


Embedded C begrijpen:wat zijn structuren?
Na het introduceren van structuren, gaan we kijken naar enkele van de belangrijke toepassingen van dit krachtige data-object. Vervolgens zullen we de C-taalsyntaxis onderzoeken om een structuur te declareren. Ten slotte zullen we kort de vereiste voor gegevensuitlijning introduceren. We zullen zien dat we de grootte van een structuur kunnen verkleinen door simpelweg de volgorde van de leden te herschikken.
Dit artikel geeft wat basisinformatie over structuren in embedded C-programmering.
Na het introduceren van structuren, zullen we enkele van de belangrijke toepassingen van dit krachtige data-object bekijken. Vervolgens zullen we de C-taalsyntaxis onderzoeken om een structuur te declareren. Ten slotte zullen we kort de vereiste voor gegevensuitlijning introduceren. We zullen zien dat we de grootte van een structuur kunnen verkleinen door simpelweg de volgorde van de leden te wijzigen.
Structuren
Een aantal variabelen van hetzelfde type die logisch aan elkaar gerelateerd zijn, kunnen als een array worden gegroepeerd. Door aan een groep te werken in plaats van aan een verzameling onafhankelijke variabelen, kunnen we de gegevens ordenen en gemakkelijker gebruiken. We kunnen bijvoorbeeld de volgende array definiëren om de laatste 50 samples op te slaan van een ADC die een spraakinvoer digitaliseert:
uint16_t stem[50]; Merk op dat uint16_t is een unsigned integer type met een breedte van precies 16 bits. Dit is gedefinieerd in de C-standaardbibliotheek stdint.h , die gegevenstypen met een specifieke bitlengte biedt, onafhankelijk van de systeemspecificaties.
Arrays kunnen worden gebruikt om een aantal variabelen te groeperen die van hetzelfde gegevenstype zijn. Wat als er een verband is tussen variabelen van verschillende gegevens typen? Kunnen we deze variabelen als groep in ons programma behandelen? Stel bijvoorbeeld dat we de bemonsteringsfrequentie moeten specificeren van de ADC die de stem genereert array hierboven. We kunnen een float-variabele definiëren om de samplefrequentie op te slaan:
float sample_rate; Hoewel de variabelen stem en sample_rate aan elkaar gerelateerd zijn, worden ze gedefinieerd als twee onafhankelijke variabelen. Om deze twee variabelen met elkaar te associëren, kunnen we een krachtige dataconstructie van de C-taal gebruiken, een structuur genaamd. Structuren stellen ons in staat om verschillende datatypes te groeperen en ze te behandelen als één enkel data-object. Een structuur kan verschillende soorten variabelen bevatten, zoals andere structuren, verwijzingen naar functies, verwijzingen naar structuren, enz. Voor het stemvoorbeeld kunnen we de volgende structuur gebruiken:
struct record { uint16_t voice[50]; float sample_rate;}; In dit geval hebben we een structuur genaamd record die twee verschillende leden of velden heeft:het eerste lid is een array van uint16_t elementen, en het tweede lid is een variabele van het type float. De syntaxis begint met het trefwoord struct . Het woord na het struct-sleutelwoord is een optionele naam die wordt gebruikt om later naar de structuur te verwijzen. We zullen andere details over het definiëren en gebruiken van structuren in de rest van het artikel bespreken.
Waarom zijn structuren belangrijk?
Het bovenstaande voorbeeld wijst op een belangrijke toepassing van structuren, d.w.z. het definiëren van toepassingsafhankelijke gegevensobjecten die individuele variabelen van verschillende typen met elkaar kunnen associëren. Dit leidt niet alleen tot een efficiënte manier om de gegevens te manipuleren, maar stelt ons ook in staat om gespecialiseerde structuren te implementeren die gegevensstructuren worden genoemd.
Gegevensstructuren kunnen worden gebruikt voor verschillende toepassingen, zoals berichtenuitwisseling tussen twee embedded systemen en het opslaan van gegevens die zijn verzameld van een sensor op niet-aangrenzende geheugenlocaties.
