


Ontwikkel nieuwe codeergewoonten om fouten in embedded software te verminderen
De omvang en complexiteit van applicaties is de afgelopen tien jaar aanzienlijk toegenomen. Neem als voorbeeld de automobielsector. Volgens The New York Times , 20 jaar geleden had de gemiddelde auto een miljoen regels code, maar 10 jaar later had de General Motors 2010 Chevrolet Volt ongeveer 10 miljoen regels code - meer dan een F-35 straaljager. Tegenwoordig heeft een gemiddelde auto meer dan 100 miljoen regels code.
De verschuiving naar 32-bits en hogere processors met veel geheugen en kracht heeft bedrijven in staat gesteld om veel meer functies en mogelijkheden met toegevoegde waarde in ontwerpen in te bouwen; dat is het voordeel. Het nadeel is dat de hoeveelheid code en de complexiteit ervan vaak leiden tot fouten die van invloed zijn op de beveiliging en veiligheid van applicaties.
Het wordt tijd voor een betere aanpak. Twee belangrijke soorten fouten kunnen in software worden gevonden en worden verholpen met tools die voorkomen dat fouten worden geïntroduceerd:
- Codeerfouten:een voorbeeld is code die probeert toegang te krijgen buiten de grenzen van een array. Dit soort problemen kunnen worden opgespoord door statische analyse uit te voeren.
- Applicatiefouten:deze kunnen alleen worden opgespoord door precies te weten wat de applicatie moet doen, wat inhoudt dat u moet toetsen aan de vereisten.
Pak deze fouten aan en ontwerpingenieurs zullen een heel eind op weg zijn naar meer veilige en beveiligde code.
Een greintje preventie via codecontrole
Fouten in code treden net zo gemakkelijk op als fouten in e-mail en instant messaging. Dit zijn de simpele fouten die optreden omdat technici haast hebben en niet proeflezen. Maar met complexiteit komt een scala aan ontwerpfouten die enorme uitdagingen creëren. Complexiteit leidt tot een behoefte aan een geheel nieuw niveau van begrip van hoe het systeem werkt, hoe gegevens worden doorgegeven en hoe waarden worden gedefinieerd. Of fouten nu worden veroorzaakt door complexiteit of een menselijk probleem, ze kunnen ertoe leiden dat een stukje code probeert toegang te krijgen tot een waarde buiten de grenzen van een array. En een coderingsstandaard vangt dat op.
Misschien ben je ook geïnteresseerd in deze gerelateerde artikelen van Embedded:
Bouw veilige en betrouwbare embedded systemen met MISRA C/C++
Statische analyse gebruiken om coderingsfouten te detecteren in open source beveiligingskritieke servertoepassingen
Hoe dergelijke fouten te voorkomen? Zet ze daar niet in de eerste plaats. Hoewel dit voor de hand liggend klinkt - en bijna onmogelijk - is dit precies de waarde die een coderingsstandaard op tafel legt.
In de C- en C++-wereld wordt 80% van de softwarefouten veroorzaakt door onjuist of onverstandig gebruik van ongeveer 20% van de taal. De coderingsstandaard legt beperkingen op aan de delen van de taal waarvan bekend is dat ze problematisch zijn. Het resultaat:defecten worden vermeden en de kwaliteit van de software neemt sterk toe. Laten we een paar voorbeelden bekijken.
De meeste programmeerfouten in C en C++ worden veroorzaakt door ongedefinieerd, door de implementatie gedefinieerd en niet-gespecificeerd gedrag dat inherent is aan elke taal, wat leidt tot softwarefouten en beveiligingsproblemen. Dit door de implementatie gedefinieerde gedrag verspreidt een bit van hoge orde wanneer een geheel getal met teken naar rechts wordt verschoven. Afhankelijk van de compiler-engineers die worden gebruikt, kan het resultaat 0x40000000 of 0xC0000000 zijn, aangezien C niet de volgorde specificeert waarin argumenten voor een functie worden geëvalueerd.
