


Python XML Parser-zelfstudie:voorbeeld van xml-bestand lezen (Minidom, ElementTree)
Wat is XML?
XML staat voor eXtensible Markup Language. Het is ontworpen om kleine tot middelgrote hoeveelheden gegevens op te slaan en te transporteren en wordt veel gebruikt voor het delen van gestructureerde informatie.
Met Python kunt u XML-documenten ontleden en wijzigen. Om het XML-document te ontleden, moet u het volledige XML-document in het geheugen hebben. In deze zelfstudie zullen we zien hoe we de XML-minidomklasse in Python kunnen gebruiken om het XML-bestand te laden en te ontleden.
In deze tutorial zullen we leren-
- XML ontleden met minidom
- XML-knooppunt maken
- XML ontleden met ElementTree
XML ontleden met minidom
We hebben een voorbeeld XML-bestand gemaakt dat we gaan ontleden.
Stap 1) In het bestand kunnen we voornaam, achternaam, thuis en het expertisegebied zien (SQL, Python, Testing en Business)
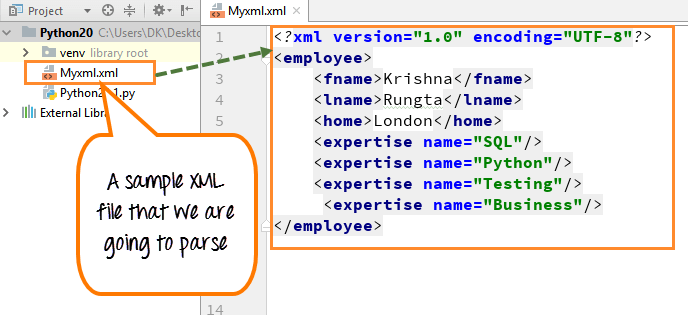
Stap 2) Zodra we het document hebben geparseerd, printen we de “node name” van de hoofdmap van het document en de “firstchild tagname” . Tagnaam en knooppuntnaam zijn de standaardeigenschappen van het XML-bestand.

- Importeer de module xml.dom.minidom en declareer het bestand dat moet worden geparseerd (myxml.xml)
- Dit bestand bevat wat basisinformatie over de werknemer, zoals voornaam, achternaam, thuis, expertise, enz.
- We gebruiken de ontledingsfunctie op de XML-minidom om het XML-bestand te laden en te ontleden
- We hebben variabele doc en doc krijgt het resultaat van de ontledingsfunctie
- We willen de knooppuntnaam en onderliggende tagnaam uit het bestand afdrukken, dus we declareren het in de afdrukfunctie
- Voer de code uit - Het drukt de knooppuntnaam (#document) af uit het XML-bestand en de eerste onderliggende tagnaam (werknemer) uit het XML-bestand
Opmerking :
Knooppuntnaam en onderliggende tagnaam zijn de standaardnamen of eigenschappen van een XML-domein. Voor het geval u niet bekend bent met dit soort naamgevingsconventies.
Stap 3) We kunnen ook de lijst met XML-tags uit het XML-document oproepen en afdrukken. Hier hebben we de set vaardigheden uitgeprint, zoals SQL, Python, Testen en Business.
