


Compilers in de buitenaardse wereld van functionele veiligheid
Sectoroverschrijdend stelt de wereld van functionele veiligheid nieuwe eisen aan ontwikkelaars. Functioneel veilige code moet defensieve code bevatten ter verdediging tegen onverwachte gebeurtenissen die het gevolg kunnen zijn van verschillende oorzaken. Geheugencorruptie als gevolg van codeerfouten of kosmische straling kan bijvoorbeeld leiden tot de uitvoering van codepaden die volgens de logica van de code "onmogelijk" zijn. Talen op hoog niveau, met name C en C++, bevatten een verrassend aantal functies waarvan het gedrag niet wordt voorgeschreven door de taalspecificatie waaraan de code voldoet. Dit ongedefinieerde gedrag kan leiden tot onverwachte en potentieel rampzalige resultaten die onaanvaardbaar zouden zijn in een functioneel veilige toepassing. Om deze redenen vereisen standaarden dat defensieve codering wordt toegepast, dat die code testbaar is, dat het mogelijk is om voldoende codedekking te verzamelen en dat applicatiecode herleidbaar is tot vereisten om ervoor te zorgen dat het systeem ze volledig en uniek implementeert.
Code moet ook een hoge mate van codedekking bereiken, en in sommige sectoren, met name de automobielsector, is het gebruikelijk dat het ontwerp geavanceerde externe diagnose-, kalibratie- en ontwikkelingstools vereist. Het probleem dat zich voordoet, is dat praktijken zoals defensieve codering en externe gegevenstoegang geen deel uitmaken van een wereld die compilers herkennen. Noch C noch C++ houden bijvoorbeeld rekening met geheugenbeschadiging, dus tenzij code die is ontworpen om ertegen te beschermen toegankelijk is als er geen dergelijke corruptie is, kan deze eenvoudig worden genegeerd wanneer de code wordt geoptimaliseerd. Daarom moet defensieve code syntactisch en semantisch bereikbaar zijn als deze niet "weggeoptimaliseerd" kan worden.
Ook ongedefinieerd gedrag kan voor verrassingen zorgen. Het is gemakkelijk om te suggereren dat ze gewoon moeten worden vermeden, maar het is vaak moeilijk om ze te identificeren. Waar ze bestaan, kan er geen garantie zijn dat het gedrag van de gecompileerde uitvoerbare code overeenkomt met de bedoelingen van de ontwikkelaars. De "achterdeur"-toegang tot gegevens die door foutopsporingstools worden gebruikt, vertegenwoordigt nog een andere situatie waar de taal geen rekening mee houdt, en die dus onverwachte gevolgen kan hebben.
Compileroptimalisatie kan een grote impact hebben op al deze gebieden, omdat geen van deze deel uitmaakt van de taak van compilerleveranciers. Optimalisatie kan ertoe leiden dat ogenschijnlijk degelijke defensieve code wordt geëlimineerd waar deze wordt geassocieerd met "onhaalbaarheid" - dat wil zeggen, waar deze bestaat op paden die niet kunnen worden getest en geverifieerd door een reeks mogelijke invoerwaarden. Nog verontrustender is dat defensieve code die tijdens het testen van eenheden aanwezig is, mogelijk wordt geëlimineerd wanneer het uitvoerbare bestand van het systeem wordt geconstrueerd. Alleen omdat dekking van defensieve code is bereikt tijdens de unittest, garandeert dit niet dat deze aanwezig is in het voltooide systeem.
In dit vreemde land van functionele veiligheid is de compiler misschien niet in zijn element. Daarom vertegenwoordigt objectcodeverificatie (OCV) de beste werkwijze voor elk systeem waarvoor ernstige gevolgen verbonden zijn aan falen - en inderdaad voor elk systeem waar alleen de beste werkwijze goed genoeg is.
Voor en na compilatie
Verificatie- en validatiepraktijken die worden verdedigd door functionele veiligheids-, beveiligings- en coderingsnormen zoals IEC 61508, ISO 26262, IEC 62304, MISRA C en C++ leggen veel nadruk op het laten zien hoeveel van de applicatiebroncode wordt gebruikt tijdens op vereisten gebaseerde tests.