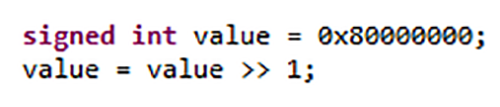
Figuur 1. Het gedrag van sommige C- en C++-constructies hangt af van de gebruikte compiler. Bron:LDRA
In figuur 2 —waar de rollDice() functie leest eenvoudig de volgende waarde uit een cirkelvormige buffer met de waarden "1,2,3 en 4" - de verwachte geretourneerde waarde zou 1234 zijn. Maar daar is geen garantie voor. Ten minste één compiler genereert code die de waarde 3412 retourneert.

Figuur 2. Het gedrag van sommige C- en C++-constructies wordt niet gespecificeerd door de talen. Bron:LDRA
Er zijn tal van andere valkuilen in de C/C++-taal:gebruik van constructies zoals goto of malloc; mixen van ondertekende en niet-ondertekende waarden; of "slimme" code die zeer efficiënt en compact kan zijn, maar zo cryptisch en complex is dat anderen moeite hebben om het te begrijpen. Elk van deze problemen kan leiden tot defecten, waarde-overflows die plotseling negatief worden, of het gewoon onmogelijk maken om code te onderhouden.
Coderingsnormen bieden het greintje preventie voor deze kwalen. Ze kunnen het gebruik van deze problematische constructies voorkomen en voorkomen dat ontwikkelaars ongedocumenteerde, te complexe code maken en de consistentie van stijl controleren. Zelfs zaken als controleren of het tabteken niet wordt gebruikt of haakjes op een specifieke positie worden geplaatst, kunnen worden gecontroleerd. Hoewel dit triviaal lijkt, helpt het volgen van de stijl enorm bij het handmatig beoordelen van code en voorkomt het verwarring veroorzaakt door een andere tabgrootte wanneer code in een andere editor wordt bekeken - allemaal afleidingen die voorkomen dat een reviewer zich op de code concentreert.
MISRA te hulp
De bekendste programmeerstandaarden zijn de MISRA-richtlijnen, voor het eerst gepubliceerd in 1998 voor de auto-industrie en nu algemeen aanvaard door veel embedded compilers die een zekere mate van MISRA-controle bieden. MISRA richt zich op de problematische constructies en praktijken binnen de C- en C++-talen, waarbij het gebruik van consistente stilistische kenmerken wordt aanbevolen, terwijl het stoppen met het suggereren van enige.
De MISRA-richtlijnen bieden nuttige uitleg over waarom elke regel bestaat, samen met details van de verschillende uitzonderingen op die regel, en voorbeelden van het ongedefinieerde, niet-gespecificeerde en door de implementatie gedefinieerde gedrag. Afbeelding 3 illustreert het begeleidingsniveau.

Figuur 3. Deze MISRA C-referenties hebben betrekking op niet-gedefinieerd, niet-gespecificeerd en door de implementatie gedefinieerd gedrag. Bron:LDRA
De meeste MISRA-richtlijnen zijn 'beslisbaar', wat betekent dat de tool kan identificeren of er sprake is van een overtreding; maar sommige zijn "onbeslisbaar", wat inhoudt dat het niet altijd mogelijk is voor de tool om af te leiden of er een overtreding is.
Een niet-geïnitialiseerde variabele die wordt doorgegeven aan een systeemfunctie die deze zou moeten initialiseren, wordt mogelijk niet als een fout geregistreerd als de statische analysetool geen toegang heeft tot de broncode voor de systeemfunctie. Er is kans op een vals-negatief of een vals-positief.
In 2016 werden 14 richtlijnen toegevoegd aan MISRA om te voorzien in controle op veiligheidskritieke code, niet alleen op veiligheid. Afbeelding 4 illustreert hoe een van de nieuwe richtlijnen, Richtlijn 4.14, dit probleem oplost en de valkuilen door ongedefinieerd gedrag helpt voorkomen.

Figuur 4. MISRA-richtlijn 4.14 helpt de valkuilen van ongedefinieerd gedrag te voorkomen. Bron:LDRA
De strengheid van coderingsnormen werd traditioneel geassocieerd met functioneel veilige software voor kritieke toepassingen zoals auto's, vliegtuigen en medische apparaten. De complexiteit van code, het belang van beveiliging en het zakelijke belang van het creëren van hoogwaardige, robuuste code die gemakkelijk te onderhouden en te upgraden is, maken de coderingsstandaarden echter cruciaal in alle ontwikkelingsactiviteiten.