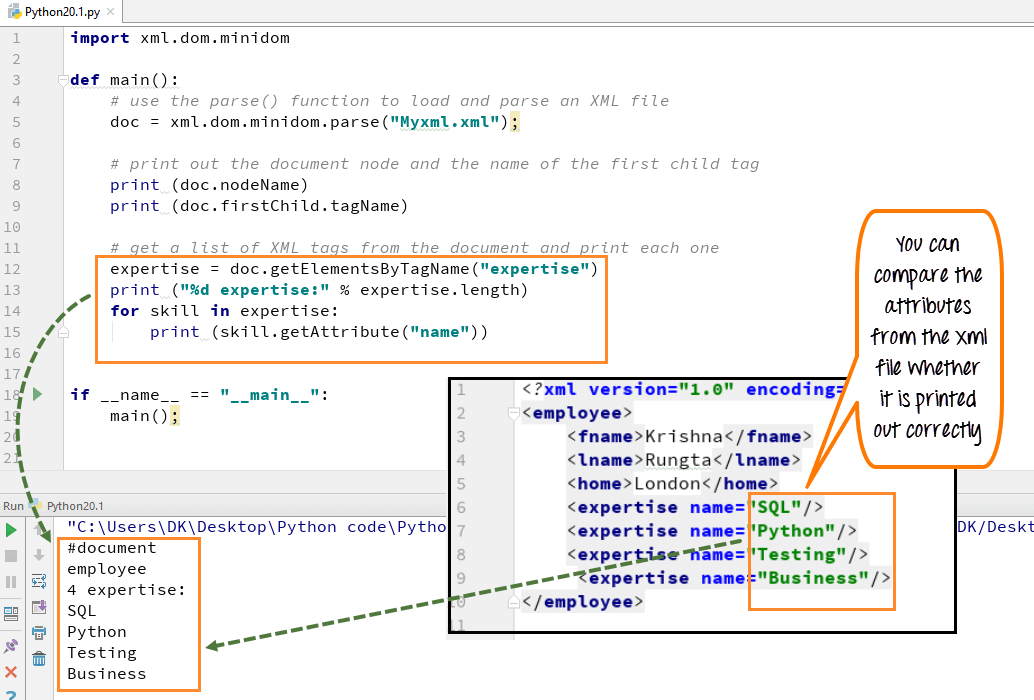
- Declareer de variabele expertise, waaruit we alle expertisenamen gaan halen die de werknemer heeft
- Gebruik de dom standaardfunctie genaamd “getElementsByTagName”
- Dit krijgt alle elementen met de naam vaardigheid
- Declareer lus over elk van de vaardigheidstags
- Voer de code uit - Het geeft een lijst met vier vaardigheden
XML-knooppunt maken
We kunnen een nieuw attribuut maken door de functie "createElement" te gebruiken en dit nieuwe attribuut of deze nieuwe tag aan de bestaande XML-tags toe te voegen. We hebben een nieuwe tag "BigData" toegevoegd aan ons XML-bestand.
- Je moet coderen om het nieuwe attribuut (BigData) toe te voegen aan de bestaande XML-tag
- Vervolgens moet u de XML-tag afdrukken met nieuwe attributen toegevoegd aan de bestaande XML-tag
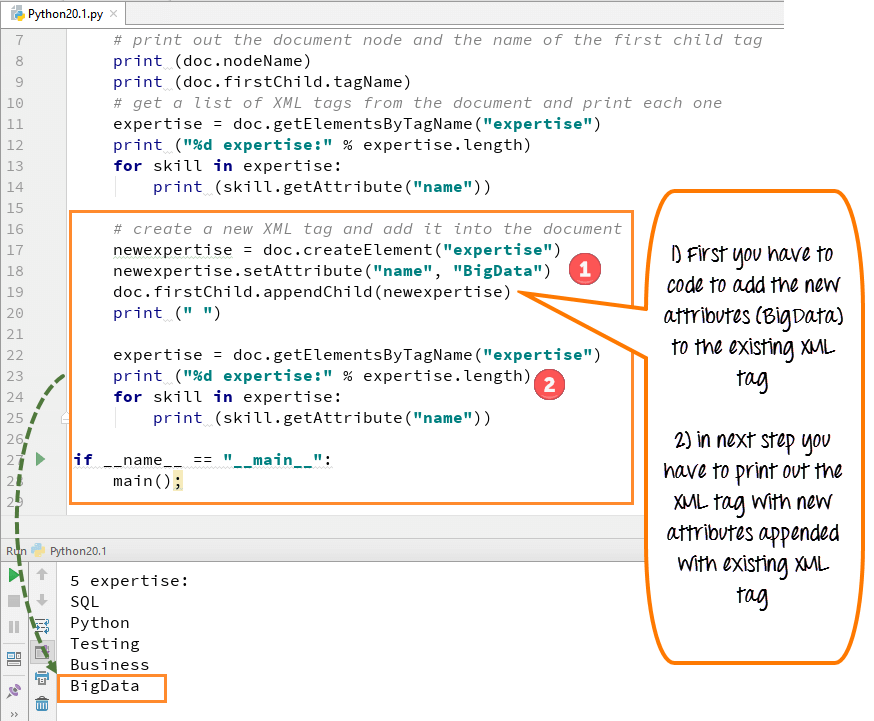
- Om een nieuwe XML toe te voegen en aan het document toe te voegen, gebruiken we de code "doc.create elements"
- Met deze code wordt een nieuwe vaardigheidstag gemaakt voor ons nieuwe kenmerk 'Big-data'
- Voeg deze vaardigheidstag toe aan het document eerste kind (werknemer)
- Voer de code uit - de nieuwe tag "big data" verschijnt bij de andere lijst met expertise
XML-parservoorbeeld
Python 2 voorbeeld
import xml.dom.minidom
def main():
# use the parse() function to load and parse an XML file
doc = xml.dom.minidom.parse("Myxml.xml");
# print out the document node and the name of the first child tag
print doc.nodeName
print doc.firstChild.tagName
# get a list of XML tags from the document and print each one
expertise = doc.getElementsByTagName("expertise")
print "%d expertise:" % expertise.length
for skill in expertise:
print skill.getAttribute("name")
# create a new XML tag and add it into the document
newexpertise = doc.createElement("expertise")
newexpertise.setAttribute("name", "BigData")
doc.firstChild.appendChild(newexpertise)
print " "
expertise = doc.getElementsByTagName("expertise")
print "%d expertise:" % expertise.length
for skill in expertise:
print skill.getAttribute("name")
if name == "__main__":
main(); Python 3 voorbeeld
import xml.dom.minidom
def main():
# use the parse() function to load and parse an XML file
doc = xml.dom.minidom.parse("Myxml.xml");
# print out the document node and the name of the first child tag
print (doc.nodeName)
print (doc.firstChild.tagName)
# get a list of XML tags from the document and print each one
expertise = doc.getElementsByTagName("expertise")