De ervaring heeft ons geleerd dat als is aangetoond dat code correct werkt, de kans op mislukking in het veld aanzienlijk lager is. En toch, omdat de focus van deze lovenswaardige onderneming ligt op de broncode op hoog niveau (ongeacht de taal), stelt een dergelijke benadering veel vertrouwen in het vermogen van de compiler om objectcode te maken die precies reproduceert wat de ontwikkelaars bedoeld. In de meest kritische toepassingen kan die impliciete veronderstelling niet worden gerechtvaardigd.
Het is onvermijdelijk dat de controle en gegevensstroom van objectcode geen exacte spiegel is van de broncode waarvan deze is afgeleid, en dus bewijzen dat alle broncodepaden betrouwbaar kunnen worden uitgeoefend, bewijst niet hetzelfde van de objectcode . Aangezien er een 1:1-relatie is tussen objectcode en assembler, is een vergelijking tussen bron- en assemblagecode veelzeggend. Bekijk het voorbeeld in Figuur 1, waar de assembler-code aan de rechterkant is gegenereerd op basis van de broncode aan de linkerkant (met een TI-compiler waarbij optimalisatie is uitgeschakeld).

Figuur 1:De assembler-code aan de rechterkant is gegenereerd op basis van de broncode aan de linkerkant, en toont de veelzeggende vergelijking tussen bron- en assemblagecode. (Bron:LDRA)
Zoals later geïllustreerd, wanneer deze broncode wordt gecompileerd, is het stroomdiagram voor de resulterende assemblercode heel anders dan die voor de bron, omdat de regels die worden gevolgd door C- of C++-compilers hen in staat stellen de code op elke gewenste manier aan te passen, op voorwaarde dat de binaire gedraagt zich "alsof het hetzelfde is."
In de meeste gevallen is dat principe volkomen acceptabel, maar er zijn afwijkingen. Compiler-optimalisaties zijn in feite wiskundige transformaties die worden toegepast op een interne representatie van de code. Deze transformaties gaan "fout" als aannames niet kloppen - zoals vaak het geval is wanneer de codebase bijvoorbeeld ongedefinieerd gedrag bevat.
Alleen DO-178C, gebruikt in de lucht- en ruimtevaartindustrie, legt enige nadruk op de mogelijkheid van gevaarlijke inconsistenties tussen de bedoeling van de ontwikkelaar en het uitvoerbare gedrag - en zelfs dan is het niet moeilijk om voorstanders te vinden van tijdelijke oplossingen met duidelijk potentieel om die inconsistenties onopgemerkt te laten. Hoewel dergelijke benaderingen worden verontschuldigd, blijft het een feit dat de verschillen tussen bron- en objectcode verwoestende gevolgen kunnen hebben in elke kritieke toepassing.
Intentie van ontwikkelaar versus uitvoerbaar gedrag
Ondanks de duidelijke verschillen tussen bron- en objectcodestroom, zijn ze niet de eerste zorg. Compilers zijn over het algemeen zeer betrouwbare toepassingen, en hoewel er fouten kunnen zijn zoals in elke andere software, zal de implementatie van een compiler over het algemeen voldoen aan de ontwerpvereisten. Het probleem is dat die ontwerpvereisten niet altijd de behoeften van een functioneel veilig systeem weerspiegelen.
Kortom, van een compiler kan worden aangenomen dat deze functioneel trouw is aan de doelstellingen van zijn makers. Maar dat is misschien niet helemaal wat gewenst of verwacht wordt, zoals geïllustreerd in figuur 2 hieronder met een voorbeeld dat het resultaat is van compilatie met de CLANG-compiler.

Afbeelding 2 toont een compilatie met de CLANG-compiler (Bron:LDRA)
Het is duidelijk dat de defensieve oproep naar de 'error'-functie niet is uitgedrukt in de assembler-code.