Door ervoor te zorgen dat fouten niet in de eerste plaats in de code worden geïntroduceerd, moeten ontwikkelteams:
- de noodzaak voor uitgebreide foutopsporing verminderen,
- een betere controle krijgen over het schema, en
- controleer de ROI door de totale kosten te verlagen.
Codecontrole biedt een toolbox met enorme potentiële voordelen.
Een pond genezen met testtools
Hoewel codecontrole veel problemen oplost, kunnen applicatiefouten alleen worden gevonden door te testen of het product doet wat het moet doen, en dat betekent dat er eisen worden gesteld. Het vermijden van applicatiefouten vereist zowel het ontwerpen van het juiste product als het juist ontwerpen van het product.
Het juiste product ontwerpen betekent vooraf eisen stellen en zorgen voor bidirectionele traceerbaarheid tussen de eisen en de broncode, zodat elke vereiste wordt geïmplementeerd en elke softwarefunctie teruggaat naar een vereiste. Elke ontbrekende of onnodige functionaliteit - die niet aan een vereiste voldoet - is een applicatiefout. Het productrecht ontwerpen is het proces van bevestigen dat de ontwikkelde systeemcode voldoet aan de projectvereisten. Dat bereik je door op vereisten gebaseerde tests uit te voeren.
Figuur 5 toont een voorbeeld van bidirectionele traceerbaarheid. De enkele geselecteerde functie traceert stroomopwaarts van de functie naar een vereiste op laag niveau, vervolgens naar een vereiste op hoog niveau en ten slotte naar een vereiste op systeemniveau.
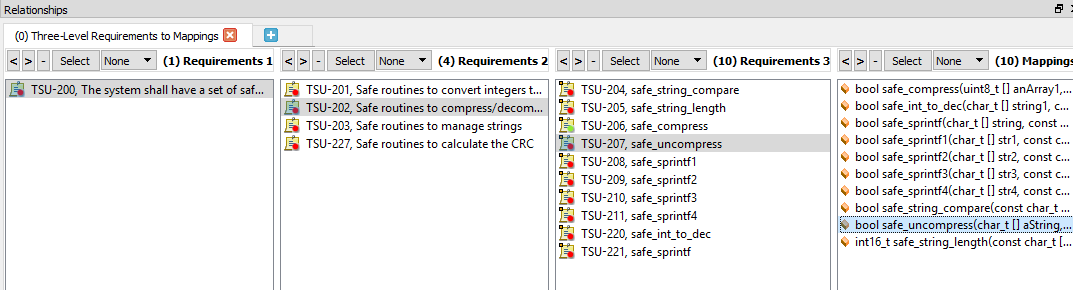
Figuur 5. Dit is een voorbeeld van bidirectionele traceerbaarheid met een enkele functie geselecteerd. Bron:LDRA
Afbeelding 6 laat zien hoe de selectie van een vereiste op hoog niveau zowel upstream-traceerbaarheid naar een vereiste op systeemniveau als downstream naar vereisten op laag niveau en naar broncodefuncties toont.
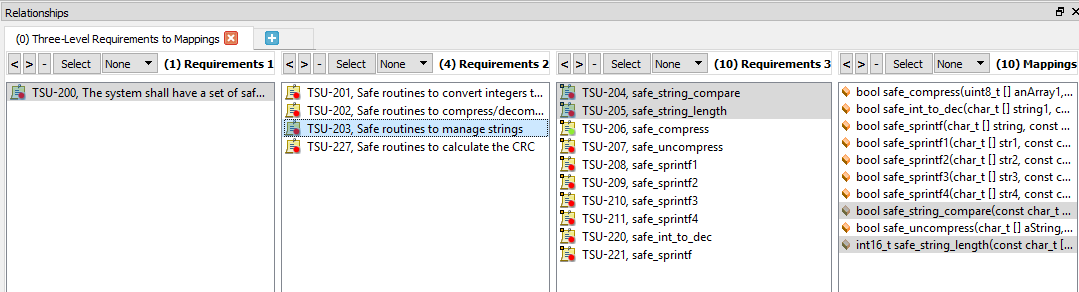
Figuur 6. Dit is een voorbeeld van bidirectionele traceerbaarheid met geselecteerde vereisten. Bron:LDRA
Deze mogelijkheid om traceerbaarheid te visualiseren kan leiden tot de detectie van applicatiebugs vroeg in de levenscyclus.