print ("%d expertise:" % expertise.length)
for skill in expertise:
print (skill.getAttribute("name"))
# create a new XML tag and add it into the document
newexpertise = doc.createElement("expertise")
newexpertise.setAttribute("name", "BigData")
doc.firstChild.appendChild(newexpertise)
print (" ")
expertise = doc.getElementsByTagName("expertise")
print ("%d expertise:" % expertise.length)
for skill in expertise:
print (skill.getAttribute("name"))
if __name__ == "__main__":
main(); XML ontleden met ElementTree
ElementTree is een API voor het manipuleren van XML. ElementTree is de gemakkelijke manier om XML-bestanden te verwerken.
We gebruiken het volgende XML-document als voorbeeldgegevens:
<data>
<items>
<item name="expertise1">SQL</item>
<item name="expertise2">Python</item>
</items>
</data>
XML lezen met ElementTree:
we moeten eerst de module xml.etree.ElementTree importeren.
import xml.etree.ElementTree as ET
Laten we nu het root-element ophalen:
root = tree.getroot()
Hierna volgt de volledige code voor het lezen van bovenstaande XML-gegevens
import xml.etree.ElementTree as ET
tree = ET.parse('items.xml')
root = tree.getroot()
# all items data
print('Expertise Data:')
for elem in root:
for subelem in elem:
print(subelem.text)
uitvoer:
Expertise Data: SQL Python
Samenvatting:
Met Python kunt u het hele XML-document in één keer ontleden en niet slechts één regel tegelijk. Om het XML-document te ontleden, moet u het hele document in het geheugen hebben.
- XML-document ontleden
- Xml.dom.minidom importeren
- Gebruik de functie "parse" om het document te ontleden ( doc=xml.dom.minidom.parse (bestandsnaam);
- Roep de lijst met XML-tags uit het XML-document op met code (=doc.getElementsByTagName(“naam van xml-tags”)
- Nieuw attribuut maken en toevoegen in XML-document
- Gebruik functie “createElement”
Python
- Python-bestand I/O
- Java BufferedReader:hoe een bestand in Java te lezen met voorbeeld
- Python String strip() Functie met VOORBEELD
- Python-tekenreekslengte | len() methode Voorbeeld
- Opbrengst in Python-zelfstudie:voorbeeld van generator en rendement versus rendement
- Python-teller in verzamelingen met voorbeeld
- Enumerate() Functie in Python:Loop, Tuple, String (voorbeeld)
- Python controleren of bestand bestaat | Hoe te controleren of er een directory bestaat in Python
- Python JSON:coderen (dumps), decoderen (laden) &JSON-bestand lezen
- Python Lijst index() met Voorbeeld
- Python - Bestanden I/O