Het object 'state' wordt alleen gewijzigd wanneer het is geïnitialiseerd en binnen de gevallen 'S0' en 'S1', en dus kan de compiler redeneren dat de enige waarden die aan 'state' worden gegeven 'S0' en 'S1' zijn. concludeert dat de 'default' niet nodig is omdat 'state' nooit andere waarden zal bevatten, ervan uitgaande dat er geen corruptie is - en inderdaad, de compiler maakt precies die veronderstelling.
De compiler heeft ook besloten dat, omdat de waarden van de werkelijke objecten (13 en 23) niet in een numerieke context worden gebruikt, het gewoon de waarden 0 en 1 zal gebruiken om tussen statussen te schakelen en vervolgens een exclusieve "of" te gebruiken om bij te werken de staatswaarde. Het binaire bestand voldoet aan de "alsof"-verplichting en de code is snel en compact. Binnen zijn referentiekader heeft de compiler goed werk geleverd.
Dit gedrag heeft implicaties voor "kalibratie"-tools die het linker-geheugenkaartbestand gebruiken om indirect toegang te krijgen tot objecten, en voor directe geheugentoegang via een debugger. Nogmaals, dergelijke overwegingen maken geen deel uit van de opdracht van de compiler en worden daarom niet overwogen tijdens optimalisatie en/of codegeneratie.
Stel nu dat de code ongewijzigd blijft, maar dat de context in de code die aan de compiler wordt gepresenteerd enigszins verandert, zoals in figuur 3.
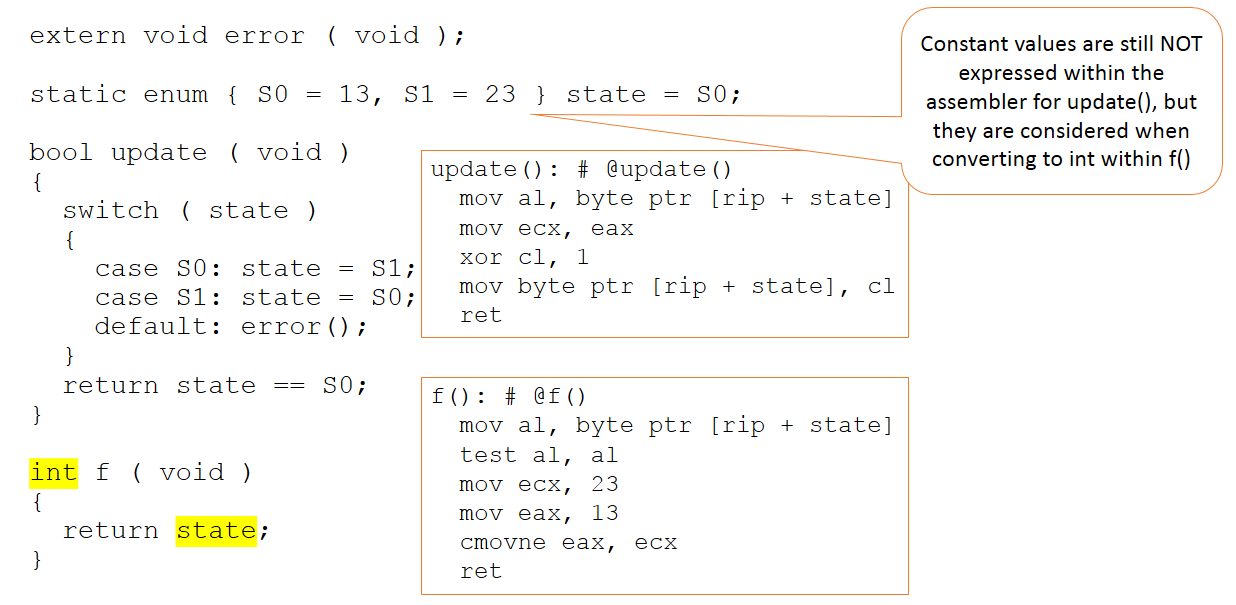
Figuur 3:De code blijft ongewijzigd, maar de context in de code die aan de compiler wordt gepresenteerd, verandert enigszins. (Bron:LDRA)
Er is nu een extra functie, die de waarde van de toestandsvariabele als een geheel getal retourneert. Deze keer zijn de absolute waarden 13 en 23 van belang in de code die naar de compiler wordt gestuurd. Toch worden deze waarden niet gemanipuleerd binnen de update-functie (die ongewijzigd blijft) en zijn ze alleen zichtbaar binnen onze nieuwe "f"-functie.