Het testen van codefunctionaliteit vereist een bewustzijn van wat het zou moeten doen, en dat betekent dat er lage vereisten zijn die aangeven wat elke functie doet. Afbeelding 7 toont een voorbeeld van een vereiste op laag niveau, die in dit geval een enkele functie volledig beschrijft.
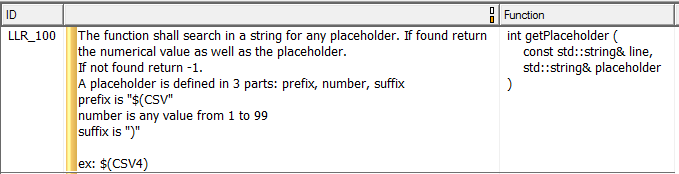
Figuur 7. Dit is een voorbeeld van een vereiste op een laag niveau die een enkele functie beschrijft. Bron:LDRA
Testgevallen zijn afgeleid van vereisten op een laag niveau, zoals geïllustreerd in figuur 8.
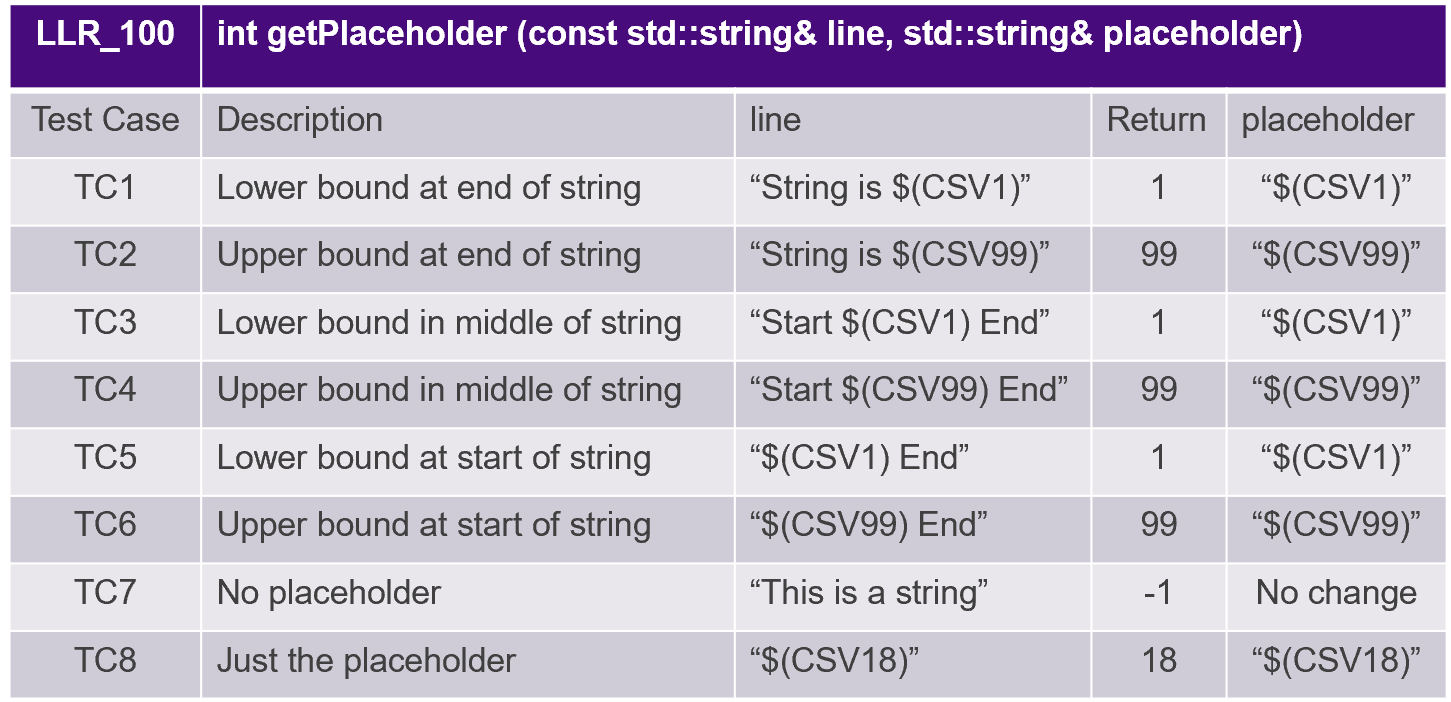
Figuur 8. Testgevallen zijn afgeleid van vereisten op een laag niveau. Bron:LDRA
Met behulp van een unit-testtool kunnen deze testgevallen vervolgens worden uitgevoerd op de host of het doel om ervoor te zorgen dat de code zich gedraagt zoals de vereiste zegt dat het zou moeten. Afbeelding 9 laat zien dat alle testgevallen zijn teruggelopen en zijn geslaagd.