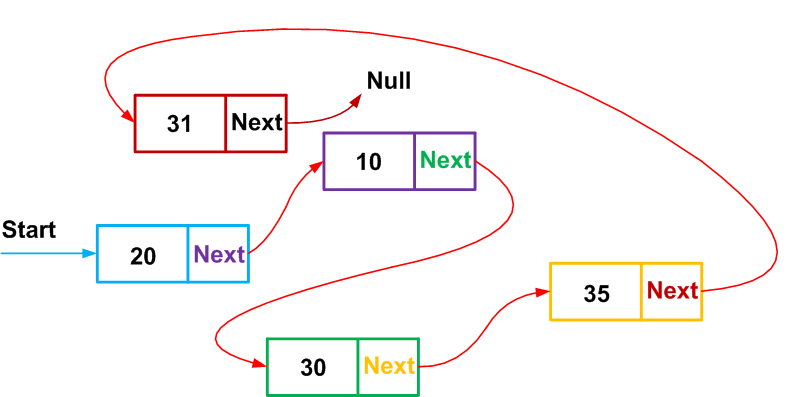
Figuur 1. Structuren kunnen worden gebruikt om een gekoppelde lijst te implementeren.
Bovendien zijn structuren nuttige data-objecten wanneer het programma toegang moet hebben tot de registers van een geheugen-mapped microcontroller-randapparaat. We zullen in het volgende artikel naar structuurtoepassingen kijken.
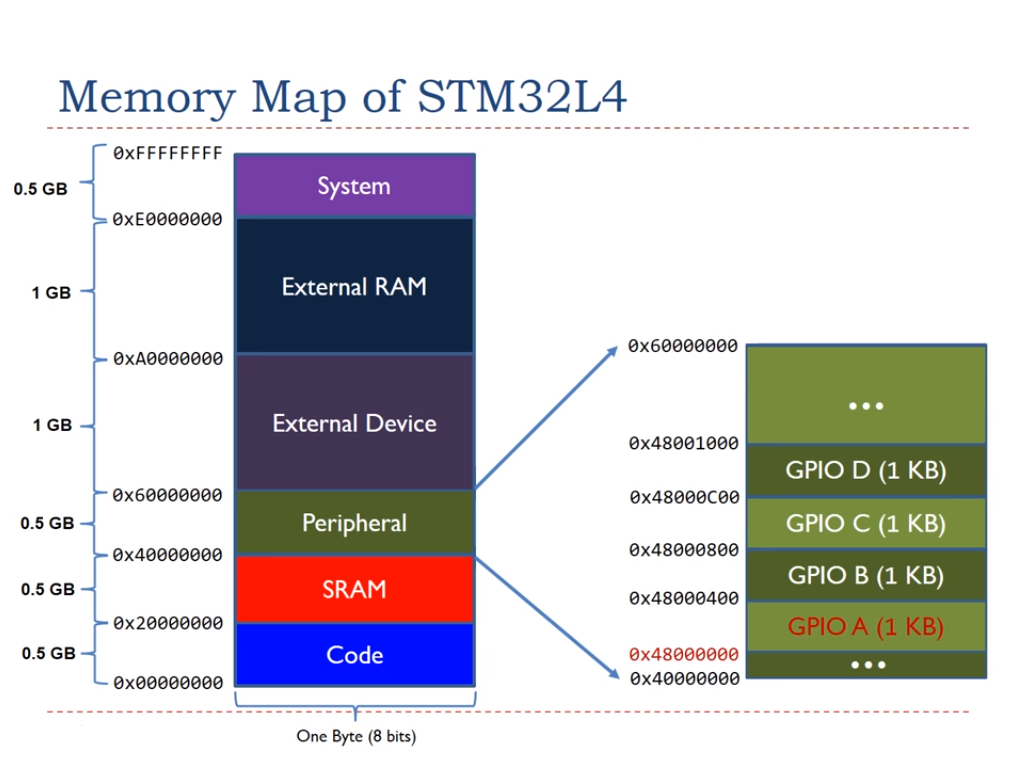
Figuur 2. Geheugenkaart van een STM32 MCU. Afbeelding met dank aan Embedded Systems met ARM.