Kortom, de compiler gaat (terecht) door met het maken van waardeoordelen over waar de waarden van 13 en 23 moeten worden gebruikt - en ze worden lang niet in alle situaties toegepast waar ze zouden kunnen zijn.
Als de nieuwe functie wordt gewijzigd om een pointer naar onze toestandsvariabele te retourneren, verandert de assembler-code aanzienlijk. Omdat er nu de mogelijkheid is voor aliastoegang via een pointer, kan de compiler niet langer afleiden wat er met het statusobject gebeurt. Zoals weergegeven in figuur 4 hieronder, kan het niet concluderen dat de waarden van 13 en 23 onbelangrijk zijn en daarom worden ze nu expliciet uitgedrukt in de assembler.
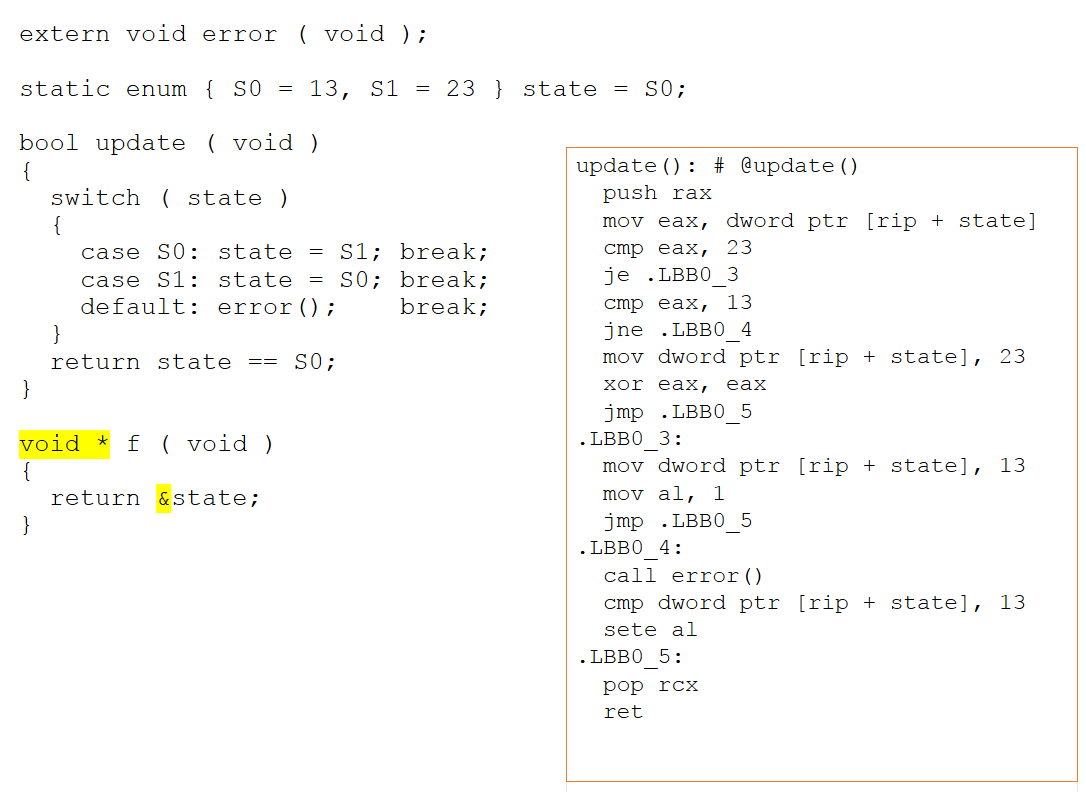
Figuur 4:Als de nieuwe functie wordt gewijzigd om een pointer naar onze toestandsvariabele terug te sturen, verandert de assembler-code aanzienlijk. Het kan niet concluderen dat de waarden van 13 en 23 onbelangrijk zijn en daarom worden ze nu expliciet uitgedrukt in de assembler (Bron:LDRA).