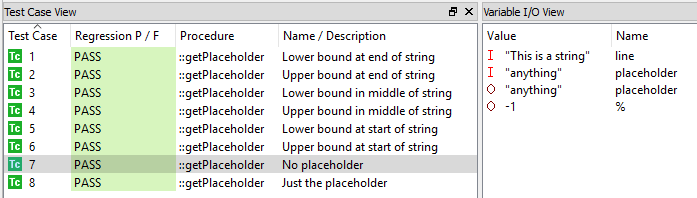
Figuur 9. Zo voert een tool unit tests uit. Bron:LDRA
Nadat de testgevallen zijn uitgevoerd, moet de structurele dekking worden gemeten om ervoor te zorgen dat alle code is toegepast. Als de dekking niet 100 procent is, is het mogelijk dat er meer testgevallen nodig zijn of dat overtollige code moet worden verwijderd.
Nieuwe gewoonten bij het coderen
Het lijdt geen twijfel dat de complexiteit van software - en de bijbehorende fouten - enorm zijn toegenomen met connectiviteit, sneller geheugen, rijke hardwareplatforms en specifieke klanteisen. Door een ultramoderne coderingsstandaard aan te nemen, metrieken op de code te meten, vereisten op te sporen en op vereisten gebaseerde tests te implementeren, krijgen ontwikkelteams de mogelijkheid om hoogwaardige code te maken en aansprakelijkheid te verminderen.
De mate waarin een team deze nieuwe gewoonten overneemt als er geen normen zijn die naleving vereisen, hangt af van de erkenning door het bedrijf van de game-change die ze met zich meebrengen. Het toepassen van deze praktijken, of een product nu veiligheids- of beveiligingskritiek is, kan een verschil maken in de onderhoudbaarheid en robuustheid van code. Schone code vereenvoudigt de toevoeging van nieuwe functies, vereenvoudigt het productonderhoud en houdt de kosten en planning tot een minimum beperkt - allemaal kenmerken die de ROI van uw bedrijf verbeteren.
Of een product nu van cruciaal belang is voor de veiligheid of niet, dit is zeker een uitkomst die alleen maar gunstig kan zijn voor het ontwikkelingsteam.
>> Dit artikel is oorspronkelijk gepubliceerd op onze zustersite, EDN.
Ingebed
- Zijn tekststrings een kwetsbaarheid in embedded software?
- SOAFEE-architectuur voor embedded edge maakt softwaregedefinieerde auto's mogelijk
- Pixus:nieuwe dikke en robuuste frontplaten voor embedded boards
- Kontron:nieuwe embedded computerstandaard COM HPC
- congatec presenteert 10 nieuwe high-end modules voor embedded edge computing
- GE Digital lanceert nieuwe software voor vermogensbeheer
- Niet slecht zijn in het aanleren van nieuwe software
- Softwarerisico's:Open source beveiligen in IoT
- Drie stappen naar het beveiligen van softwaretoeleveringsketens
- Saelig lanceert nieuwe embedded pc gemaakt door Amplicon
- DevOps gebruiken om uitdagingen op het gebied van embedded software aan te pakken