Een structuur declareren
Om structuren te gebruiken, moeten we eerst een structuursjabloon specificeren. Bekijk de voorbeeldcode hieronder:
struct record { uint16_t voice[4]; float sample_rate;}; Dit specificeert een lay-out of sjabloon voor het maken van toekomstige variabelen van dit type. Deze sjabloon bevat een reeks uint16_t en een variabele van het type float. De naam van de sjabloon is record , en dit komt na het zoekwoord struct . Het is de moeite waard om te vermelden dat er geen geheugentoewijzing is voor het opslaan van een structuursjabloon. Geheugentoewijzing vindt pas plaats nadat een op deze lay-out gebaseerde structuurvariabele is gedefinieerd. De volgende code declareert de variabele mic1 van de bovenstaande sjabloon:
struct record mic1; Nu wordt een gedeelte van het geheugen toegewezen voor de variabele mic1 . Het heeft ruimte om de vier uint16_t . op te slaan elementen van de array en één float-variabele.
De leden van een structuur zijn toegankelijk met behulp van de lidoperator (.). De volgende code wijst bijvoorbeeld 100 toe aan het eerste element van de array en kopieert de waarde van sample_rate naar de fs variabele (die van het type float moet zijn).
mic1.voice[0]=100;fs=mic1.sample_rate; Andere manieren om een structuur te declareren
In de vorige paragraaf hebben we gekeken naar een manier om structuren te declareren. De C-taal ondersteunt enkele andere formaten die in deze sectie zullen worden besproken. Je zult waarschijnlijk in al je programma's bij één formaat blijven, maar bekend zijn met de andere kan soms handig zijn.
De algemene syntaxis voor het declareren van de sjabloon van een structuur is:
struct tag_name { type_1 member_1; type_2 lid_2; … type_n member_n;} variabelenaam; De tag_name en variabelenaam zijn optionele identifiers. Meestal zien we ten minste één van deze twee ID's, maar er zijn gevallen waarin we ze allebei kunnen verwijderen.
Syntaxis 1: Wanneer beide tag_name en variabelenaam aanwezig zijn, definiëren we de structuurvariabele net na de sjabloon. Met behulp van deze syntaxis kunnen we het vorige voorbeeld als volgt herschrijven:
struct record { uint16_t voice[4]; float sample_rate;} mic1; Als we nu een andere variabele moeten definiëren (mic2 ), kunnen we schrijven
struct record mic2; Syntaxis 2: Alleen variable_name inbegrepen. Met behulp van deze syntaxis kunnen we het voorbeeld in de vorige sectie als volgt herschrijven:
struct { uint16_t voice[4]; float sample_rate;} mic1; In dit geval moeten we al onze variabelen net na de sjabloon definiëren en kunnen we later in ons programma geen andere variabele definiëren (omdat de sjabloon geen naam heeft en we er later niet naar kunnen verwijzen).
Syntaxis 3: In dit geval is er geen tag_name of variabelenaam . Op deze manier gedefinieerde structuursjablonen worden anonieme structuren genoemd. Een anonieme structuur kan worden gedefinieerd binnen een andere structuur of unie. Een voorbeeld wordt hieronder gegeven:
struct test { // Anonieme structuur struct { float f; teken een; };} test_var; Om toegang te krijgen tot de leden van de bovenstaande anonieme structuur, kunnen we de ledenoperator (.) gebruiken. De volgende code wijst 1.2 toe aan het lid f .
test_var.f=1.2; Omdat de structuur anoniem is, hebben we toegang tot de leden door de ledenoperator slechts één keer te gebruiken. Als het een naam had zoals in het volgende voorbeeld, zouden we de operator member twee keer moeten gebruiken:
struct-test { struct { float f; teken een; } genest;} test_var; In dit geval moeten we de volgende code gebruiken om 1.2 toe te wijzen aan f :
test_var.nested.f=1.2; Zoals je kunt zien, kunnen anonieme structuren de code leesbaarder en minder uitgebreid maken. Het is ook mogelijk om het sleutelwoord typedef samen met een structuur te gebruiken om een nieuw gegevenstype te definiëren. We zullen deze methode in een toekomstig artikel bekijken.
