


Python RegEx:re.match(), re.search(), re.findall() met Voorbeeld
Wat is reguliere expressie in Python?
Een Reguliere expressie (RE) in een programmeertaal is een speciale tekenreeks die wordt gebruikt om een zoekpatroon te beschrijven. Het is uitermate handig voor het extraheren van informatie uit tekst, zoals code, bestanden, logbestanden, spreadsheets of zelfs documenten.
Bij het gebruik van de reguliere expressie van Python is het eerste wat je moet herkennen dat alles in wezen een teken is, en we schrijven patronen die overeenkomen met een specifieke reeks tekens, ook wel string genoemd. Ascii of Latijnse letters zijn die op uw toetsenborden en Unicode wordt gebruikt om de vreemde tekst te matchen. Het bevat cijfers en leestekens en alle speciale tekens zoals $#@!%, enz.
In deze Python RegEx-zelfstudie leren we-
- Syntaxis voor reguliere expressies
- Voorbeeld van w+ en ^ Expressie
- Voorbeeld van \s expressie in re.split functie
- Reguliere expressiemethoden gebruiken
- Re.match() gebruiken
- Patroon zoeken in tekst (re.search())
- Re.findall gebruiken voor tekst
- Python-vlaggen
- Voorbeeld van re.M of Multiline Flags
Een reguliere expressie in Python kan bijvoorbeeld een programma vertellen om naar specifieke tekst uit de tekenreeks te zoeken en het resultaat dienovereenkomstig af te drukken. Expressie kan onder meer
- Tekstovereenkomst
- Herhaling
- Vertakking
- Patroon-compositie enz.
Reguliere expressie of RegEx in Python wordt aangeduid als RE (RE's, regexes of regex-patroon) worden geïmporteerd via re module . Python ondersteunt reguliere expressie via bibliotheken. RegEx in Python ondersteunt verschillende dingen zoals Modifiers, Identifiers en witruimtetekens .
| ID's | Modifiers | Witruimtetekens | Ontsnappen vereist |
|---|---|---|---|
| \d=elk nummer (een cijfer) | \d staat voor een cijfer.Ex:\d{1,5} het geeft een cijfer tussen 1,5 aan, zoals 424.444.545 enz. | \n =nieuwe regel | . + * ? [] $ ^ () {} | \ |
| \D=alles behalve een getal (een niet-cijferig) | + =komt overeen met 1 of meer | \s=spatie | |
| \s =spatie (tab,spatie,nieuwe regel etc.) | ? =komt overeen met 0 of 1 | \t =tab | |
| \S=alles behalve een spatie | * =0 of meer | \e =ontsnappen | |
| \w =letters ( Komt overeen met alfanumeriek teken, inclusief "_") | $ komt overeen met het einde van een tekenreeks | \r =regelterugloop | |
| \W =alles behalve letters ( Komt overeen met een niet-alfanumeriek teken behalve "_") | ^ komt overeen met het begin van een tekenreeks | \f=formulierfeed | |
| . =alles behalve letters (punten) | | komt overeen met of x/y | —————– | |
| \b =elk teken behalve de nieuwe regel | [] =bereik of “variantie” | —————- | |
| \. | {x} =dit aantal voorgaande code | —————– |
Regular Expression(RE)-syntaxis
import re
- "re"-module meegeleverd met Python, voornamelijk gebruikt voor het zoeken en manipuleren van strings
- Ook vaak gebruikt voor het "scrapen" van webpagina's (grote hoeveelheden gegevens van websites halen)
We beginnen de tutorial over uitdrukkingen met deze eenvoudige oefening door de uitdrukkingen (w+) en (^) te gebruiken.
Voorbeeld van w+ en ^ Expressie
- “^”: Deze uitdrukking komt overeen met het begin van een tekenreeks
- “w+ “:Deze uitdrukking komt overeen met het alfanumerieke teken in de tekenreeks
Hier zullen we een Python RegEx-voorbeeld zien van hoe we w+ en ^ expressies in onze code kunnen gebruiken. We behandelen de functie re.findall() in Python, verderop in deze tutorial, maar voor een tijdje concentreren we ons gewoon op \w+ en \^ expressies.
Bijvoorbeeld, voor onze string "guru99, onderwijs is leuk" als we de code uitvoeren met w+ en ^, zal het de output "guru99" geven.