Implicaties voor de eenheidstest van de broncode
Beschouw nu het voorbeeld in de context van een denkbeeldige eenheidstestharnas. Als gevolg van de noodzaak van een harnas om toegang te krijgen tot de te testen code, wordt de waarde van de toestandsvariabele gemanipuleerd en als gevolg daarvan wordt de standaard niet "weggeoptimaliseerd". Zo'n benadering is volledig te rechtvaardigen in een testtool die geen context heeft met betrekking tot de rest van de broncode en die nodig is om alles toegankelijk te maken, maar als neveneffect het legitieme weglaten van defensieve code door de compiler kan verhullen.
De compiler herkent dat een willekeurige waarde via een pointer naar de toestandsvariabele wordt geschreven, en nogmaals, hij kan niet concluderen dat de waarden van 13 en 23 onbelangrijk zijn. Bijgevolg worden ze nu expliciet uitgedrukt in de assembler. Bij deze gelegenheid kan het niet concluderen dat S0 en S1 de enige mogelijke waarden zijn voor de toestandsvariabele, wat betekent dat het standaardpad mogelijk is. Zoals weergegeven in figuur 5, bereikt de manipulatie van de toestandsvariabele zijn doel en is de aanroep van de foutfunctie nu duidelijk in de assembler.

Figuur 5:De manipulatie van de toestandsvariabele bereikt zijn doel en de aanroep van de foutfunctie is nu duidelijk in de assembler. (Bron:LDRA)
Deze manipulatie zal echter niet aanwezig zijn in de code die binnen een product wordt verzonden, en dus is de call to error() niet echt aanwezig in het volledige systeem.
Het belang van objectcodeverificatie
Om te illustreren hoe objectcodeverificatie kan helpen om dit raadsel op te lossen, kunt u het eerste voorbeeldcodefragment bekijken, weergegeven in Afbeelding 6:

Afbeelding 6:Dit illustreert hoe objectcodeverificatie kan helpen om op te lossen dat de call-to-error niet in het volledige systeem zit. (Bron:LDRA)
Met een enkele oproep kan worden aangetoond dat deze C-code 100% dekking van de broncode bereikt, dus:
f_while4(0,3);
De code kan opnieuw worden geformatteerd naar een enkele bewerking per regel en worden weergegeven in een stroomdiagram als een verzameling "basisblok" -knooppunten, die elk een reeks lineaire code zijn. De relatie tussen de basisblokken wordt weergegeven in figuur 7 met behulp van gerichte randen tussen de knooppunten.