Geheugenindeling voor een constructie
De C-standaard garandeert dat de leden van een constructie achter elkaar in het geheugen worden gelokaliseerd in de volgorde waarin de leden binnen de constructie worden gedeclareerd. Het geheugenadres van het eerste lid zal hetzelfde zijn als het adres van de structuur zelf. Beschouw het volgende voorbeeld:
struct Test2{ uint8_t c; uint32_t d; uint8_t e; uint16_t f;} MyStruct; Er worden vier geheugenlocaties toegewezen om de variabelen c, d, e en f op te slaan. De volgorde van geheugenlocaties komt overeen met die van het declareren van de leden:de locatie voor c heeft het laagste adres, dan verschijnen d, e en ten slotte f. Hoeveel bytes hebben we nodig om deze structuur op te slaan? Gezien de grootte van de variabelen, weten we dat er minimaal 1+4+1+2=8 bytes nodig zijn om deze structuur op te slaan. Als we deze code echter compileren voor een 32-bits machine, zien we verrassend genoeg dat de grootte van MyStruct is 12 bytes in plaats van 8! Dit komt door het feit dat een compiler bepaalde beperkingen heeft bij het toewijzen van geheugen voor verschillende leden van een structuur. Een 32-bits geheel getal kan bijvoorbeeld alleen worden opgeslagen op geheugenlocaties waarvan het adres deelbaar is door vier. Dergelijke beperkingen, die gegevensuitlijningsvereisten worden genoemd, worden geïmplementeerd om de processor efficiënter toegang te geven tot variabelen. Gegevensuitlijning leidt tot wat verspilde ruimte (of opvulling) in de geheugenlay-out. Dit onderwerp wordt hier alleen geïntroduceerd; we zullen de details doornemen in het volgende artikel van deze serie.
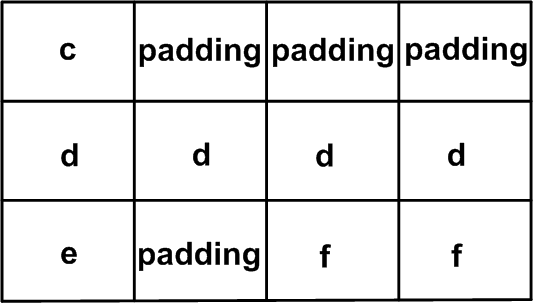
Figuur 3. Gegevensuitlijning leidt tot wat verspilde ruimte (of opvulling) in de geheugenlay-out.
Als we ons bewust zijn van de vereisten voor gegevensuitlijning, kunnen we mogelijk de volgorde van leden binnen een structuur herschikken en het geheugengebruik efficiënter maken. Als we bijvoorbeeld de bovenstaande structuur herschrijven zoals hieronder aangegeven, zal de grootte afnemen tot 8 bytes op een 32-bits machine.
struct Test2{ uint32_t d; uint16_t f; uint8_t c; uint8_t e;} MyStruct; Voor een embedded systeem met beperkte geheugen is het een aanzienlijke besparing om de grootte van een data-object te verminderen van 12 bytes naar 8 bytes, vooral wanneer een programma veel van deze data-objecten nodig heeft.
Het volgende artikel gaat dieper in op gegevensuitlijning en onderzoekt enkele voorbeelden van het gebruik van structuren in embedded systemen.
Samenvatting
- Met structuren kunnen we toepassingsafhankelijke gegevensobjecten definiëren die individuele variabelen van verschillende typen met elkaar kunnen associëren. Dit leidt tot een efficiënte manier om de gegevens te manipuleren.
- Gespecialiseerde structuren, datastructuren genaamd, kunnen worden gebruikt voor verschillende toepassingen, zoals berichtenuitwisseling tussen twee embedded systemen en het opslaan van gegevens die zijn verzameld van een sensor op niet-aangrenzende geheugenlocaties.
- Structuren zijn handig wanneer we toegang moeten hebben tot de registers van een geheugen-mapped microcontroller-randapparaat.
- Misschien kunnen we het geheugengebruik efficiënter maken door de volgorde van de leden binnen een structuur te herschikken.
Ga naar deze pagina om een volledige lijst van mijn artikelen te zien.
Ingebed
- Wat zijn vuurvaste metalen?
- Wat zijn tweevoudige scharnieren?
- Wat zijn dekschroeven?
- Wat zijn veerbekrachtigde afdichtingen?
- Wat zijn houtschroeven?
- Wat zijn staallegeringen?
- Wat moet ik doen met de gegevens?!
- Java - Gegevensstructuren
- Wat is IIoT?
- Wat zijn onderhoudsgegevens?
- Houtbewerking begrijpen