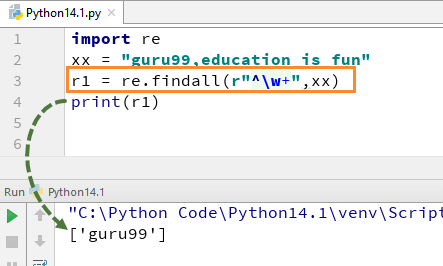
import re xx = "guru99,education is fun" r1 = re.findall(r"^\w+",xx) print(r1)
Onthoud dat als je het +teken van de w+ verwijdert, de uitvoer zal veranderen en alleen het eerste teken van de eerste letter zal geven, d.w.z. [g]
Voorbeeld van \s expressie in re.split functie
- “s”:deze uitdrukking wordt gebruikt voor het maken van een spatie in de tekenreeks
Om te begrijpen hoe deze RegEx in Python werkt, beginnen we met een eenvoudig Python RegEx-voorbeeld van een splitfunctie. In het voorbeeld hebben we elk woord gesplitst met behulp van de functie "re.split" en tegelijkertijd hebben we de uitdrukking \s gebruikt waarmee elk woord in de tekenreeks afzonderlijk kan worden geparseerd.
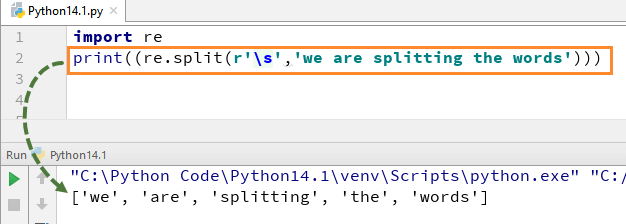
Wanneer u deze code uitvoert, krijgt u de uitvoer ['wij', 'zijn', 'splitting', 'de', 'woorden'].
Laten we nu eens kijken wat er gebeurt als u "\" uit s verwijdert. Er is geen 's'-alfabet in de uitvoer, dit komt omdat we '\' uit de tekenreeks hebben verwijderd, en het evalueert "s" als een normaal teken en splitst dus de woorden waar het "s" in de tekenreeks vindt.
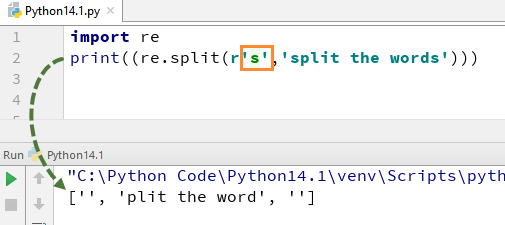
Evenzo zijn er reeksen andere reguliere expressies van Python die u op verschillende manieren in Python kunt gebruiken, zoals \d,\D,$,\.,\b, enz.
Hier is de volledige code
import re xx = "guru99,education is fun" r1 = re.findall(r"^\w+", xx) print((re.split(r'\s','we are splitting the words'))) print((re.split(r's','split the words')))
Vervolgens gaan we kijken naar de soorten methoden die worden gebruikt met reguliere expressies in Python.
Reguliere expressiemethoden gebruiken
Het "re" -pakket biedt verschillende methoden om daadwerkelijk query's uit te voeren op een invoertekenreeks. We zullen de methoden van re in Python zien:
- re.match()
- re.search()
- re.findall()
Opmerking :Op basis van de reguliere expressies biedt Python twee verschillende primitieve bewerkingen. De match-methode controleert alleen op een overeenkomst aan het begin van de tekenreeks, terwijl zoeken overal in de tekenreeks op een overeenkomst controleert.
re.match()
re.match() functie van re in Python zal het patroon van de reguliere expressie doorzoeken en het eerste exemplaar retourneren. De Python RegEx Match-methode controleert alleen op een overeenkomst aan het begin van de tekenreeks. Dus als een overeenkomst wordt gevonden in de eerste regel, wordt het overeenkomstobject geretourneerd. Maar als er een overeenkomst wordt gevonden in een andere regel, retourneert de Python RegEx Match-functie null.
Overweeg bijvoorbeeld de volgende code van de functie Python re.match(). De uitdrukking "w+" en "\W" komt overeen met de woorden die beginnen met de letter 'g' en daarna wordt alles wat niet met 'g' begint niet geïdentificeerd. Om de overeenkomst voor elk element in de lijst of tekenreeks te controleren, voeren we de forloop uit in dit Python re.match()-voorbeeld.
re.search():patroon vinden in tekst
onderzoek() functie zoekt het patroon van de reguliere expressie en retourneert het eerste exemplaar. In tegenstelling tot Python re.match(), zal het alle regels van de invoerstring controleren. De functie Python re.search() retourneert een match-object wanneer het patroon wordt gevonden en "null" als het patroon niet wordt gevonden
Hoe gebruik ik zoek()?