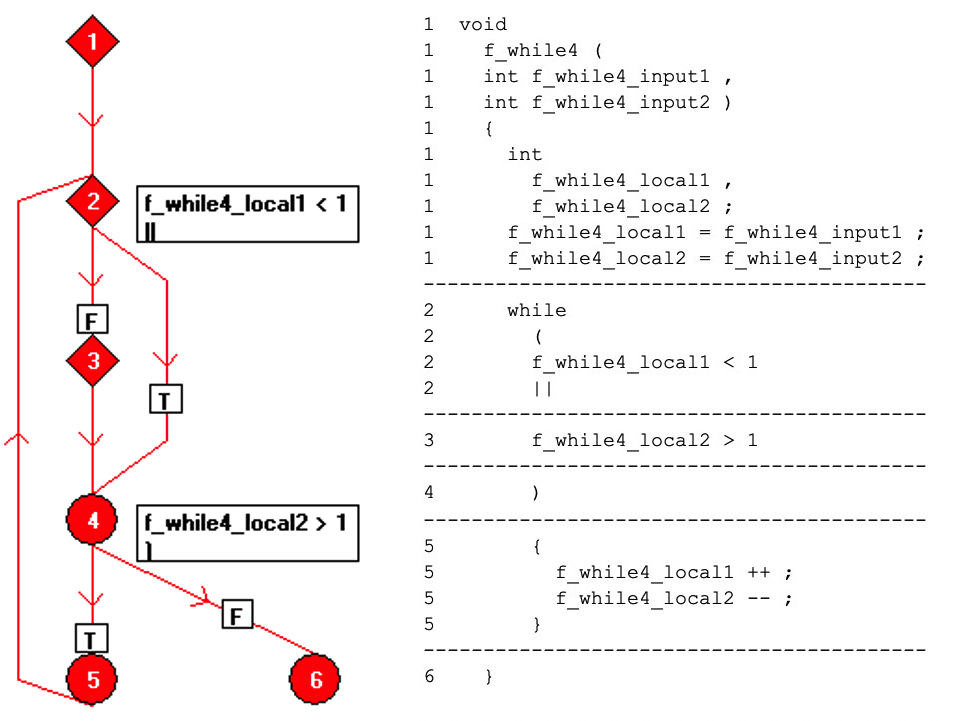
Figuur 7:Dit toont de relatie tussen de basisblokken met behulp van gerichte randen tussen de knooppunten. (Bron:LDRA)
Wanneer de code is gecompileerd, is het resultaat zoals hieronder weergegeven (Afbeelding 8). De blauwe elementen van de stroomgrafiek vertegenwoordigen code die niet is uitgevoerd door de aanroep f_while4(0,3).
Door gebruik te maken van de één-op-één relatie tussen objectcode en assemblercode, onthult dit mechanisme welke delen van de objectcode niet worden gebruikt, waardoor de tester wordt gevraagd aanvullende tests te bedenken en volledige dekking van de assemblercode te bereiken - en dus objectcodeverificatie te bereiken.
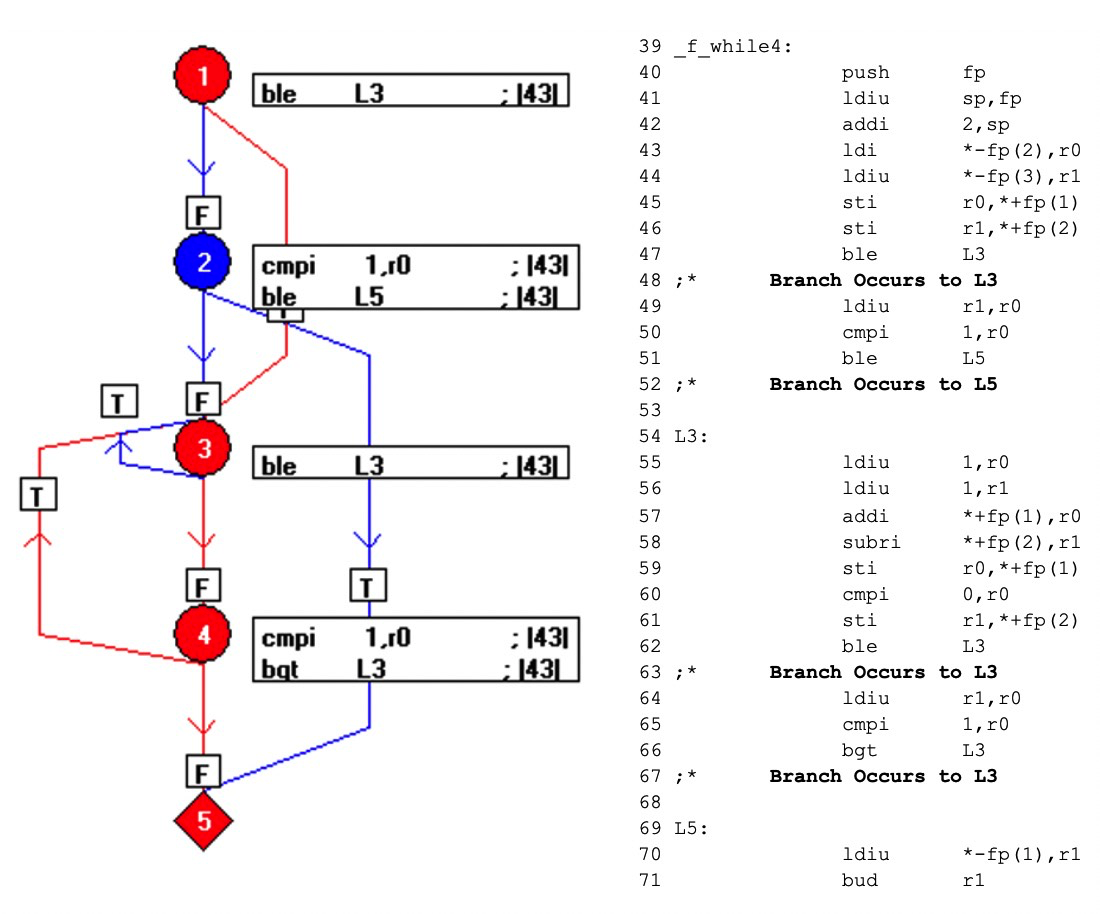
Figuur 8:Dit toont het resultaat wanneer de code wordt gecompileerd. De blauwe elementen van de stroomgrafiek vertegenwoordigen code die niet is uitgevoerd door de aanroep f_while4(0,3). (Bron:LDRA)
Het is duidelijk dat objectcodeverificatie niet kan voorkomen dat de compiler zijn ontwerpregels volgt en onbedoeld de beste bedoelingen van ontwikkelaars omzeilt. Maar het kan en zal dergelijke mismatches onder de aandacht brengen van onoplettende mensen.
Beschouw dat principe nu eens in de context van het eerdere voorbeeld van 'call to error'. De broncode in het voltooide systeem zou natuurlijk identiek zijn aan de broncode die op unittestniveau is bewezen, dus een vergelijking daarvan zou niets opleveren. Maar de toepassing van objectcodeverificatie op het voltooide systeem zou van onschatbare waarde zijn om te verzekeren dat essentieel gedrag wordt uitgedrukt zoals de ontwikkelaars het bedoeld hebben.
