop om hun werkomgeving te verbeteren door het gedrag van werknemers te monitoren door gegevens te verzamelen over hun interacties met elkaar. - De gezondheidszorg verbeteren
Instellingen in de medische industrie kunnen Hadoop gebruiken om de enorme hoeveelheid gegevens over gezondheidsproblemen en medische behandelingsresultaten te monitoren. Onderzoekers kunnen deze gegevens analyseren om gezondheidsproblemen te identificeren, medicatie te voorspellen en te beslissen over behandelplannen. Dergelijke verbeteringen zullen landen in staat stellen hun gezondheidsdiensten snel te verbeteren. - Financiële handel
Hadoop beschikt over een geavanceerd algoritme om marktgegevens te scannen met vooraf gedefinieerde instellingen om handelsmogelijkheden en seizoenstrends te identificeren. Financiële bedrijven kunnen de meeste van deze operaties automatiseren door de robuuste mogelijkheden van Hadoop. - Hadoop gebruiken voor IoT
IoT-apparaten zijn afhankelijk van de beschikbaarheid van gegevens om efficiënt te kunnen functioneren. Fabrikanten en uitvinders gebruiken Hadoop als datawarehouse voor miljarden transacties. Aangezien IoT een datastreamingconcept is, is Hadoop een geschikte en praktische oplossing voor het beheren van de enorme hoeveelheden data die het omvat.
Hadoop wordt continu bijgewerkt, waardoor we de instructies die worden gebruikt met IoT-platforms kunnen verbeteren.
Andere praktische toepassingen van Hadoop zijn onder meer het verbeteren van de apparaatprestaties, het verbeteren van persoonlijke kwantificering en prestatie-optimalisatie, het verbeteren van sport en wetenschappelijk onderzoek.
Wat zijn de uitdagingen van het gebruik van Hadoop?
Elke toepassing heeft zowel voordelen als uitdagingen. Hadoop introduceert ook verschillende uitdagingen:
- Het MapReduce-algoritme is niet altijd de oplossing
Het MapReduce-algoritme ondersteunt niet alle scenario's. Het is geschikt voor eenvoudige informatieverzoeken en problemen die worden opgedeeld in onafhankelijke eenheden, maar niet voor iteratieve taken.
MapReduce is inefficiënt voor geavanceerd analytisch computergebruik, aangezien iteratieve algoritmen intensieve onderlinge communicatie vereisen, en het creëert meerdere bestanden in de MapReduce-fase. - Volledig ontwikkeld gegevensbeheer
Hadoop biedt geen uitgebreide tools voor gegevensbeheer, metagegevens en gegevensbeheer. Bovendien mist het de tools die nodig zijn voor het standaardiseren van gegevens en het bepalen van de kwaliteit. - Talentkloof
Vanwege de steile leercurve van Hadoop kan het moeilijk zijn om programmeurs op instapniveau te vinden met Java-vaardigheden die voldoende zijn om productief te zijn met MapReduce. Deze intensiteit is de belangrijkste reden dat de providers geïnteresseerd zijn in het toevoegen van relationele (SQL) databasetechnologie bovenop Hadoop, omdat het veel gemakkelijker is om programmeurs met gedegen kennis van SQL te vinden in plaats van MapReduce-vaardigheden.
Hadoop-beheer is zowel een kunst als een wetenschap, waarvoor een lage kennis van besturingssystemen, hardware en Hadoop-kernelinstellingen vereist is. - Gegevensbeveiliging
Het Kerberos-authenticatieprotocol is een belangrijke stap in het veilig maken van Hadoop-omgevingen. Gegevensbeveiliging is van cruciaal belang om big data-systemen te beschermen tegen gefragmenteerde gegevensbeveiligingsproblemen.
Conclusie
Hadoop is zeer effectief in het aanpakken van big data-verwerking wanneer het effectief wordt geïmplementeerd met de stappen die nodig zijn om de uitdagingen te overwinnen. Het is een veelzijdige tool voor bedrijven die te maken hebben met grote hoeveelheden data.
Een van de belangrijkste voordelen is dat het op elke hardware kan draaien en dat een Hadoop-cluster over duizenden servers kan worden gedistribueerd. Een dergelijke flexibiliteit is vooral belangrijk in infrastructuur-als-code-omgevingen.
Cloud computing
- Big data en cloud computing:een perfecte combinatie
- Wat is cloudbeveiliging en waarom is het vereist?
- Wat is de relatie tussen big data en cloud computing?
- Gebruik van big data en cloud computing in het bedrijfsleven
- Wat te verwachten van IoT-platforms in 2018
- Voorspellend onderhoud – Wat u moet weten
- Wat is DDR5 RAM precies? Functies en beschikbaarheid
- Wat is IIoT?
- Big data versus kunstmatige intelligentie
- Big data bouwen uit kleine data
- Big Data hervormt de nutssector