Om de zoekfunctie () te gebruiken, moet u eerst de Python re-module importeren en vervolgens de code uitvoeren. De functie Python re.search() neemt het "patroon" en "tekst" om te scannen uit onze hoofdreeks
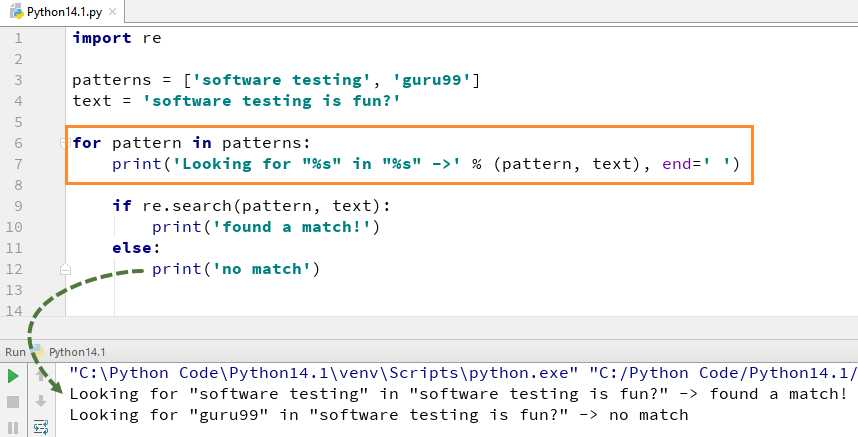
Hier zoeken we bijvoorbeeld naar twee letterlijke strings “Software testing” “guru99”, in een tekststring “Software Testing is fun”. Voor "softwaretesten" hebben we de overeenkomst gevonden, vandaar dat het de uitvoer van Python re.search() Voorbeeld retourneert als "een overeenkomst gevonden", terwijl we voor het woord "guru99" niet in string konden vinden, vandaar dat het de uitvoer retourneert als "Geen overeenkomst ”.
re.findall()
findall() module wordt gebruikt om te zoeken naar "alle" gebeurtenissen die overeenkomen met een bepaald patroon. De module search() daarentegen retourneert alleen het eerste exemplaar dat overeenkomt met het opgegeven patroon. findall() herhaalt alle regels van het bestand en retourneert alle niet-overlappende overeenkomsten van het patroon in een enkele stap.
Hoe re.findall() in Python te gebruiken?
Hier hebben we een lijst met e-mailadressen, en we willen dat alle e-mailadressen uit de lijst worden gehaald, we gebruiken de methode re.findall() in Python. Het zal alle e-mailadressen uit de lijst vinden.
Hier is de volledige code voor Voorbeeld van re.findall()
import re
list = ["guru99 get", "guru99 give", "guru Selenium"]
for element in list:
z = re.match("(g\w+)\W(g\w+)", element)
if z:
print((z.groups()))
patterns = ['software testing', 'guru99']
text = 'software testing is fun?'
for pattern in patterns:
print('Looking for "%s" in "%s" ->' % (pattern, text), end=' ')
if re.search(pattern, text):
print('found a match!')
else:
print('no match')
abc = '[email protected], [email protected], [email protected]'
emails = re.findall(r'[\w\.-]+@[\w\.-]+', abc)
for email in emails:
print(email) Python-vlaggen
Veel Python Regex-methoden en Regex-functies hebben een optioneel argument met de naam Vlaggen. Deze vlaggen kunnen de betekenis van het gegeven Python Regex-patroon wijzigen. Om deze te begrijpen, zullen we een of twee voorbeelden van deze vlaggen zien.
Verschillende vlaggen die in Python worden gebruikt, omvatten
| Syntaxis voor Regex-vlaggen | Wat doet deze vlag |
|---|---|
| [re.M] | Maak begin/eind rekening met elke regel |
| [re.I] | Het negeert hoofdletters |
| [re.S] | Maak [ . ] |
| [re.U] | Zorg ervoor dat { \w,\W,\b,\B} de Unicode-regels volgt |
| [re.L] | Laat {\w,\W,\b,\B} de landinstelling volgen |
| [re.X] | Reactie toestaan in Regex |
Voorbeeld van re.M of Multiline Flags
In multiline komt het patroonteken [^] overeen met het eerste teken van de string en het begin van elke regel (direct volgend op elke nieuwe regel). Terwijl de uitdrukking kleine "w" wordt gebruikt om de spatie met tekens te markeren. Wanneer u de code uitvoert, drukt de eerste variabele "k1" alleen het teken 'g' af voor woord guru99, terwijl wanneer u een vlag met meerdere regels toevoegt, deze de eerste tekens van alle elementen in de tekenreeks ophaalt.