Beste praktijken in elke wereld
Als de compiler code anders verwerkt in het testharnas in vergelijking met de unit-test, is het dan de moeite waard om de broncode-unittest te dekken? Het antwoord is een gekwalificeerd "ja". Veel systemen zijn gecertificeerd op het bewijs van dergelijke artefacten en zijn veilig en betrouwbaar gebleken in gebruik. Maar voor de meest kritieke systemen in alle sectoren geldt dat als het ontwikkelingsproces de meest gedetailleerde controle moet doorstaan en moet voldoen aan de beste praktijken, de dekking van unittests op bronniveau moet worden aangevuld met OCV. Het is redelijk om aan te nemen dat het voldoet aan de ontwerpcriteria, maar die criteria omvatten geen functionele veiligheidsoverwegingen. Objectcodeverificatie vertegenwoordigt momenteel de meest betrouwbare benadering van de wereld van functionele veiligheid, waar compilergedrag voldoet aan de normen, maar niettemin een aanzienlijk negatief effect kan hebben.
Ingebed
- Het belang van elektrische veiligheid
- De wereld van textielkleurstoffen
- Toepassing van zure kleurstoffen in de wereld van stoffen
- Een blik in de wereld van kleurstoffen
- De vele toepassingen van veiligheidsmanden
- De snel evoluerende wereld van simulatie
- De productiehoofdsteden van de wereld
- 5 van de belangrijkste veiligheidstips voor kranen
- Het belang van wrijvingsmaterialen in veiligheidssystemen
- Veiligheid in fabrieken:een bron van continue verbetering
- De verschillen tussen G-code en M-code