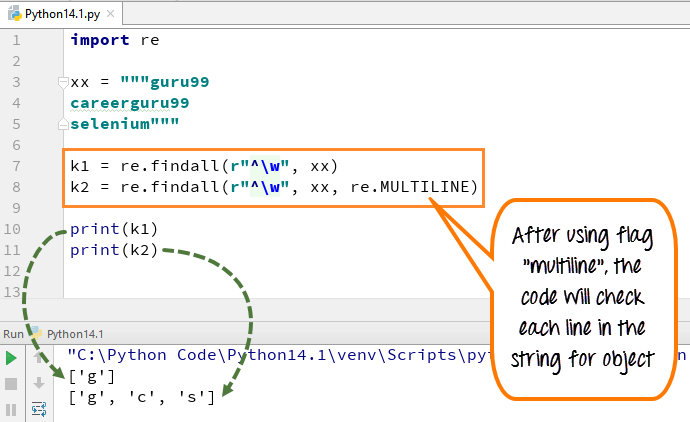
Hier is de code
import re xx = """guru99 careerguru99 selenium""" k1 = re.findall(r"^\w", xx) k2 = re.findall(r"^\w", xx, re.MULTILINE) print(k1) print(k2)
- We hebben de variabele xx gedeclareerd voor string ” guru99…. careerguru99….selenium”
- Voer de code uit zonder vlaggen multiline te gebruiken, het geeft de uitvoer alleen 'g' van de regels
- Voer de code uit met vlag "multiline", wanneer u 'k2' afdrukt, geeft dit de uitvoer als 'g', 'c' en 's'
- Dus het verschil dat we kunnen zien na en voor het toevoegen van meerdere regels in het bovenstaande voorbeeld.
Op dezelfde manier kunt u ook andere Python-vlaggen gebruiken, zoals re.U (Unicode), re.L (landinstelling volgen), re.X (commentaar toestaan), enz.
Python 2 voorbeeld
Bovenstaande codes zijn Python 3-voorbeelden. Als u Python 2 wilt gebruiken, overweeg dan de volgende code.
# Example of w+ and ^ Expression
import re
xx = "guru99,education is fun"
r1 = re.findall(r"^\w+",xx)
print r1
# Example of \s expression in re.split function
import re
xx = "guru99,education is fun"
r1 = re.findall(r"^\w+", xx)
print (re.split(r'\s','we are splitting the words'))
print (re.split(r's','split the words'))
# Using re.findall for text
import re
list = ["guru99 get", "guru99 give", "guru Selenium"]
for element in list:
z = re.match("(g\w+)\W(g\w+)", element)
if z:
print(z.groups())
patterns = ['software testing', 'guru99']
text = 'software testing is fun?'
for pattern in patterns:
print 'Looking for "%s" in "%s" ->' % (pattern, text),
if re.search(pattern, text):
print 'found a match!'
else:
print 'no match'
abc = '[email protected], [email protected], [email protected]'
emails = re.findall(r'[\w\.-]+@[\w\.-]+', abc)
for email in emails:
print email
# Example of re.M or Multiline Flags
import re
xx = """guru99
careerguru99
selenium"""
k1 = re.findall(r"^\w", xx)
k2 = re.findall(r"^\w", xx, re.MULTILINE)
print k1
print k2
Samenvatting
Een reguliere expressie in een programmeertaal is een speciale tekenreeks die wordt gebruikt om een zoekpatroon te beschrijven. Het bevat cijfers en leestekens en alle speciale tekens zoals $#@!%, enz. Expressie kan letterlijke
bevatten- Tekstovereenkomst
- Herhaling
- Vertakking
- Patroon-compositie enz.
In Python wordt een reguliere expressie aangeduid als RE (RE's, regexes of regex-patroon) die zijn ingebed via de Python re-module.
- "re"-module meegeleverd met Python, voornamelijk gebruikt voor het zoeken en manipuleren van strings
- Ook vaak gebruikt voor het "scrapen" van webpagina's (grote hoeveelheden gegevens van websites halen)
- Reguliere expressiemethoden omvatten re.match(),re.search()&re.findall()
- Andere Python RegEx-vervangingsmethoden zijn sub() en subn() die worden gebruikt om overeenkomende tekenreeksen in re te vervangen
- Python-vlaggen Veel Python Regex-methoden en Regex-functies hebben een optioneel argument met de naam Vlaggen
- Deze vlag kan de betekenis van het gegeven Regex-patroon wijzigen
- Verschillende Python-vlaggen die worden gebruikt in Regex-methoden zijn re.M, re.I, re.S, enz.
Python
- Python String strip() Functie met VOORBEELD
- Python String count() met VOORBEELDEN
- Python String format() Leg uit met VOORBEELDEN
- Python-tekenreekslengte | len() methode Voorbeeld
- Methode Python String find() met voorbeelden
- Python round() functie met VOORBEELDEN
- Python map() functie met VOORBEELDEN
- Python Timeit() met voorbeelden
- Python-teller in verzamelingen met voorbeeld
- Python List count() met VOORBEELDEN
- Python Lijst index() met Voorbeeld